对之前我的那个豆瓣的短评的爬虫,进行了一下架构性的改动。尽可能实现了模块的分离。但是总是感觉不完美。暂时也没心情折腾了。
同时也添加了多线程的实现。具体过程见下。
改动
独立出来的部分:
- MakeOpener
- MakeRes
- GetNum
- IOFile
- GetSoup
- main
将所有的代码都置于函数之中,显得干净了许多。(__) 嘻嘻……
使用直接调用文件入口作为程序的起点
if __name__ == "__main__":
main()
注意,这一句并不代表如果该if之前有其他直接暴露出来的代码时,他会首先执行。
print("首先执行")
if __name__ == "__main__":
print("次序执行")
# 输出如下:
# 首先执行
# 次序执行
该if语句只是代表顺序执行到这句话时进行判断调用者是谁,若是直接运行的该文件,则进入结构,若是其他文件调用,那就跳过。
多线程
这里参考了【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top,和我的情况较为类似,参考较为容易。
仔细想想就可以发现,其实爬10页(每页25本),这10页爬的先后关系是无所谓的,因为写入的时候没有依赖关系,各写各的,所以用串行方式爬取是吃亏的。显然可以用并发来加快速度,而且由于没有同步互斥关系,所以连锁都不用上。
正如引用博文所说,由于问题的特殊性,我用了与之相似的较为直接的直接分配给各个线程不同的任务,而避免了线程交互导致的其他问题。
我的代码中多线程的核心代码不多,见下。
thread = []
for i in range(0, 10):
t = threading.Thread(
target=IOFile,
args=(soup, opener, file, pagelist[i], step)
)
thread.append(t)
# 建立线程
for i in range(0, 10):
thread[i].start()
for i in range(0, 10):
thread[i].join()
调用线程库threading,向threading.Thread()类中传入要用线程运行的函数及其参数。
线程列表依次添加对应不同参数的线程,pagelist[i],step两个参数是关键,我是分别为每个线程分配了不同的页面链接,这个地方我想了半天,最终使用了一些数学计算来处理了一下。
同时也简单试用了下列表生成式:
pagelist = [x for x in range(0, pagenum, step)]
这个和下面是一致的:
pagelist = []
for x in range(0, pagenum, step):
pagelist.append(x)
threading.Thread的几个方法
值得参考:多线程
- start() 启动线程
- jion([timeout]),依次检验线程池中的线程是否结束,没有结束就阻塞直到线程结束,如果结束则跳转执行下一个线程的join函数。在程序中,最后join()方法使得当所调用线程都执行完毕后,主线程才会执行下面的代码。相当于实现了一个结束上的同步。这样避免了前面的线程结束任务时,导致文件关闭。
注意
使用多线程时,期间的延时时间应该设置的大些,不然会被网站拒绝访问,这时你还得去豆瓣认证下"我真的不是机器人"(尴尬)。我设置了10s,倒是没问题,再小些,就会出错了。
完整代码
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 17 16:31:35 2017
@note: 为了便于阅读,将模块的引用就近安置了
@author: lart
"""
import time
import socket
import re
import threading
from urllib import parse
from urllib import request
from http import cookiejar
from bs4 import BeautifulSoup
from matplotlib import pyplot
from datetime import datetime
# 用于生成短评页面网址的函数
def MakeUrl(start):
"""make the next page's url"""
url = 'https://movie.douban.com/subject/26934346/comments?start=' \
+ str(start) + '&limit=20&sort=new_score&status=P'
return url
def MakeOpener():
"""make the opener of requset"""
# 保存cookies便于后续页面的保持登陆
cookie = cookiejar.CookieJar()
cookie_support = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(cookie_support)
return opener
def MakeRes(url, opener, formdata, headers):
"""make the response of http"""
# 编码信息,生成请求,打开页面获取内容
data = parse.urlencode(formdata).encode('utf-8')
req = request.Request(
url=url,
data=data,
headers=headers
)
response = opener.open(req).read().decode('utf-8')
return response
def GetNum(soup):
"""get the number of pages"""
# 获得页面评论文字
totalnum = soup.select("div.mod-hd h2 span a")[0].get_text()[3:-2]
# 计算出页数
pagenum = int(totalnum) // 20
print("the number of comments is:" + totalnum,
"the number of pages is: " + str(pagenum))
return pagenum
def IOFile(soup, opener, file, pagestart, step):
"""the IO operation of file"""
# 循环爬取内容
for item in range(step):
start = (pagestart + item) * 20
print('第' + str(pagestart + item) + '页评论开始爬取')
url = MakeUrl(start)
# 超时重连
state = False
while not state:
try:
html = opener.open(url).read().decode('utf-8')
state = True
except socket.timeout:
state = False
# 获得评论内容
soup = BeautifulSoup(html, "html.parser")
comments = soup.select("div.comment > p")
for text in comments:
file.write(text.get_text().split()[0] + '\n')
print(text.get_text())
# 延时1s
time.sleep(10)
print('线程采集写入完毕')
def GetSoup():
"""get the soup and the opener of url"""
main_url = 'https://accounts.douban.com/login?source=movie'
formdata = {
"form_email": "your-email",
"form_password": "your-password",
"source": "movie",
"redir": "https://movie.douban.com/subject/26934346/",
"login": "登录"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1)\
Gecko/20061208 Firefox/2.0.0 Opera 9.50",
'Connection': 'keep-alive'
}
opener = MakeOpener()
response_login = MakeRes(main_url, opener, formdata, headers)
soup = BeautifulSoup(response_login, "html.parser")
if soup.find('img', id='captcha_image'):
print("有验证码")
# 获取验证码图片地址
captchaAddr = soup.find('img', id='captcha_image')['src']
# 匹配验证码id
reCaptchaID = r'运行结果
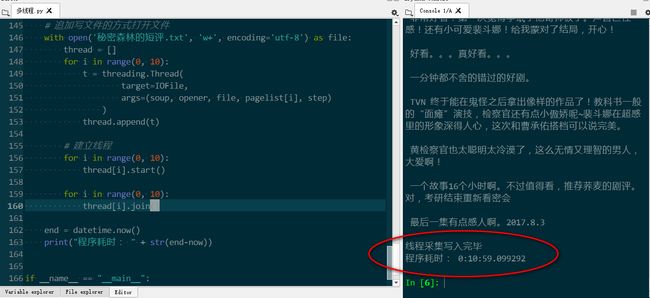
效率有提升
对应的单线程程序在github上。单线程:

可见时间超过30分钟。修改后时间缩短到了11分钟。
文件截图

我的项目
具体文件和对应的结果截图我放到了我的github上。
mypython