正文之前
2013年ACL的一篇文章,内容很容易理解,简洁干练,我是真有点喜欢了,系统类的文章实在是太难读了!!
Pilehvar M T, Jurgens D, Navigli R. Align, disambiguate and walk: A unified approach for measuring semantic similarity[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2013, 1: 1341-1351.
正文
摘要
Semantic similarity is an essential component of many Natural Language Processing applications. However, prior methods for computing semantic similarity often operate at different levels, e.g., single words or entire documents, which requires adapting the method for each data type. We present a unified approach to semantic similarity that operates at multiple levels, all the way from comparing word senses to comparing text documents. Our method leverages a common probabilistic representation over word senses in order to compare different types of linguistic data. This unified representation shows state-ofthe-art performance on three tasks: semantic textual similarity, word similarity, and word sense coarsening.
语义相似性是许多自然语言处理应用程序的重要组成部分。然而,用于计算语义相似性的现有方法通常在不同级别操作,例如单个单词或整个文档,这需要针对每种数据类型调整方法。我们提出了一种统一的语义相似性方法,可以在多个层面上进行操作,从比较词义到比较文本文档。我们的方法利用对词义的共同概率表示来比较不同类型的语言数据。这种统一的表示显示了三个任务的最先进的表现:语义文本相似性,单词相似性和词义粗化。
1 Introduction
1简介
Semantic similarity is a core technique for many topics in Natural Language Processing such as Textual Entailment (Berant et al., 2012), Semantic Role Labeling (Furstenau and Lapata, 2012), ¨ and Question Answering (Surdeanu et al., 2011). For example, textual similarity enables relevant documents to be identified for information retrieval (Hliaoutakis et al., 2006), while identifying similar words enables tasks such as paraphrasing (Glickman and Dagan, 2003), lexical substitution (McCarthy and Navigli, 2009), lexical simplification (Biran et al., 2011), and Web search result clustering (Di Marco and Navigli, 2013).
语义相似性是自然语言处理中许多主题的核心技术,如文本蕴涵(Berant等,2012),语义角色标签(Furstenau和Lapata,2012),¨和问题回答(Surdeanu等,2011)。例如,文本相似性使得相关文档能够被识别用于信息检索(Hliaoutakis等,2006),而识别相似词则可以实现诸如释义(Glickman和Dagan,2003),词汇替换(McCarthy和Navigli,2009)等任务,词汇简化(Biran et al。,2011)和Web搜索结果聚类(Di Marco和Navigli,2013)。
Approaches to semantic similarity have often operated at separate levels: methods for word similarity are rarely applied to documents or even single sentences (Budanitsky and Hirst, 2006; Radinsky et al., 2011; Halawi et al., 2012), while document-based similarity methods require more linguistic features, which often makes them inapplicable at the word or microtext level (Salton et al., 1975; Maguitman et al., 2005; Elsayed et al., 2008; Turney and Pantel, 2010). Despite the potential advantages, few approaches to semantic similarity operate at the sense level due to the challenge in sense-tagging text (Navigli, 2009); for example, none of the top four systems in the recent SemEval-2012 task on textual similarity compared semantic representations that incorporated sense information (Agirre et al., 2012).
语义相似性的方法通常在不同的层面上运作:词语相似性的方法很少应用于文档甚至单个句子(Budanitsky和Hirst,2006; Radinsky等,2011; Halawi等,2012),而基于文档的相似性方法需要更多的语言特征,这通常使得它们不适用于单词或缩微文本级别(Salton等,1975; Maguitman等,2005; Elsayed等,2008; Turney和Pantel,2010)。尽管具有潜在的优势,但由于语义标记文本的挑战,很少有语义相似性方法在语义层面上运作(Navigli,2009);例如,最近SemEval-2012关于文本相似性的任务中的前四个系统都没有比较包含语义信息的语义表示(Agirre等,2012)。
We propose a unified approach to semantic similarity across multiple representation levels from senses to documents, which offers two significant advantages. First, the method is applicable independently of the input type, which enables meaningful similarity comparisons across different scales of text or lexical levels. Second, by operating at the sense level, a unified approach is able to identify the semantic similarities that exist independently of the text’s lexical forms and any semantic ambiguity therein. For example, consider the sentences:
我们提出了从语义到文档的多个表示级别的语义相似性的统一方法,这提供了两个显着的优点。首先,该方法可独立于输入类型应用,这使得能够在不同的文本或词汇级别上进行有语义的相似性比较。其次,通过在语义层面上操作,统一的方法能够识别独立于文本的词汇形式和其中的任何语义歧义而存在的语义相似性。例如,考虑句子:
t1. A manager fired the worker.
T1。一位经理解雇了这名工人。t2. An employee was terminated from work by his boss.
T2。一名员工被老板解雇了。
A surface-based approach would label the sentences as dissimilar due to the minimal lexical overlap. However, a sense-based representation enables detection of the similarity between the meanings of the words, e.g., fire and terminate. Indeed, an accurate, sense-based representation is essential for cases where different words are used to convey the same meaning.
由于最小的词汇重叠,基于表面的方法会将句子标记为不相似。然而,基于语义的表示使得能够检测单词的含义之间的相似性,例如,开火和终止。实际上,对于使用不同词语来表达相同含义的情况,准确的,基于语义的表示是必不可少的。
The contributions of this paper are threefold. First, we propose a new unified representation of the meaning of an arbitrarily-sized piece of text, referred to as a lexical item, using a sense-based probability distribution. Second, we propose a novel alignment-based method for word sense disambiguation during semantic comparison. Third, we demonstrate that this single representation can achieve state-of-the-art performance on three similarity tasks, each operating at a different lexical level: (1) surpassing the highest scores on the SemEval-2012 task on textual similarity (Agirre et al., 2012) that compares sentences, (2) achieving a near-perfect performance on the TOEFL synonym selection task proposed by Landauer and Dumais (1997), which measures word pair similarity, and also obtaining state-of-the-art performance in terms of the correlation with human judgments on the RG-65 dataset (Rubenstein and Goodenough, 1965), and finally (3) surpassing the performance of Snow et al. (2007) in a sensecoarsening task that measures sense similarity
本文的贡献有三个方面。首先,我们使用基于语义的概率分布提出一种新的统一表示,其中任意大小的文本的语义被称为词汇项。其次,我们提出了一种新的基于对齐的语义比较中的词义消歧方法。第三,我们证明这种单一表示可以在三个相似性任务上实现最先进的性能,每个任务在不同的词汇级别上运行:(1)超过SemEval-2012任务中关于文本相似性的最高分(Agirre et比较句子,(2)在Landauer和Dumais(1997)提出的托福同义词选择任务中实现近乎完美的表现,该任务测量词对相似性,并且还获得最先进的表现就RG-65数据集(Rubenstein和Goodenough,1965)与人类判断的相关性而言,最后(3)超越了Snow等人的表现。 (2007)在一个测量语义相似性的语义训练任务中
2 A Unified Semantic Representation
2 统一语义表示
We propose a representation of any lexical item as a distribution over a set of word senses, referred to as the item’s semantic signature. We begin with a formal description of the representation at the sense level (Section 2.1). Following this, we describe our alignment-based disambiguation algorithm which enables us to produce sense-based semantic signatures for those lexical items (e.g., words or sentences) which are not sense annotated (Section 2.2). Finally, we propose three methods for comparing these signatures (Section 2.3). As our sense inventory, we use WordNet 3.0 (Fellbaum, 1998).
我们建议将任何词汇项目表示为一组词义的分布,称为项目的语义签名。我们首先对语义层面的表示进行正式描述(第2.1节)。接下来,我们描述了基于对齐的消歧算法,该算法使我们能够为那些没有语义注释的词汇项(例如,单词或句子)产生基于语义的语义签名(第2.2节)。最后,我们提出了三种比较这些签名的方法(第2.3节)。作为我们的语义库存,我们使用WordNet 3.0(Fellbaum,1998)。
2.1 Semantic Signatures
2.1语义签名
The WordNet ontology provides a rich network structure of semantic relatedness, connecting senses directly with their hypernyms, and providing information on semantically similar senses by virtue of their nearby locality in the network. Given a particular node (sense) in the network, repeated random walks beginning at that node will produce a frequency distribution over the nodes in the graph visited during the walk. To extend beyond a single sense, the random walk may be initialized and restarted from a set of senses (seed nodes), rather than just one; this multi-seed walk produces a multinomial distribution over all the senses in WordNet with higher probability assigned to senses that are frequently visited from the seeds. Prior work has demonstrated that multinomials generated from random walks over WordNet can be successfully applied to linguistic tasks such as word similarity (Hughes and Ramage, 2007; Agirre et al., 2009), paraphrase recognition, textual entailment (Ramage et al., 2009), and pseudoword generation (Pilehvar and Navigli, 2013).
WordNet本体提供了丰富的语义相关性网络结构,将语义直接与其上位词联系起来,并凭借其在网络中的附近位置提供语义相似的语义信息。给定网络中的特定节点(语义),从该节点开始的重复随机游走将在步行期间访问的图中的节点上产生频率分布。为了超越单一语义,可以从一组语义(种子节点)初始化并重新启动随机游走,而不仅仅是一个;这种多种子步行产生了WordNet中所有语义的多项分布,并且更高的概率分配给经常从种子访问的语义。之前的工作表明,通过随意漫游WordNet生成的多项式可以成功应用于语言任务,如单词相似性(Hughes和Ramage,2007; Agirre等,2009),释义识别,文本蕴涵(Ramage等,2009) )和伪词生成(Pilehvar和Navigli,2013)。
Formally, we define the semantic signature of a lexical item as the multinomial distribution generated from the random walks over WordNet 3.0 where the set of seed nodes is the set of senses present in the item. This representation encompasses both when the item is itself a single sense and when the item is a sense-tagged sentence.
在形式上,我们将词汇项的语义签名定义为从WordNet 3.0上的随机遍历生成的多项分布,其中种子节点集是项中存在的一组语义。该表示包括当项目本身是单一语义时以及该项目是有语义标记的句子时。
To construct each semantic signature, we use the iterative method for calculating topic-sensitive PageRank (Haveliwala, 2002). Let M be the adjacency matrix for the WordNet network, where edges connect senses according to the relations defined in WordNet (e.g., hypernymy and meronymy). We further enrich M by connecting a sense with all the other senses that appear in its disambiguated gloss_1. Let ~v(0) denote the probability distribution for the starting location of the random walker in the network. Given the set of senses S in a lexical item, the probability mass of ~v(0) is uniformly distributed across the senses si ∈ S, with the mass for all sj ∈ S set to zero. The PageRank may then be computed using:
为了构造每个语义签名,我们使用迭代方法来计算主题敏感的PageRank(Haveliwala,2002)。 设M是WordNet网络的邻接矩阵,其中边根据WordNet中定义的关系(例如,hypernymy和meronymy)连接语义。 我们通过将一种语义与其消除歧义的注解中出现的所有其他语义联系起来进一步丰富了M。令~v(0)表示随机游走在网络中的起始位置的概率分布。 给定词汇项中的一组语义S,概率质量〜v(0)均匀分布在语义si∈S上,所有sj /∈ S的质量设置为零。 然后可以使用以下公式计算PageRank:
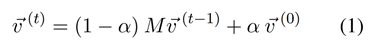
where at each iteration the random walker may jump to any node si ∈ S with probability α/|S|. We follow standard convention and set α to 0.15. We repeat the operation in Eq. 1 for 30 iterations, which is sufficient for the distribution to converge. The resulting probability vector ~v(t) is the semantic signature of the lexical item, as it has aggregated its senses’ similarities over the entire graph. For our semantic signatures we used the UKB2 off-the-shelf implementation of topic-sensitive PageRank.
在每次迭代中,随机游走者可以以概率α / | S |跳转到任何节点si∈S。 我们遵循标准惯例并将α设置为0.15。 我们在方程式中重复操作。 1次进行30次迭代,这足以使分布收敛。 得到的概率向量~v(t)是词汇项的语义签名,因为它在整个图上聚合了它的语义相似性。 对于我们的语义签名,我们使用了UKB2现成的topic-Sensitive PageRank实现。
2.2 Alignment-Based Disambiguation
2.2基于对齐的消歧
Commonly, semantic comparisons are between word pairs or sentence pairs that do not have their lexical content sense-annotated, despite the potential utility of sense annotation in making semantic comparisons. However, traditional forms of word sense disambiguation are difficult for short texts and single words because little or no contextual information is present to perform the disambiguation task. Therefore, we propose a novel alignment-based sense disambiguation that leverages the content of the paired item in order to disambiguate each element. Leveraging the paired item enables our approach to disambiguate where traditional sense disambiguation methods can not due to insufficient context.
通常,语义比较是在没有词汇内容语义注释的词对或句子对之间进行的,尽管语义注释在进行语义比较时具有潜在的效用。然而,对于短文本和单个单词来说,传统形式的词义消歧是困难的,因为很少或没有上下文信息来执行消歧任务。因此,我们提出了一种新颖的基于对齐的语义消歧,它利用配对项的内容来消除每个元素的歧义。利用配对项使我们的方法能够消除传统语义消歧方法因上下文不足而无法消除歧义的方法。

We view sense disambiguation as an alignment problem. Given two arbitrarily ordered texts, we seek the semantic alignment that maximizes the similarity of the senses of the context words in both texts. To find this maximum we use an alignment procedure which, for each word type wi in item T1, assigns wi to the sense that has the maximal similarity to any sense of the word types in the compared text T2. Algorithm 1 formalizes the alignment process, which produces a sense disambiguated representation as a result. Senses are compared in terms of their semantic signatures, denoted as function R. We consider multiple definitions of R, defined later in Section 2.3.
我们将语义消歧视为对齐问题。给定两个任意排序的文本,我们寻求语义对齐,以最大化两个文本中的上下文词的语义的相似性。为了找到这个最大值,我们使用对齐程序,对于项目T1中的每个单词类型wi,将wi分配给与比较文本T2中的单词类型的任何语义具有最大相似性的语义。算法1将对齐过程形式化,从而产生有语义的消歧表示。将语义的语义签名进行比较,表示为函数R. 我们考虑R的多个定义,稍后在2.3节中定义。

As a part of the disambiguation procedure, we leverage the one sense per discourse heuristic of Yarowsky (1995); given all the word types in two compared lexical items, each type is assigned a single sense, even if it is used multiple times. Additionally, if the same word type appears in both sentences, both will always be mapped to the same sense. Although such a sense assignment is potentially incorrect, assigning both types to the same sense results in a representation that does no worse than a surface-level comparison.
作为消歧程序的一部分,我们利用Yarowsky(1995)的每个话语启发式的一种语义;给定两个比较词汇项中的所有单词类型,即使多次使用,每种类型也被赋予单一语义。另外,如果两个句子中出现相同的单词类型,则两者将始终映射到相同的语义。虽然这种语义分配可能不正确,但将两种类型分配给相同的语义会导致表示不会比表面级别比较更糟糕。
We illustrate the alignment-based disambiguation procedure using the two example sentences t1 and t2 given in Section 1. Figure 1(a) illustrates example alignments of the first sense of manager to the first two senses of the word types in sentence t2 along with the similarity of the two senses’ semantic signatures. For the senses of manager, sense manager 1-n obtains the maximal similarity value to boss1-n among all the possible pairings of the senses for the word types in sentence t2, and as a result is selected as the sense labeling for manager in sentence t1. Figure 1(b) shows the final, maximally-similar sense alignment of the word types in t1 and t2. The resulting alignment produces the following sets of senses:
我们使用第1节中给出的两个例句t1和t2来说明基于对齐的消歧程序。图1(a)示出了第一句manager与句子t2中单词类型的前两个语义的示例对齐以及两种语义的语义特征的相似性。对于manager的语义,语义manager 1-n在句子t2中的词类型的所有可能的语义配对中获得与boss1-n的最大相似度值,并且因此被选择作为句子t1中的manager的语义标记。图1(b)显示了t1和t2中单词类型的最终,最大相似的语义对齐。生成的对齐产生以下几组语义:

2.3 Semantic Signature Similarity
2.3语义签名相似度
Cosine Similarity. In order to compare semantic signatures, we adopt the Cosine similarity measure as a baseline method. The measure is computed by treating each multinomial as a vector and then calculating the normalized dot product of the two signatures’ vectors.
余弦相似度。为了比较语义签名,我们采用余弦相似性度量作为基线方法。通过将每个多项式作为向量处理,然后计算两个签名向量的归一化点积来计算度量。
However, a semantic signature is, in essence, a weighted ranking of the importance of WordNet senses for each lexical item. Given that the WordNet graph has a non-uniform structure, and also given that different lexical items may be of different sizes, the magnitudes of the probabilities obtained may differ significantly between the two multinomial distributions. Therefore, for computing the similarity of two signatures, we also consider two nonparametric methods that use the ranking of the senses, rather than their probability values, in the multinomial.
然而,语义签名实质上是WordNet语义对于每个词汇项的重要性的加权排序。鉴于WordNet图具有不均匀的结构,并且还给出不同的词汇项可能具有不同的大小,所获得的概率的大小可能在两个多项分布之间显着不同。因此,为了计算两个签名的相似性,我们还考虑了两个非参数方法,这些方法使用多项式中的语义排名而不是概率值。
Weighted Overlap. Our first measure provides a nonparametric similarity by comparing the similarity of the rankings for intersection of the sensesin both semantic signatures. However, we additionally weight the similarity such that differences in the highest ranks are penalized more than differences in lower ranks. We refer to this measure as the Weighted Overlap. Let S denote the intersection of all senses with non-zero probability in both signatures and rji denote the rank of sense si ∈ Sin signature j, where rank 1 denotes the highest rank. The sum of the two ranks r1iand r2i for a sense is then inverted, which (1) weights higher ranks more and (2) when summed, provides the maximal value when a sense has the same rank in both signatures. The un normalized weighted overlap is then calculated as P|S|i=1(r1i r2i)−1. Then, to bound the similarity value in [0, 1], we normalize the sum by its maximum value, P|S|i=1(2i)−1,which occurs when each sense has the same rank in both signatures.
加权重叠。我们的第一个度量通过比较两个语义签名中语义的交集的排名的相似性来提供非参数相似性。然而,我们另外对相似性进行加权,使得最高等级中的差异比低等级中的差异受到更多惩罚。我们将此度量称为加权重叠。设S表示在两个签名中具有非零概率的所有语义的交集,并且rji表示语义si∈Sin签名j的秩,其中秩1表示最高的k。然后反转两个等级r1和r2ifor asense的总和,其中(1)更高权重更高和(2)当求和时,当语义在两个签名中具有相同等级时提供最大值。然后将非标准化加权重叠计算为P | S | i = 1(r1i r2i)-1。然后,为了限制[0,1]中的相似度值,我们将和值归一化其最大值P | S | i = 1(2i)-1,这在每个语义在两个签名中具有相同的秩时发生。
Top-k Jaccard. Our second measure uses the ranking to identify the top-k senses in a signature, which are treated as the best representatives of the conceptual associates. We hypothesize that a specific rank ordering may be attributed to small differences in the multinomial probabilities, which can lower rank-based similarities when one of the compared orderings is perturbed due to slightly different probability values. Therefore, we consider the top-k senses as an unordered set, with equal importance in the signature. To compare two signatures, we compute the Jaccard Index of the two signatures’ sets:
Top-k Jaccard。我们的第二项措施是使用这一标准来识别签名中的top-k语义,这些语义被视为概念伙伴的最佳代表。我们假设特定的排序可能归因于多项概率中的小差异,当比较的一个比例由于略微不同的概率值而被扰动时,这可以降低基于秩的相似性。因此,我们认为top-k语义是无序集合,在签名中具有相同的重要性。为了比较两个签名,我们计算两个签名集的Jaccard索引:
where Uk denotes the set of k senses with the highest probability in the semantic signature U.
其中Uk表示在语义签名U中具有最高概率的k个语义的集合。
3 Experiment 1: Textual Similarity
3实验1:文本相似性
Measuring semantic similarity of textual items has applications in a wide variety of NLP tasks. Asour benchmark, we selected the recent SemEval2012 task on Semantic Textual Similarity (STS),which was concerned with measuring the semantic similarity of sentence pairs. The task received considerable interest by facilitating a meaningful comparison between approaches.
测量文本项的语义相似性在各种NLP任务中具有应用。在Asour基准测试中,我们选择了最近的SemEval2012语义文本相似度(STS)任务,该任务涉及测量句子对的语义相似性。通过促进方法之间有语义的比较,该任务获得了令人感兴趣的语义。
3.1 Experimental Setup
3.1实验设置
Data. We follow the experimental setup used inthe STS task (Agirre et al., 2012), which provided five test sets, two of which had accompanying training data sets for tuning system performance. Each sentence pair in the datasets was given a score from 0 to 5 (low to high similarity) by human judges, with a high inter-annotator agreement of around 0.90 when measured using the Pearson correlation coefficient. Table 1 lists the number of sentence pairs in training and test portions of each dataset
数据。我们遵循STS任务中使用的实验设置(Agirre等,2012),其提供了五个测试集,其中两个具有用于调整系统性能的伴随训练数据集。数据集中的每个句子对由人类评判者给出0到5(从低到高的相似性)的得分,当使用Pearson相关系数测量时具有约0.90的高注释器外协议。表1列出了每个数据集的训练和测试部分中的句子对数
Comparison Systems. The top-ranking participating systems in the SemEval-2012 task were generally supervised systems utilizing a variety of lexical resources and similarity measurement techniques. We compare our results against the top three systems of the 88 submissions: TLsim and TLsyn, the two systems of Sari ˇ c et al. (2012), and ´the UKP2 system (Bar et al., 2012). UKP2 utilizes ¨extensive resources among which are a Distributional Thesaurus computed on 10M dependency parsed English sentences. In addition, the system utilizes techniques such as Explicit Semantic Analysis (Gabrilovich and Markovitch, 2007) and makes use of resources such as Wiktionary and Wikipedia, a lexical substitution system based on supervised word sense disambiguation (Biemann,2013), and a statistical machine translation system. The TLsim system uses the New York Times Annotated Corpus, Wikipedia, and Google BookNgrams. The TLsyn system also uses GoogleBook Ngrams, as well as dependency parsing and named entity recognition.
比较系统。 SemEval-2012任务中排名靠前的参与系统是利用各种资源和相似性测量技术的一般监督系统。我们将我们的结果与88个提交的前三个系统进行比较:TLsim和TLsyn,Sari c等人的两个系统。 (2012)和'UKP2系统(Bar et al。,2012)。 UKP2利用了大量资源,其中包括根据10M依赖性分析英语句子计算的分布式词库。此外,该系统利用显式语义分析(Gabrilovich和Markovitch,2007)等技术,并利用维基词典和维基百科等资源,基于监督词义
后续没什么好写的,不存在阅读问题,我就不翻译了。
正文之后
溜了,看论文去了,这个文章虽然老了点,但是还是蛮有借鉴意义的说