最近公司搭建了Clickhouse的集群,作为一款久负盛名的高性能OLAP查询引擎,我们也针对自己的使用场景的进行了一下体验,对Clickhouse的使用和性能有了一定的体会。下面我们将从Clickhouse的建表,数据导入,查询语法和性能情况进行简要的总结:
1. Clickhouse的建表
首先贴一下我们Clickhouse的集群情况:集群由三台机器组成,其中一个为集群节点,三个为分片节点,每个分片节点的磁盘为12T。

Clickhouse集群配置
这次我们想导入的数据,来源是离线计算产生的Hive表,因此首先现在Clickhouse上创建对应的表,在建表时有以下几点需要注意:
- 由于搭建的是Clickhouse集群环境,建表时需要在集群节点上创建一个Distributed的表,在每个分片节点创建MergeTree的表。在数据导入和查询时直接操作Distributed表,Distributed表会自动路由到相应的MergeTree表。
- Hive中的数据类型,在Clickhouse中都有对应的类型名称:比如bigint -> Int64, int -> Int32, float -> Float32,需要按照Clickhouse的类型定义各个字段。
- Clickhouse的字段默认是不允许为NULL的,如果数据有可能为NULL,需要将字段定义为类似Nullable(Int64)的类型。
- 创建MergeTree表,需要设置分区字段和排序字段,排序字段一般会选择将经常聚合的维度排在前面,如果不清楚常用查询场景的话,和分区字段一致就可以了。
- 创建Distributed表,不需要分区字段和排序字段,但要注意在Clickhouse的集群节点创建,不要在分片节点创建。
因此这次我们的建表语句如下所示,执行后显示OK。
- 创建Distributed表,在10.128.184.59:8000集群节点:
CREATE TABLE t
(
platform_id Nullable(Int32),
channel_id Nullable(Int64),
...
bidding_strategy Nullable(Int32),
landing_page_type Nullable(Int32),
region_id Nullable(Int16),
dt String
)
ENGINE = Distributed(ad_test_cluster, ad_test, t, rand())
- 创建MergeTree表,在10.128.184.55:9000, 10.128.184.59:9000和10.128.184.59:9000三个分片节点:
CREATE TABLE t
(
platform_id Nullable(Int32),
channel_id Nullable(Int64),
...
bidding_strategy Nullable(Int32),
landing_page_type Nullable(Int32),
region_id Nullable(Int16),
dt String
)
ENGINE = MergeTree
PARTITION BY dt
ORDER BY dt
SETTINGS index_granularity = 8192
2. Clickhouse的数据导入
建表之后开始向表中导入数据,这里我们采用的是将csv文件直接导入的方式,这里有一些值得注意的细节:
- 如果表的字段是Nullable的话,在csv文件中,对应列的值应该为\N,否则将无法导入。
- 由于将csv文件导入,执行的是INSERT语句,因此在导入前需要先Drop相应的分区,保证数据不会重复导入。但是Drop的操作需要直接在分片节点操作,因此需要找到分片节点。可以在每个分片节点的system.parts表中,查看该分片上包含哪些分区,如果存在的话则可以进行Drop操作。
以下是数据导入的过程执行的命令:
# 将csv中的NULL替换为\N
sed -i "s/NULL/\\\N/g" data.csv
# drop分区已有的数据(需要找到对应的分片节点)
clickhouse-client -h 10.128.184.59 --port 9000 -d ad_test -u ad_test --password adxxx --query="alter table t drop partition('2019-10-01')"
# 导入数据到Clickhouse中
cat data.csv | clickhouse-client -h 10.128.184.59 --port 8000 -d ad_test -u ad_test --password adxxx --format_csv_delimiter="|" --query="insert into t format CSV"
3. Clickhouse的查询语法
Clickhouse支持标准的SQL语法,在实测中没有遇到太多的问题。
目前只有一种情况是需要注意的:
- 聚合指标不能同时出现在两个select字段中:
SELECT
sum(charged_fees) AS charged_fees,
sum(conversion_count) AS conversion_count,
(sum(charged_fees) / sum(conversion_count)) / 100000 AS conversion_cost
FROM t
WHERE dt = '2019-07-01'
Received exception from server (version 19.1.9):
Code: 184. DB::Exception: Received from 10.128.184.59:9000. DB::Exception: Aggregate function sum(charged_fees) is found inside another aggregate function in query.
0 rows in set. Elapsed: 0.041 sec.
针对这种情况,把SQL改写为以下形式即可:
SELECT
sum(charged_fees) AS charged_fees,
sum(conversion_count) AS conversion_count,
(charged_fees / conversion_count) / 100000 AS conversion_cost
FROM t
WHERE dt = '2019-07-01'
┌──charged_fees─┬─conversion_count─┬────conversion_cost─┐
│ 3143142724482 │ 250537 │ 150.37090954370022 │
└───────────────┴──────────────────┴────────────────────┘
(虚假数据,可能不准确)
1 rows in set. Elapsed: 0.155 sec. Processed 32.56 million rows, 1.20 GB (210.00 million rows/s., 7.77 GB/s.)
4. Clickhouse的性能测试
这里横向比较了Clickhouse和Impala的性能,针对线上的1219个查询语句,数据量基本在Billion级别,分别统计了两者的查询时间的指标。
- Clickhouse的查询平均性能要优于Impala,提升大概在2-4倍。
- Clickhouse的查询时间分布更加稳定,Impala会偶尔出现查询时间不稳定的情况。
以下是详细的测试数据,单位为毫秒(ms):
- 全部查询语句:
| 查询引擎 | 均值 | 标准差 | 中位数 | 99Percentile |
|---|---|---|---|---|
| Impala | 5473.17 | 13589.28 | 1797 | 73790.02 |
| Clickhouse | 1790.07 | 1446.40 | 1203 | 6428.56 |
- Impala查询小于60s的语句:
| 查询引擎 | 均值 | 标准差 | 中位数 | 99Percentile |
|---|---|---|---|---|
| Impala | 3425.88 | 5891.56 | 1782 | 23806.4 |
| Clickhouse | 1790.07 | 1446.40 | 1203 | 6428.56 |

Impala查询小于60s的语句查询时间分布
- Impala查询小于10s的语句:
| 查询引擎 | 均值 | 标准差 | 中位数 | 99Percentile |
|---|---|---|---|---|
| Impala | 2044.85 | 1206.08 | 1743 | 6506.60 |
| Clickhouse | 1790.07 | 1446.40 | 1203 | 6428.56 |
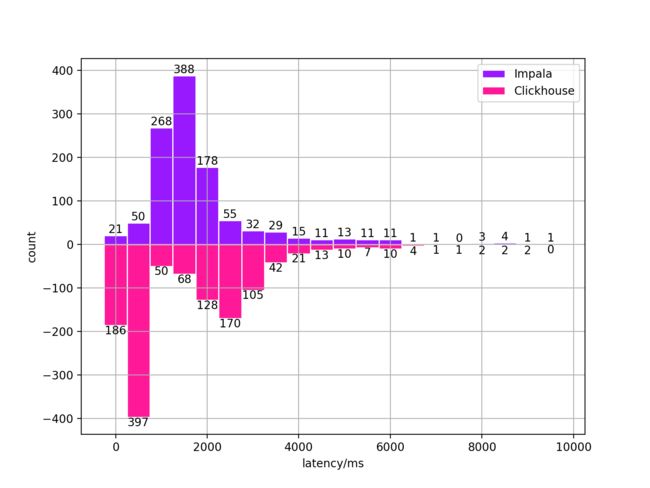
Impala查询小于10s的语句查询时间分布
可以看到,在去掉Impala大部分的慢查询后,Clickhouse仍然有一定的性能优势,在整体上的表现是优于Impala的。测试的SQL中没有覆盖到join的场景,但从原理上来看,Clickhouse的join性能表现应该也会比较稳定。
5. 小结
以上是在初次接触Clickhouse的一些体会,后续会在Clickhouse的使用和优化,以及数据同步工具Waterdrop的调研上继续。