Spark机器学习实战(二)电影评分数据获取与可视化
这个系列要完成的是一个电影服务提供网站的大数据分析,包括推荐系统等等。
一个机器学习系统的主要步骤为:数据获取与存储 => 数据清理与转换 => 模型训练与测试回路 => 模型部署与整合 => 模型监控与反馈
在这一部分中,我们做的就是机器学习的前两步,首先获取数据(数据来源为MovieLens数据集),之后对数据作简要分析并可视化数据,为进一步的工作做准备。
文章中列出了关键代码,完整代码见我的github repository,这篇文章的代码在
chapter03/movielens_analysis.py
第1步:数据集下载
我们使用的是MovieLens 100k数据集,它包含了100000条用户对电影的点评(1分到5分)。数据集主要包含这么几个部分。
用户列表u.user,包含用户年龄,性别,职业,邮编信息
1|24|M|technician|85711
2|53|F|other|94043
3|23|M|writer|32067
4|24|M|technician|43537
...
电影列表u.item,包含了电影的基本信息
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
2|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0
...
点评列表u.data,包含了用户编号,电影编号,评分,时间戳
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
数据集不大也不小,非常适合作机器学习算法,而且本地运行也非常快速。
我们把数据集下载下来并解压,把解压路径放在变量PATH中。
第2步:用户数值统计
我们使用最基本的RDD操作,来对u.user数据的做一些统计,包括:用户人数,性别数量,职业数量,不同邮编数量,非常简单,看了下面的代码就可以理解。
注意,以下代码为Python代码,为什么?因为Python Spark尽管运行速度不及Scala,然而数据可视化非常方便,因此这里用python。
运行代码的方式有两种:
- 使用Python Spark交互式编程,那么可以省去SparkContext的实例化
$ $SPARK_HOME/bin/pyspark
- 编写python代码,并使用spark-submit工具
$ $SPARK_HOME/bin/spark-submit myapp.py
直接上代码:
from pyspark import SparkContext
import matplotlib.pyplot as plt
import numpy as np
sc = SparkContext("local", "Movielens Analysis")
sc.setLogLevel("ERROR")
PATH = "..."
## 1. Do some statistics
user_data = sc.textFile("%s/ml-100k/u.user" % PATH)
user_fields = user_data.map(lambda line: line.split('|'))
num_users = user_fields.count()
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count()
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count()
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count()
print("Users:%d, genders:%d, occupations:%d, ZIP codes:%d"
%(num_users, num_genders, num_occupations, num_zipcodes))
稍作解释,首先读取数据集,随后从对应位置取出相应数据,如职业位于第4栏,distinct()可以去除重复数据,最后的count()为行为操作,返回不重复的职业数量。
运行后结果为:
Users:943, genders:2, occupations:21, ZIP codes:795
意味着我们一共有来自21种不同职业的943位用户对电影作了评价
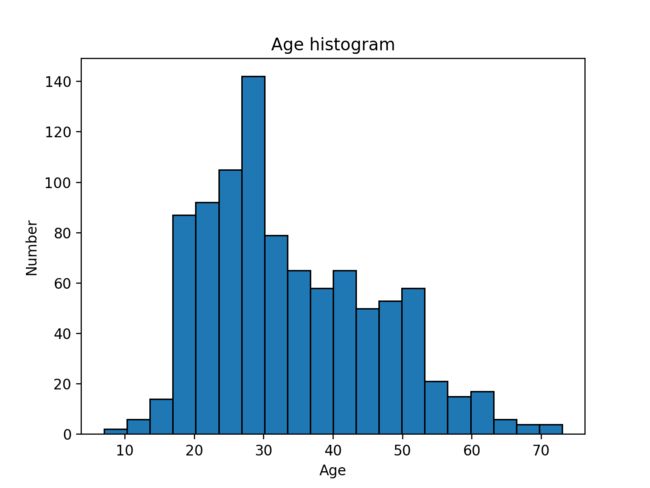
第3步:用户年龄分布直方图
数据可视化是数据分析中很重要的一部分,先对数据集可视化可以让我们对数据集有一个完整的把握。那么数据可视化一个比较方便的Python库就是matplotlib。本文不会讲解该库的用法,官方文档中有不少例子很方便学习。
## 2. Draw histgrams of age
ages = user_fields.map(lambda fields: int(fields[1])).collect()
fig1 = plt.figure()
plt.hist(ages, bins = 20, edgecolor='black')
plt.title("Age histogram")
plt.xlabel("Age")
plt.ylabel("Number")
当然这种作图方式不是很好,因为ages包含了所有年龄信息,而直方图统计是交给Python执行的,最好的方式是把相同年龄的人的数量统计交给reduceByKey(),countByKey()这类函数。
作图结果如下:
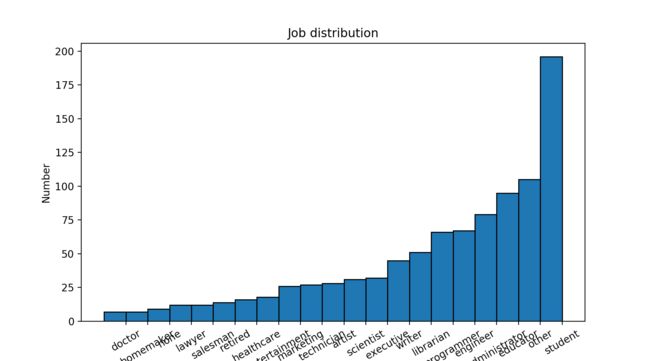
第4步:职业分布
大致上与年龄分布的处理方式是一致的,只是横坐标不是数据而是职业名称,而且需要提前作一下排序。
## 3. Draw job distribution
occupations = user_fields.map(lambda
fields: (fields[3], 1)).reduceByKey(lambda
x, y: x + y).sortBy(lambda x: x[1]).collect()
fig2 = plt.figure(figsize=(9, 5), dpi=100)
x_axis = [occu[0] for occu in occupations]
y_axis = [occu[1] for occu in occupations]
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + 0.5)
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis, width, edgecolor='black')
plt.xticks(rotation=30)
plt.ylabel("Number")
plt.title("Job distribution")
主要看RDD操作,首先把职业map成(occupation, 1)的键值对,随后用reduceByKey()可以实现不同职业数量的求和,再对数量进行排序sortBy(),最后行为操作collect()取出数据。
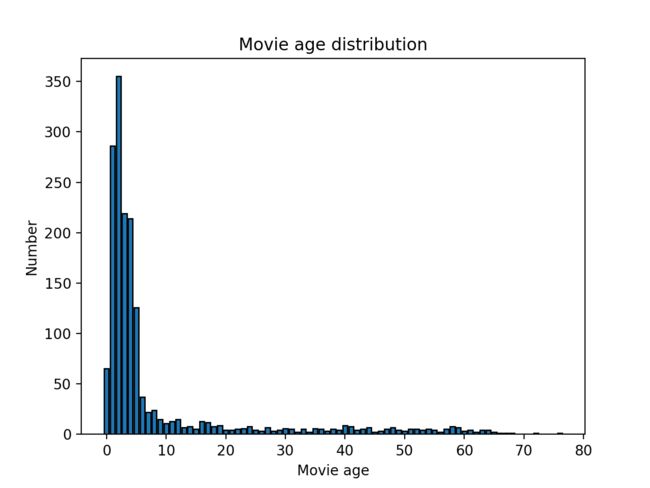
第5步:其他各种可视化与统计
电影年龄统计,统计值为距离1998年的距离,即1990年的电影计为8岁。
用户评分统计,统计了最高分,最低分,中位数,平均数,平均每人评分电影数量,以及平均每部电影评价数量。
Min rating:1, max rating:5, average rating:3.53, median rating:4
Average # of rating per user: 106.0
Average # of rating per movie: 59.5
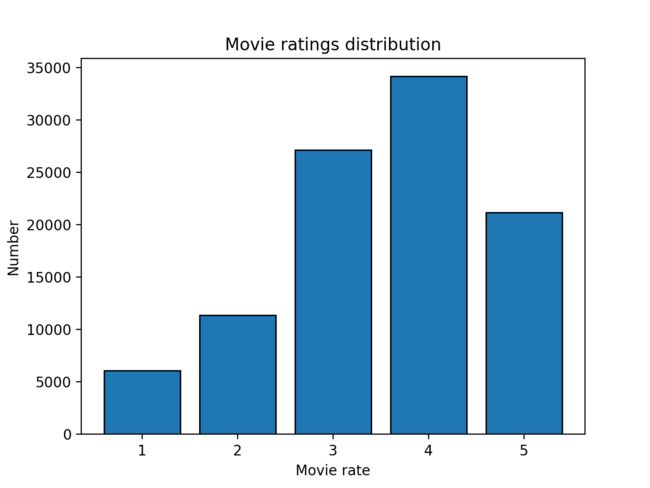
之后还有电影评分分布,可以看到4分的评分是最多的。
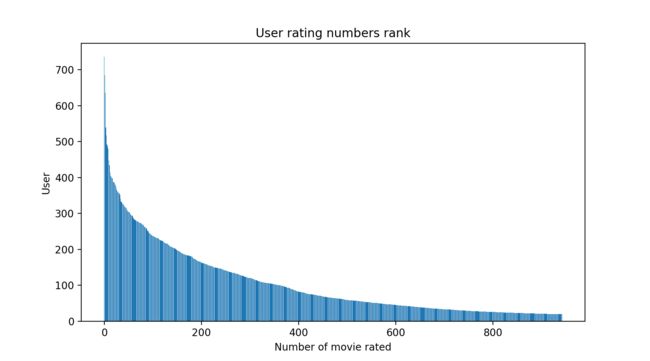
用户评价电影数量排行,数据有点多,显示得不是很好。