
文/Bruce.Liu1
文章大纲
- Otter简介
1.1. 项目介绍
1.2. 项目背景
1.3. Otter原理
1.4. Otter特性- Otter安装最佳实践
2.1. 背景简介
2.2. Zookeeper部署
2.3. Otter Manager部署
2.4. Otter Node部署
2.5. Otter单向复制配置
2.6. Otter双向复制配置
2.7. Otter双活配置注意事项
1.Otter简介
1.1.项目介绍
名称:otter ['ɒtə(r)]
译意: 水獭,数据搬运工
语言: 纯java开发
定位: 基于数据库增量日志解析,准实时同步到本机房或跨机房的mysql/oracle数据库.
1.2.项目背景
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
otter第一版本可追溯到04~05年,此次外部开源的版本为第4版,开发时间从2011年7月份一直持续到现在,目前阿里巴巴B2B内部的本地/异地机房的同步需求基本全上了otte4。
1.3.Otter原理
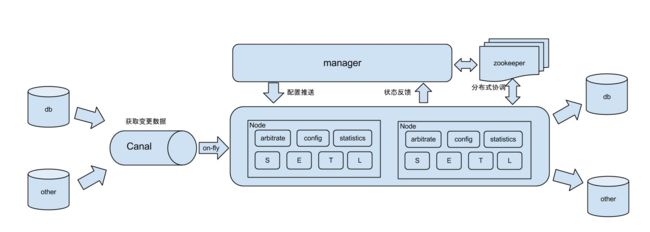
db : 数据源以及需要同步到的库
Canal : 用户获取数据库增量日志
manager : 配置同步规则设置数据源同步源等
zookeeper : 协调node进行协调工作
node : 负责任务处理处理接受到的部分同步工作
1.基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请 点击
2.典型管理系统架构,manager(web管理)+node(工作节点)
- manager运行时推送同步配置到node节点
- node节点将同步状态反馈到manager上
3.基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
1.4.Otter特性
1.异构库同步
- mysql -> mysql/oracle.(目前开源版本只支持mysql增量,目标库可以是mysql或者oracle,取决于canal的功能)
2.单机房同步 (数据库之间RTT < 1ms)
- 数据库版本升级
- 数据表迁移
- 异步二级索引
3.跨机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同不,RTT > 200ms)
- 机房容灾
4.双向同步
- 避免回环算法(通用的解决方案,支持大部分关系型数据库)
- 数据一致性算法(保证双A机房模式下,数据保证最终一致性, 亮点)
5.文件同步
- 站点镜像(进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片).
跨机房复制示意图
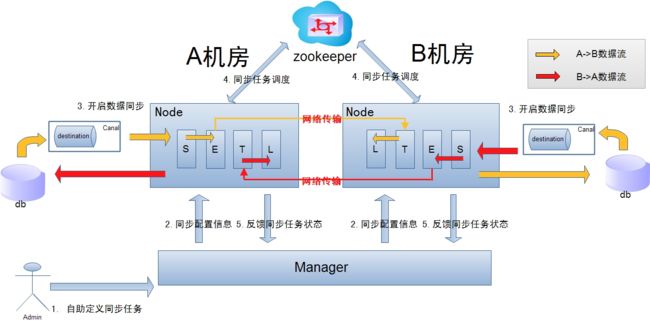
- 数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 (一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node)
- node节点可以有failover / loadBalancer. (每个机房的Node节点,都可以是集群,一台或者多台机器)
2. Otter安装最佳实践
2.1.背景简介
2.1.1.软件参考文档
参考文档:
官方文档:https://github.com/alibaba/otter
软件下载:
JDK软件下载:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Zookeeper 软件下载:http://www.apache.org/dyn/closer.cgi/zookeeper/
Otter软件下载:https://github.com/alibaba/otter/releases
Otter-mgr涉及的系统表结构:https://raw.githubusercontent.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
Otter双向同步涉及系统表结构:https://raw.github.com/alibaba/otter/master/node/deployer/src/main/resources/sql/otter-system-ddl-mysql.sql
2.1.2.系统环境介绍
系统版本
CentOS release 6.7 (Final) x86_64MySQL版本
mysql-5.7.20.-x86_64(RPM)
2.2.Zookeeper部署
2.2.1.安装JDK
# yum -y install jdk.x86_64
# java -version
java version "1.8.0_11"
Java(TM) SE Runtime Environment (build 1.8.0_11-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.11-b03, mixed mode)
2.2.2.创建用户
# useradd zookeeper
2.2.3.解压软件
# tar -zxvf zookeeper-3.4.8.tar.gz -C /data1/
# mv /data1/zookeeper-3.4.8/ /data1/zookeeper.2181.1
2.2.4.修改配置文件
initLimit
ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。
当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。syncLimit
配置follower和leader之间发送消息,请求和应答的最大时间长度。tickTime
tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。server.id=host:port1:port2
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。
host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。dataDir
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
# cd /data1/zookeeper.2181.1/conf/
# vim zoo_sample.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data1/zookeeper.2181.1
clientPort=2181
server.1=10.209.5.197:2888:3888
server.2=10.209.5.198:2888:3888
server.3=10.209.5.199:2888:3888
# mv zoo_sample.cfg zoo.cfg
2.2.5.创建myid文件
注意:在三台机器dataDir目录( /data1/zookeeper.2181.[1-3]目录)下,分别生成一个myid文件,其内容分别为1,2,3。然后分别在这三台机器上启动zk进程,这样我们便将zk集群启动了起来。
# cd /data1/zookeeper.2181.1
# echo 1 > myid
2.2.6.授权给zookeeper用户
# chown -R zookeeper:zookeeper /data1/zookeeper.2181.1/
2.2.7.启动zookeeper集群
# su - zookeeper
$ cd /data1/zookeeper.2181.1/bin
$ ./zkServer.sh start
2.2.8.链接zookeeper集群测试
$ ./bin/zkCli.sh -server 10.209.5.197:2181,10.209.5.198:2181,10.209.5.199:2181
2017-03-01 10:44:17,225 [myid:] - INFO [main-SendThread(10.209.5.197:2181):ClientCnxn$SendThread@876] - Socket connection established to 10.209.5.197/10.209.5.197:2181, initiating session
2017-03-01 10:44:17,230 [myid:] - INFO [main-SendThread(10.209.5.197:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server 10.209.5.197/10.209.5.197:2181, sessionid = 0x15a87b91d790001, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 10.209.5.197:2181,10.209.5.198:2181,10.209.5.199:2181(CONNECTED) 0]
[zk: 10.209.5.197:2181,10.209.5.198:2181,10.209.5.199:2181(CONNECTED) 0]
2.3.Otter Manager部署
2.3.1.环境准备
3.1. otter manager依赖于mysql进行配置信息的存储,所以需要预先安装mysql,并初始化otter manager的系统表结构。
- 安装MySQL
- 初始化Otter manager系统表
3.2.整个otter架构依赖了zookeeper进行多节点调度,所以需要预先安装zookeeper,不需要初始化节点,otter程序启动后会自检.
- manager需要在otter.properties中指定一个就近的zookeeper集群机器
2.3.2.otter-mgr
2.3.2.1.创建otter用户
# useradd otter
2.3.2.2.解压otter mgr
# mkdir -p /data1/otter-mgr
# tar -zxvf manager.deployer-4.2.13.tar.gz -C /data1/otter-mgr
2.3.2.3.otter.properties配置
## otter manager domain name
otter.domainName = 10.209.5.199
## otter manager http port
otter.port = 8086
## jetty web config xml
otter.jetty = jetty.xml
## otter manager database config
otter.database.driver.class.name = com.mysql.jdbc.Driver
otter.database.driver.url = jdbc:mysql://10.209.5.199:3401/otter
otter.database.driver.username = otter
otter.database.driver.password = otter123
## otter communication port
otter.communication.manager.port = 1099
## otter communication pool size
otter.communication.pool.size = 10
## default zookeeper address
otter.zookeeper.cluster.default = 10.209.5.197:2181,10.209.5.198:2181,10.209.5.199:2181
## default zookeeper sesstion timeout = 60s
otter.zookeeper.sessionTimeout = 60000
...... ......
2.3.2.4.启动
# chown -R otter:otter /data1/otter-mgr
# su - otter
$ sh /data1/otter-mgr/bin/startup.sh
2.3.2.5.查看日志
$ tail /data1/otter-mgr/logs/manager.log
2017-03-01 14:16:40.655 [] INFO com.alibaba.otter.manager.deployer.OtterManagerLauncher - ## start the manager server.
2017-03-01 14:16:45.062 [] INFO com.alibaba.otter.manager.deployer.JettyEmbedServer - ##Jetty Embed Server is startup!
2017-03-01 14:16:45.062 [] INFO com.alibaba.otter.manager.deployer.OtterManagerLauncher - ## the manager server is running now ......
2.3.2.6.验证
访问:http://10.209.5.199:8086,出现otter页面,即表示启动成功
2.4.Otter Node部署
2.4.1.环境准备
3.1. otter node会受otter manager进行管理,所以需要预先安装otter manager,参见:Otter Manager Quickstart.
3.2. 完成manager安装后,需要在manager页面为node定义配置信息,并生一个唯一id.
3.2.1.首先访问manager页面的机器管理页面
2.4.1.1.登陆Otter Mgr
注意:默认登录的是匿名账户,需要登录超级管理员才能进行操作

2.4.1.2.添加zookeeper集群

2.4.1.3.添加otter node
参数说明:
- 机器名称:可以随意定义,方便自己记忆即可
- 机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
- 机器端口:对应node节点将要部署时启动的数据通讯端口,建议值:2088
- 下载端口:对应node节点将要部署时启动的数据下载端口,建议值:9090
- 外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理。
- zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群.
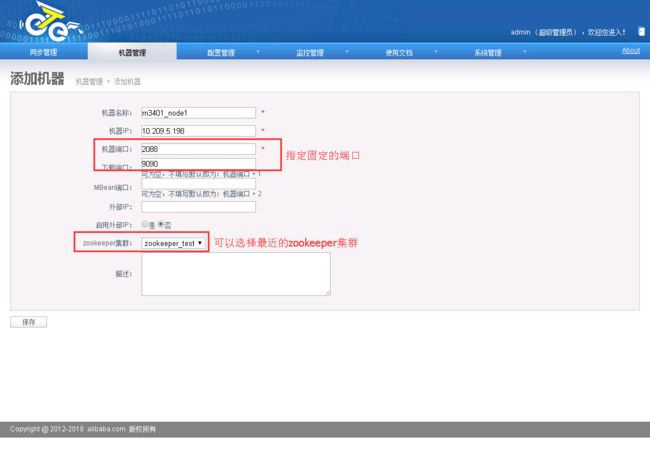
机器添加完成后,跳转到机器列表页面,获取对应的机器序号nid
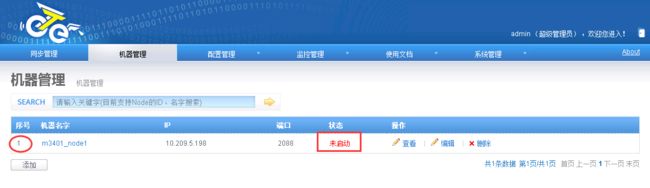
获取到了node节点对应的唯一标示,称之为node id,简称:nid. 记录该nid,后续启动nid时会使用
2.4.2.安装Otter-Node
2.4.2.1.创建用户
# useradd otter
2.4.2.2.解压软件
# mkdir /data1/otter-node1
# tar -zxvf node.deployer-4.2.13.tar.gz -C /data1/otter-node1/
2.4.2.3.nid配置
nid配置 (将环境准备中添加机器后获取到的序号,保存到conf目录下的nid文件,比如我添加的机器对应序号为1)
# cd /data1/otter-node1/conf
# echo 1 > nid
2.4.2.4.otter.properties配置
指定正确的otter mgr程序IP
# otter node root dir
otter.nodeHome = ${user.dir}/../
## otter node dir
otter.htdocs.dir = ${otter.nodeHome}/htdocs
otter.download.dir = ${otter.nodeHome}/download
otter.extend.dir= ${otter.nodeHome}/extend
## default zookeeper sesstion timeout = 60s
otter.zookeeper.sessionTimeout = 60000
## otter communication pool size
otter.communication.pool.size = 10
## otter arbitrate & node connect manager config
otter.manager.address = 10.209.5.199:1099
2.4.2.5.启动node
# chown -R otter:otter /data1/otter-node1/
# su - otter
$ sh /data1/otter-node1/bin/startup.sh
2.4.2.6.查看日志
# tail /data1/otter-node1/logs/node/node.log
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
2017-03-01 15:25:45.362 [main] WARN com.alibaba.otter.shared.common.utils.AddressUtils - Failed to retriving local host ip address, try scan network card ip address. cause: CDM3C24-209005198: CDM3C24-209005198: unknown error
2017-03-01 15:25:45.380 [main] WARN com.alibaba.otter.shared.common.utils.AddressUtils - Failed to retriving local host ip address, try scan network card ip address. cause: CDM3C24-209005198: CDM3C24-209005198: unknown error
2017-03-01 15:25:45.394 [main] INFO com.alibaba.otter.node.deployer.OtterLauncher - INFO ## the otter server is running now ......
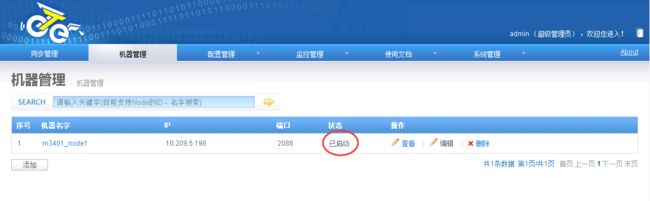
2.4.2.7.验证
登录到mgr端,状态为已启动,代表node启动成功
2.5.Otter单向复制配置
2.5.1.环境准备
准备数据库的源端和目标端
- 源端、目标端数据库安装
- 给予xtrabackup恢复数据库
- 创建数据库用户名、密码 (otter Otter2017 所有权限)
2.5.2.配置单向同步
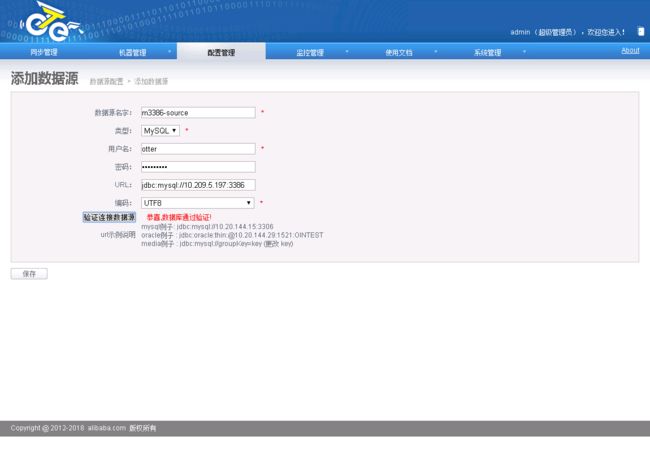
2.5.2.1.添加数据源
配置源端数据源
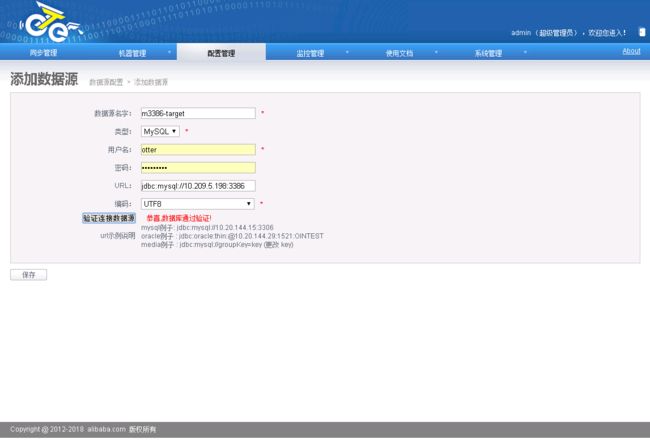
配置目标端数据源
2.5.2.2.添加Canal
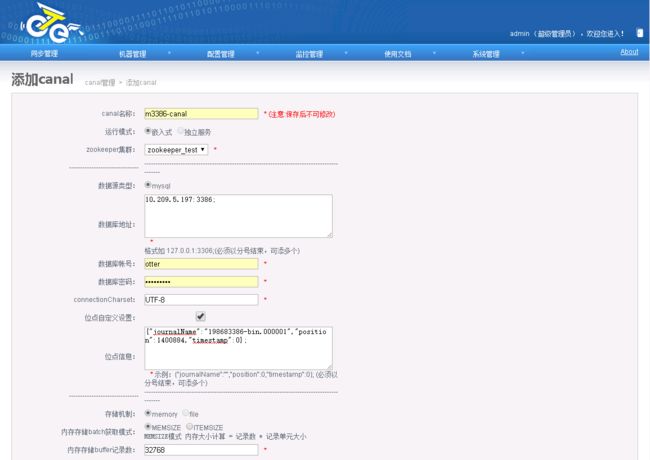
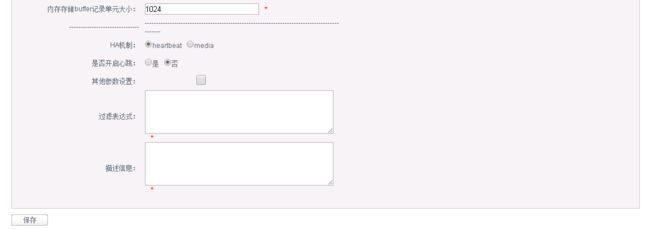
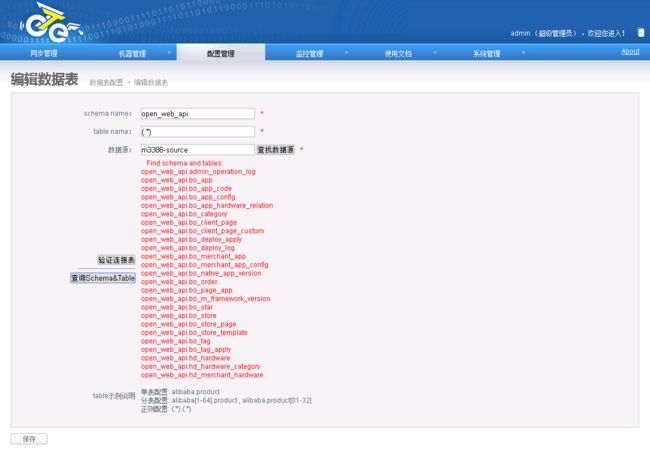
2.5.2.3.添加同步表映射
添加源端映射
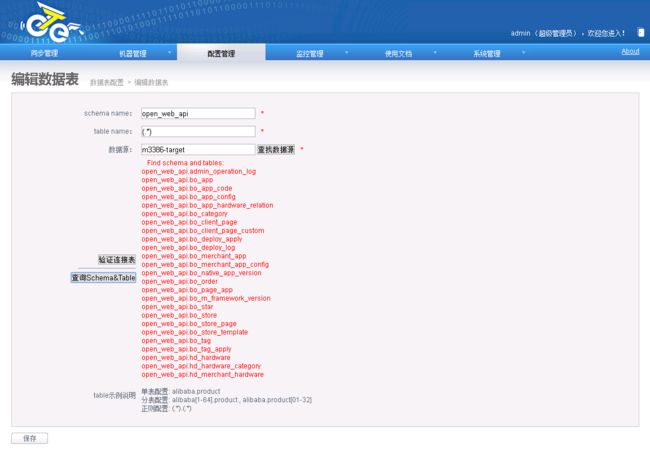
添加目标端映射
2.5.2.4.创建channel
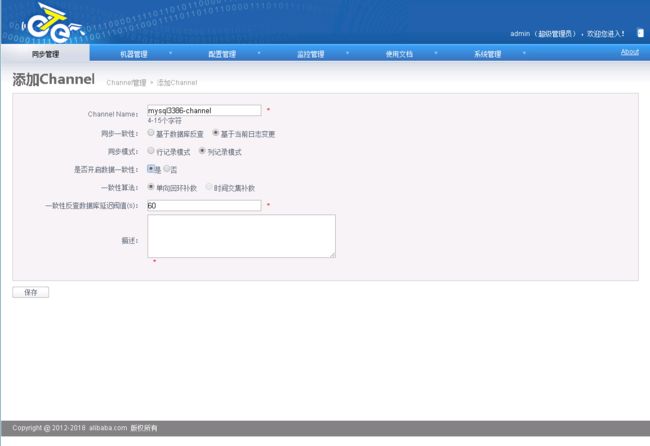
2.5.2.5.添加Piepeline
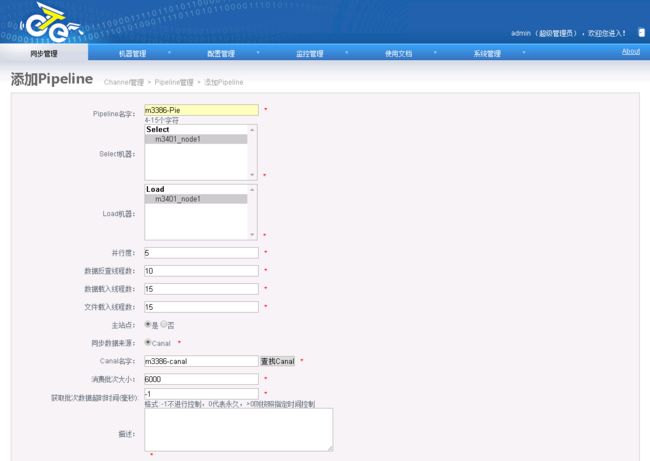
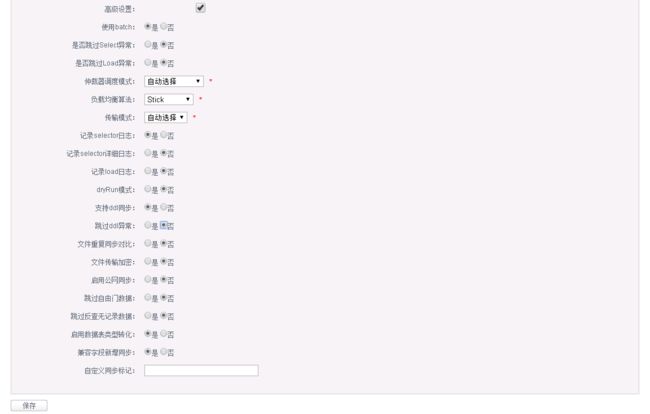
2.5.2.6.添加同步映射规则

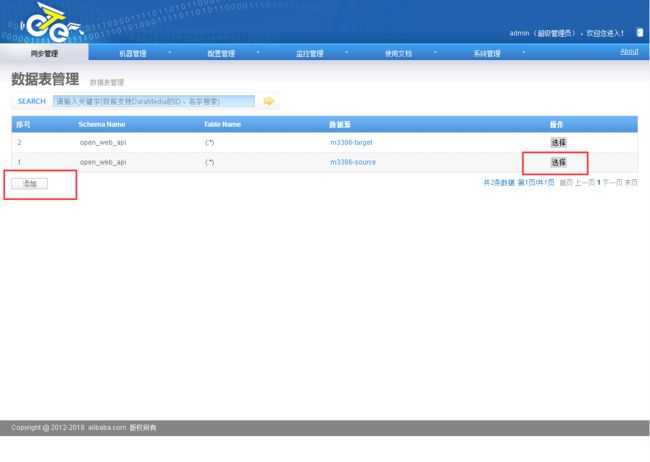
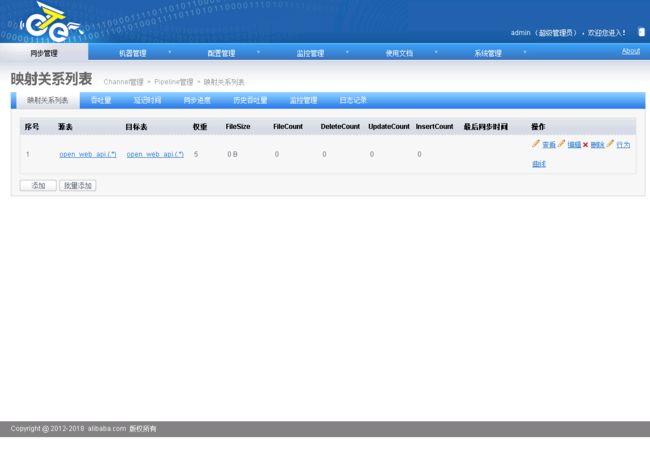
2.5.2.7.启动
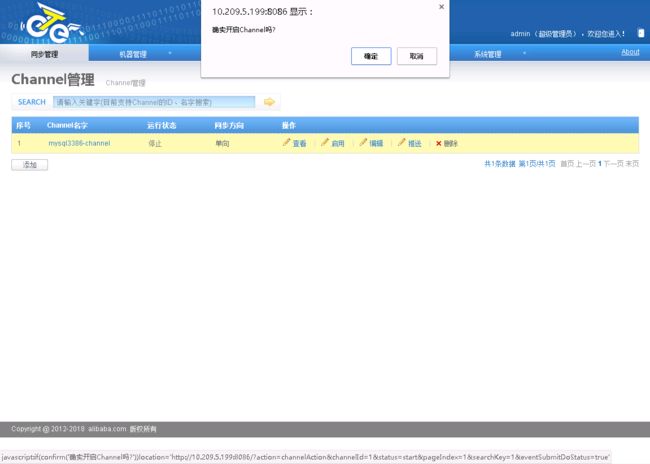
2.6.Otter双向复制配置
双向同步可以理解为两个单向同步的组合,但需要额外处理避免回环同步. 回环同步算法: Otter双向回环控制 .
同时,因为双向回环控制算法会依赖一些系统表,需要在需要做双向同步的数据库上初始化所需的系统表.
2.6.1.创建系统依赖系统表
- 在双向复制数据库中创建系统表
mysql> CREATE DATABASE retl;
Query OK, 1 row affected (0.00 sec)
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO otter@'10.209.5.%';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT SELECT, INSERT, UPDATE, DELETE, EXECUTE ON `retl`.* TO otter@'10.209.5.%';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT SELECT, INSERT, UPDATE, DELETE ON open_web_api.* TO otter@'10.209.5.%';
Query OK, 0 rows affected (0.00 sec)
mysql> USE retl;
Database changed
mysql> CREATE TABLE retl_buffer
-> (
-> ID BIGINT(20) AUTO_INCREMENT,
-> TABLE_ID INT(11) NOT NULL,
-> FULL_NAME varchar(512),
-> TYPE CHAR(1) NOT NULL,
-> PK_DATA VARCHAR(256) NOT NULL,
-> GMT_CREATE TIMESTAMP NOT NULL,
-> GMT_MODIFIED TIMESTAMP NOT NULL,
-> CONSTRAINT RETL_BUFFER_ID PRIMARY KEY (ID)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE retl_mark
-> (
-> ID BIGINT AUTO_INCREMENT,
-> CHANNEL_ID INT(11),
-> CHANNEL_INFO varchar(128),
-> CONSTRAINT RETL_MARK_ID PRIMARY KEY (ID)
-> ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE xdual (
-> ID BIGINT(20) NOT NULL AUTO_INCREMENT,
-> X timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
-> PRIMARY KEY (ID)
-> ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO retl.xdual(id, x) VALUES (1,now()) ON DUPLICATE KEY UPDATE x = now();
Query OK, 1 row affected (0.00 sec)
2.6.2.配置双向复制
配置上相比于单向同步有一些不同,操作步骤:
- 配置一个channel
- 配置两个pipeline
注意:两个单向的canal和映射配置,在一个channel下配置为两个pipeline. 如果是两个channel,每个channel一个pipeline,将不会使用双向回环控制算法,也就是会有重复回环同步. - 每个pipeline各自配置canal,定义映射关系
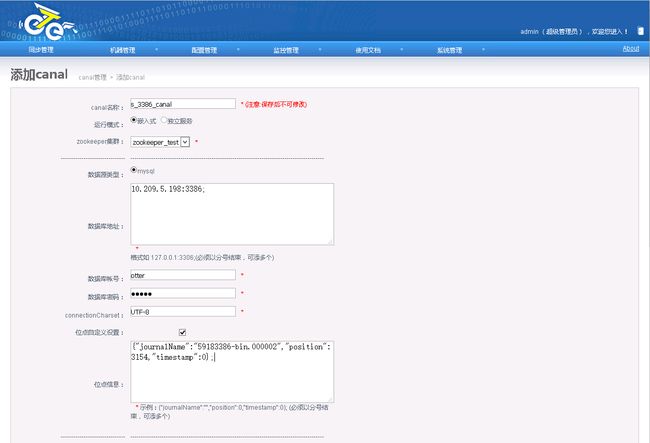
2.6.2.1.新建一个Canal
- 在从库查看当前binlog位置,并基于从库创建一个Canal
mysql> show master status \G
*************************** 1. row ***************************
File: 19923386-bin.000002
Position: 3154
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: e294273e-ffb7-11e6-965a-a0369f790b98:1-24
1 row in set (0.00 sec)
2.6.2.2.停止已运行的Channel
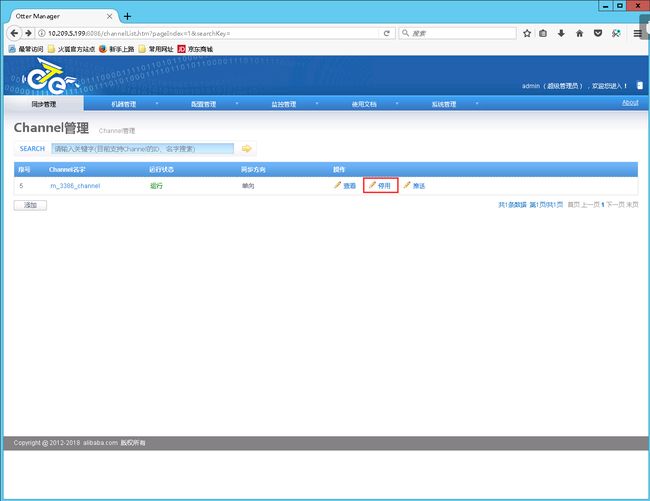
2.6.2.3.配置pipeline
- 基于已停止的单向Channel中,在添加一个反方向的pipeline
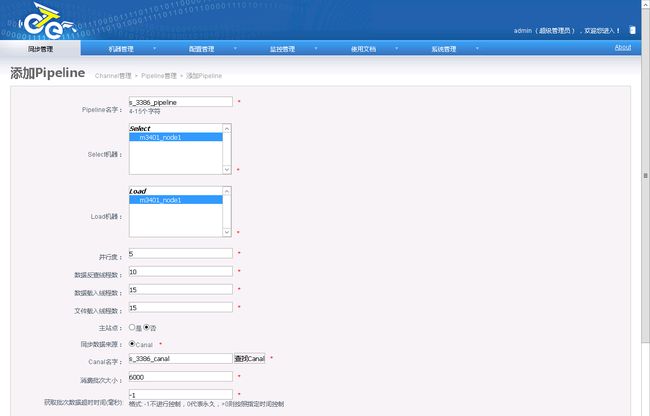
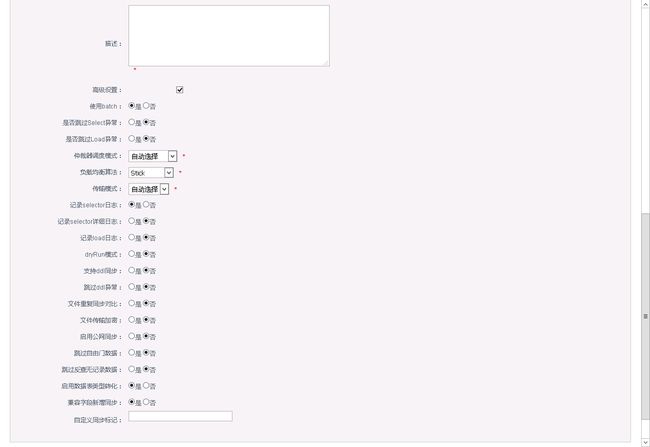
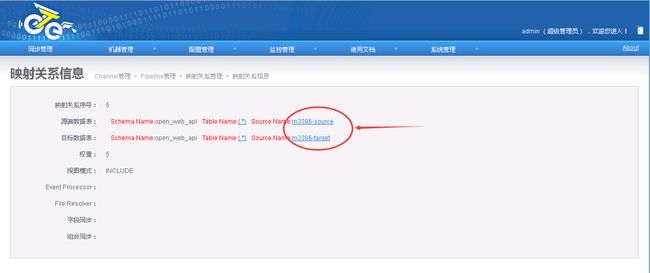
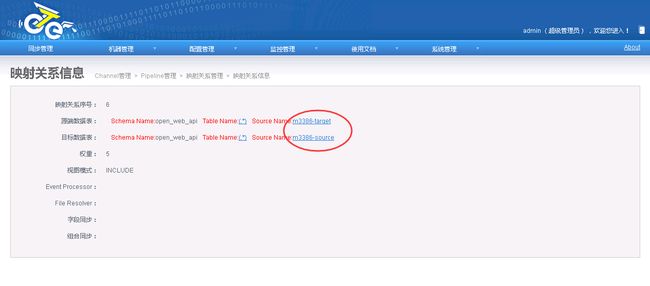
2.6.2.4.配置映射关系列表
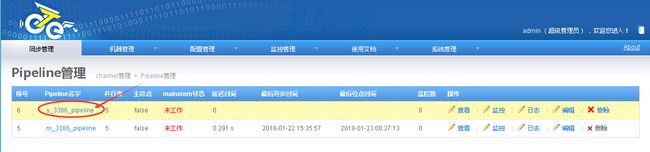
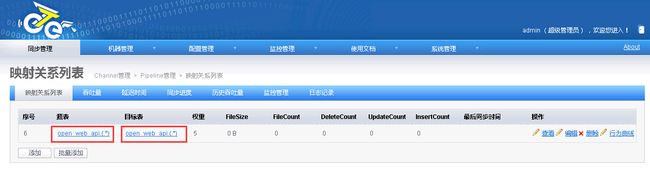
2.6.2.5.启动Channel
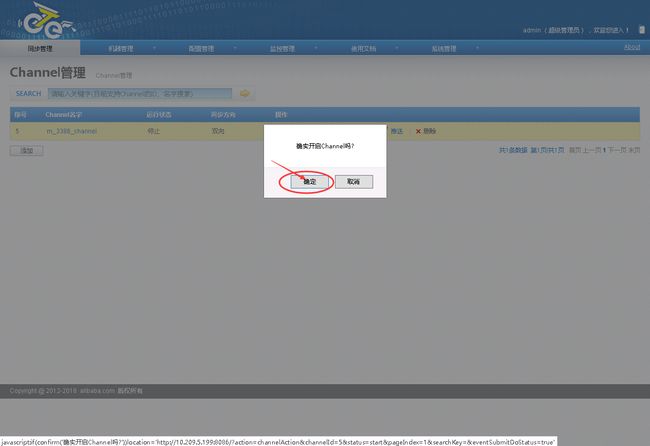
- 测试双写均无异常
2.7.Otter双活配置注意事项
双A同步相比于双向同步,主要区别是双A机房会在两地修改同一条记录,而双向同步只是两地的数据做互相同步,两地修改的数据内容无交集!
所以双A同步需要额外处理数据同步一致性问题. 同步一致性算法:Otter数据一致性 ,目前开源版本主要是提供了单向回环补救的一致性方案.
2.7.1.Channel配置注意事项
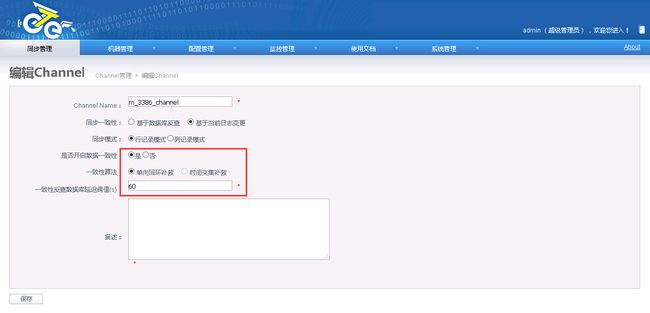
2.7.2.两个pipeline必须配置主从站点关系
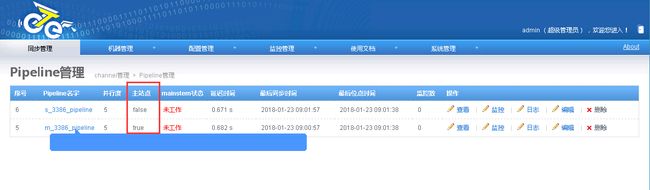
注意:除了需要定义一个主站点外,需要在高级设置中将一个pipeline的“支持DDL”设置为false,另一个设置为true,否则将提示“一个channel中只允许开启单向ddl同步!”错误
2.7.2.每个pipeline各自配置canal,定义映射关系为相互指向
扫描下方二维码关注本人微信号!欢迎大家交流学习!
