一、什么是知识图谱
狭义地讲,知识图谱是由Google公司在2012年提出来的一个新的概念,其被互联网公司用来从语义角度组织网络数据,从而提供智能搜索服务的大型知识库。形式上,知识图谱是一个用图数据结构表示的知识载体,描述客观世界的事物及其关系,其中节点代表客观世界的事物,边代表事物之间的关系。

知识图谱之所以成为学术界和工业界共同关注的热点,主要是由于它的以下几个特点:
- 知识图谱是人工智能应用不可或缺的基础资源
- 语义表达能力丰富,能够支持很多知识服务应用任务
- 描述形式统一,便于不同类型知识的集成和融合
- 表示方法对人类友好,给以众包等方式编辑和构建知识提供了便利
- 二元关系为基础的描述形式,便于知识的自动获取
- 表示方法对计算机友好,支持高效推理
- 基于图结构的数据格式,便于计算机系统的存储和检索
目前,知识图谱已在金融、电商等多个垂直领域落地,高质量的知识逐渐成为企业竞争力的重要表现之一。

二、知识图谱系统及其构建
需要明确的是,知识图谱的落地并不仅仅只是使用图数据库存储数据,更多的是构建知识图谱系统。知识图谱系统处于向上支撑应用向下统摄数据的核心地位,它由各业务系统数据经过处理而来,同时为各业务数据的关联和融合提供了支撑,另一方面,它提供认知服务从而支撑行业智能化升级。
知识图谱系统主要可以分为:
- 知识构建
- 知识管理
- 知识应用
2.1 知识构建
构建知识图谱是一个迭代更新的过程,根据知识构建的逻辑不同,具体的构建思路和顺序也存在差异,但大体上是以下几个阶段的迭代:
1. 知识的表示
通常我们将知识图谱划分为两个层次:数据层和模式层(个人喜欢称之为抽象层)
数据层:存储真实的数据
模式层:在数据层之上,是知识图谱的核心,存储经过提炼的知识(概念定义、属性定义、约束/规则定义等),通常通过本体库来管理(本体库可以理解为面向对象里的“类”这样一个概念,本体库就储存着知识图谱的类)
2. 知识的获取
知识的获取可以理解成从不同来源、不同结构的数据中进行知识提取(实体抽取、关系抽取和事件抽取等),形成知识存入到知识图谱的过程。
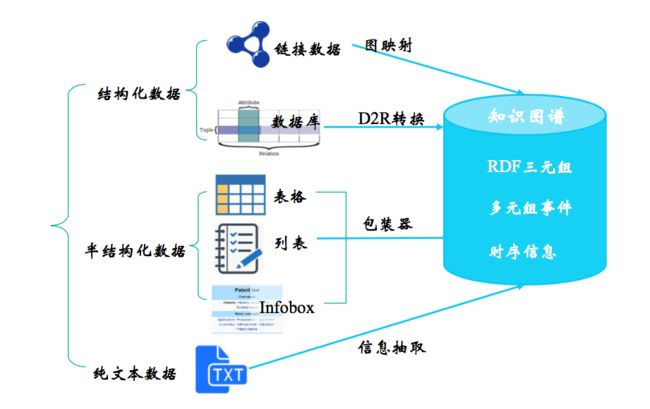
- 从结构化数据中进行知识抽取,其核心便是按模式层所设计的schema将结构化数据映射到当前的知识图谱中,简单地映射可以通过工具D2RQ完成,但复杂的映射关系或涉及知识融合的映射则需要专人编写算法来解决。
从半结构化(网站)数据中获取知识本质上其实是爬虫工程,大多时候便是针对爬取的网站,编写相应的包装器
从文本中获取知识对应的便是自然语言处理中的信息抽取技术,这一部分也是目前学术研究的热点,主要涉及命名实体识别任务、关系抽取任务、事件抽取任务等
3. 知识的融合
知识图谱的构建经常需要融合多种不同来源的数据,在进行知识融合的过程中,常涉及到以下几个任务:
- 本体 | 概念提取和融合
- 实体对齐和实体链接
- 属性融合
- 属性值范化
其中,实体对齐是知识融合的核心,计算实体相似度主要可以分为以下几类方法:
- 聚合
加权平均,手动制定规则,分类器
- 聚类
层次聚类,相关性聚类
- 知识嵌入
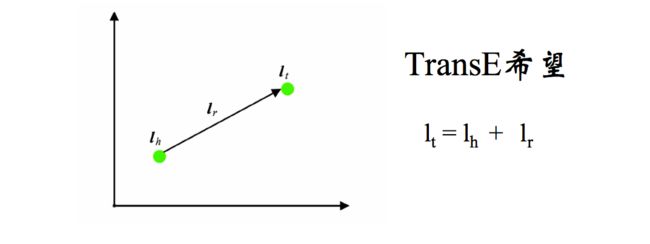
知识嵌入指将知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度。这类方法不依赖任何的文本信息,获取到的都是数据的深度特征。下图是TransE模型,其中使用(h, r, t)表示三元组,使用、和分别表示头向量、关系向量和尾向量。
在实际应用中,可以使用清华大学推出的OpenKE:
# 预测头实体
def predict_head_entity(self, t, r, k):
'''This mothod predicts the top k head entities given tail entity and relation.
Args:
t (int): tail entity id
r (int): relation id
k (int): top k head entities
Returns:
list: k possible head entity ids
'''
self.init_link_prediction()
if self.importName != None:
self.restore_tensorflow()
test_h = np.array(range(self.entTotal))
test_r = np.array([r] * self.entTotal)
test_t = np.array([t] * self.entTotal)
res = self.test_step(test_h, test_t, test_r).reshape(-1).argsort()[:k]
print(res)
return res
除了使用上述算法,针对实体对齐和实体链接任务,已有较多优质的工具可以直接使用:
Falcon-AO:一个自动的本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择
Dedupe: 用于模糊匹配, 记录去重和实体链接的python库
Limes: 一个基于度量空间的实体匹配发现框架,适合于大规模数据链接
Silk: 一个的集成异构数据源的开源框架,编程语言为python,提供图形化用户界面—Silk Workbench,用户可以很方便的进行记录链接
agdistispy: 对于http://aksw.org/Projects/AGDISTIS.html的REST API的python封装,用于实体链接到dbpedia
tagme-python: 对于https://tagme.d4science.org/tagme/的REST API的python封装,用于实体链接到Wikipedia,并且拥有实体识别和相似度对比的功能
import tagme # 设置访问TOKEN # TOKEN获取途径:
# 1. Register to the [D4Science TagMe VRE](https://services.d4science.org/group/tagme/)
# 2. After login, click the show button on the left panel to get your authorization token
tagme.GCUBE_TOKEN = "访问上面的网址注册即可获得"
lunch_annotations = tagme.annotate("apples")
for ann in lunch_annotations.get_annotations():
print(ann)
>> apples -> Apple (score: 0.018155893310904503)
rels = tagme.relatedness_title([("Barack_Obama", "Italy"),
("Italy", "Germany"),
("Italy", "BAD ENTITY NAME")])
for rel in rels.relatedness:
print(rel)
>> Barack Obama, Italy rel=0.05192309617996216
>> Italy, Germany rel=0.6111182570457458
>> Italy, BAD ENTITY NAME rel=None
rels_dict = dict(rels)
print(rels_dict[("Barack Obama", "Italy")])
>> 0.05192309617996216
4. 知识的评估
人工验证:众包验证、抽样验证和批量验证
算法评估:三元组置信度
5. 知识的更新
- 知识补全
- 知识纠错
- 同步更新
2.2 知识管理
知识管理主要涉及知识存储问题,一般有两种选择:
通过RDF(资源描述框架)这样的规范存储格式来进行存储,比较常用的数据库有Jena等
通过图数据库来进行存储,常用的有Neo4j、JanusGraph等
1. RDF
在RDF中,知识总是以三元组形式出现,即每一份知识可以被分解为( subject (主) , predicate (谓) , object (宾) )的形式

RDF的实际存储形式:
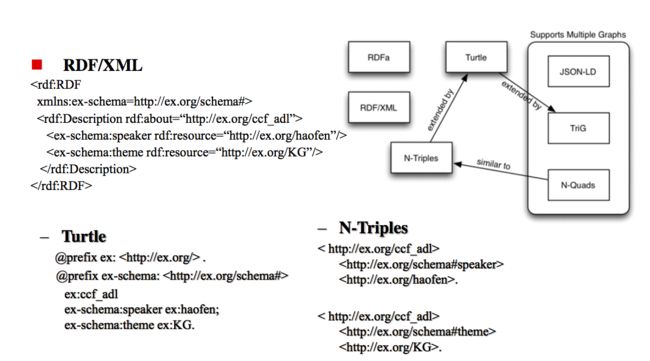
2. Neo4j
Neo4j是一种原生图数据库,包含两种基本的数据类型:Nodes (节点) 和 Relationships (关系)。Nodes和Relationships 包含 key/value形式的属性。 Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构

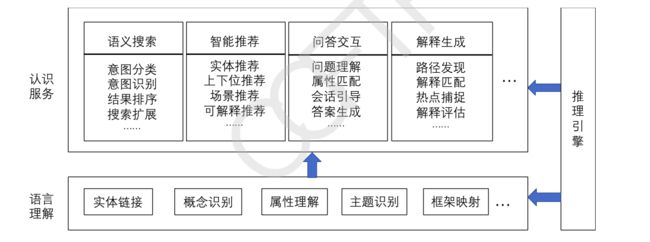
2.3 知识应用
知识图谱系统能够提供认知能力,包括语言理解、认知服务、推理引擎