What is DataFlow ?
谷歌的Dataflow首先是一个为用户提供以流式或批量模式处理海量数据能力的服务: https://cloud.google.com/dataflow,该服务的编程接口模型(或者说计算框架)也就是下面要讨论的Dataflow模型
谷歌认为,流式数据处理是unbounded data(processing),也就是无边界的连续的数据(的处理);对应的批量(计算),更准确的说法是bounded data(processing),亦即有明确边界的数据的处理,但是随着技术的发展,继续用这种方式来分类和看待问题就显得不够高大上
而Dataflow模型则是谷歌在处理无边界数据的实践中,总结的一套SDK级别的解决方案,其目标是做到在非有序的,无边界的海量数据上,基于事件时间进行运算,并能根据数据自身的属性进行window操作,同时数据处理过程的正确性,延迟,代价可根据需求进行灵活的调整配置。
核心思想:
DataFlow计算模型,希望从编程模型的源头上,统一解决传统的流式和批量这两种计算语义所希望处理的问题。
在Dataflow模型里强调的两个时间概念:Event time和 Process time:
Event time 事件时间就是数据真正发生的时间,比如用户浏览了一个页面,或者下了一个订单等等,这时候通常就会有一些数据会被生产出来,比如前者可能会产生一条用户的浏览日志
而Process time则是这条日志数据真正到达计算框架中被处理的时间点,简单的说,就是你的程序是什么时候读到这条日志的
现实情况下,由于各种原因,数据采集,传输到达处理系统的时间可能会有长短不同的延迟,在分布式应用场景环境下,不仅是延迟,数据乱序到达往往也是常态
基于无边界数据集的特性,在Dataflow模型中,数据的处理过程中需要解决的问题,被概括为以下四个方面:
- What results are being computed. : 计算逻辑是什么
- Where in event time they are being computed. : 计算什么时候(事件时间)的数据
- When in processing time they are materialized. : 在什么时候(处理时间)进行计算/输出
- How earlier results relate to later refinements. : 后续数据如何影响(修正)之前的计算结果
清晰的定义这些问题,并针对性的在模型框架层面加以解决,正是Dataflow模型区别于其它流式计算模型的核心关键所在。通常的流式计算框架往往模糊或者无法有效的区别对待数据的事件时间和处理时间,对于第4个问题,如何修正数据,也可能缺乏直接的支持。
Dataflow计算模型的目标是把上述4方面的问题,用明确的语意,清晰的拆分出来,更好的模块化,从而实现在模型层面调整局部设置,就能快速适应各种业务逻辑的开发需求。
理论模型
那么Dataflow是如何解决上面四个方面的问题呢,基本上,是通过构建以下三个核心功能模型来做到的:
- 一个支持基于事件时间的窗口(window)模型,并提供简易的API接口:支持固定窗口/滑动窗口/Session(以Key为维度,基于事件时间连续性进行划分)等窗口模式
- 一个和数据自身特性绑定的计算结果输出触发模型,并提供灵活可描述的API接口
- 一个增量更新模型,可以将数据增量更新的能力融合进上述窗口和结果触发模型中。
窗口模型
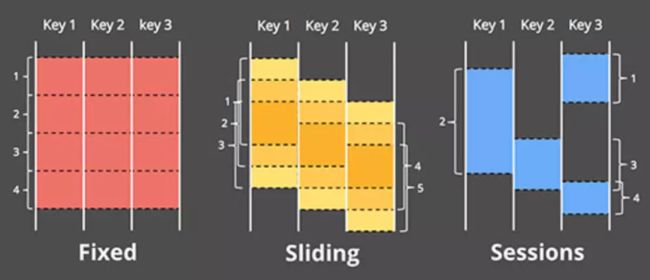
为了在计算框架级别实现基于事件时间的窗口模型,Dataflow系统中,将常见的流式计算框架中的[key,value]两元组tuple形式的信息数据,变换成了[key,value, event time, window ]这样的四元组模型
Event time的引入原因显而易见,必须要有相关载体承载这个信息,否则只能基于Process time/Batch time 来划分窗口
而window窗口标识信息的引入,个人认为,很重要的一个原因是要支持Session类型的窗口模型,而同时,要将流式和增量更新的支持融合进窗口的概念中,也势必需要在数据中引入这样一个显式的窗口信息(否则,通常的做法就只能是用micro batch分组数据的方式,隐式的标识数据的窗口属性)
在消息的四元组数据结构基础上,Dataflow通过提供对消息进行窗口赋值,窗口合并,按key分组,按窗口分组等原子功能操作,来实现各种窗口模型。
窗口触发模型
多数基于Process time定义的固定窗口或滑动窗口模型,并没有特别强调窗口触发这样一个概念,因为在这类模型中,窗口的边界时间点,也就是触发计算结果输出的时间点,并不需要特别加以区分。
而对于Dataflow这样的基于事件时间的模型来说,由于事件时间和处理时间之间存在非固定的延迟,而框架又需要正确的处理乱序的数据,这使得判断窗口的边界位置,进而触发计算和结果输出变得困难起来。
在这一点上,Dataflow部分借用了底层Millwheel提供的Low watermark低水位这样一个概念来解决窗口边界的判断问题,当低水位对应的时间点超过设定的时间窗口边界时间点时,触发窗口的计算和结果输出。但是,低水位的概念在理论上虽然是OK的,在实际场景中,通常是一个概率模型,并不能完全保证准确的判断事件时间的延迟情况,而且有很多场合对窗口边界的判断,用户自己有自己的需求。
因此,Dataflow提供了可自定义的窗口触发模型,可以使用低水位做触发,也可以使用比如:定时触发,计数触发,计量触发,模式匹配触发或其它外部触发源,甚至各种触发条件的逻辑运算组合等机制来应对可能的需求。
增量更新模型
当一个特定时间窗口被触发以后,后续晚到的数据如何处理,如何对之前触发结算的结果进行修正,Dataflow在框架层面也提供了直接的支持,基本上包括三种策略:
- 丢弃:一旦特定窗口触发过,对应窗口的数据就丢弃,晚到的数据也丢弃
- 累计:触发过的窗口对应的数据保留(保留时间策略也可调整),晚到的数据更新对应窗口的输出结果
- 累计并更正:和累积模式类似,区别在于会先对上一次窗口触发的结果发送一个反相修正的信息,再输出新的结果,便于有需要的下游更正之前收到的信息
通常来说,丢弃策略实现起来最简单,既没有历史数据负担,对下游计算也不产生影响。但是前提条件是,数据乱序或者晚到的情况不严重或者不重要或者不影响最后的统计结果的精度
累计策略,从窗口自身的角度来说,实现起来也不复杂,除了内存代价会高一些,因为要保留历史窗口的数据,但是存在的问题是有些下游运算逻辑是基于上游运算结果计算的,下游计算逻辑能否正确处理重复输出的窗口结果,正确的进行去重或者累加,往往是个问题。
累计并更正策略,就窗口自身逻辑来说,实现上会更加复杂一点,但是下游计算逻辑的编写复杂性其实才是最难的。反相修正信息,是为了给下游提供更多的信息来解决上述窗口运算结果重复输出问题,增加了下游链路去重数据的能力,但实际上,这个逻辑需要下游计算逻辑的深度配合才能实现,个人觉得,除了部分计算拓扑逻辑相对简单的程序能够正确处理好这种情况,依赖关系稍微复杂一点的计算链路,靠反相修正信息,要做到正确的累加或去重还是很困难的。
总体来说,Dataflow model通过构建了一种提供了三个核心功能的编程模型统一解决了传统的流式和批量这两种计算语义所希望处理的四个方面的问题。