问题:
通过java编程式方式(非配置文件)完整示例,通过sharding-jdbc实现:
1. 分库,根据user_ip进行简单的分库示例
2. 分表,实现针对时间的分表
3. 读写分离,进行主从集群配置
表结构:
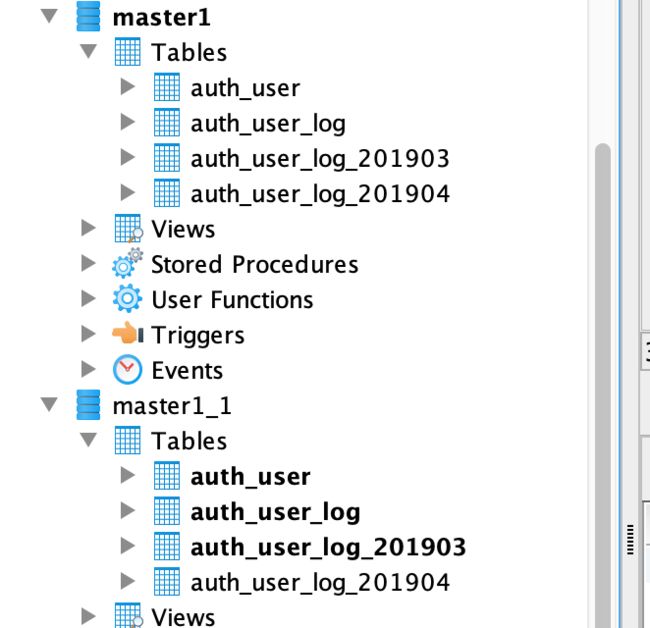
image.png
本次测试一共建了4个库:master1、master2、master1_1、master2_2,其中两对主从库.
- master1主写库----->master1_1 从读库
- master2主写库------> master2_2从写库
其中测试表auth_user_log进行分表测试,看下这个表结构:
CREATE TABLE if not exists
master1.auth_user_log
(
id bigint NOT NULL AUTO_INCREMENT,
log_id VARCHAR(64),
account VARCHAR(64),
account_name VARCHAR(64) NOT NULL,
application_name VARCHAR(64) NOT NULL,
user_ip VARCHAR(32) NOT NULL,
url VARCHAR(64) NOT NULL,
request_body VARCHAR(2048) NOT NULL,
reponse_body VARCHAR(2048) NOT NULL,
invoke_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
invoke_cost INT,
PRIMARY KEY (id),
CONSTRAINT log_id UNIQUE (log_id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户访问记录表';
我们通过
- master1和master2 两个主库来测试根据user_ip字段进行分库操作,
- 根据invoke_time进行时间的分表测试
- 根据master1和master1_1进行读写分离配置测试
源代码路径
https://gitee.com/kaiyang_taichi/demo-shariding-jdbc.git
数据库脚本:

image.png
配置讲解:
- 通过springboot配置了4个库的数据源master1, master2, master1_1, master2_2
- 通过MasterSlaveRuleConfiguration进行读写分离配置,可以配置多从库,选择从库的负载策略,对于读多写少的业务场景很实用
- 然后针对单个表的配置通过
TableRuleConfiguration进行处理. - 根据user_ip的hashcode进行分库,通过UserLogDbShardingAlgorithm类进行处理
- 根据invoke_time字段进行分表,通过 UserLogTableShardingAlgorithm和UserLogTableRangeShardingAlgorithm(查询一段时间范围内的数据使用)配置.
@Configuration
public class ShardingDataSourceConfiguration {
/**
* 主写库1
* @return
*/
@Bean("master1")
@ConfigurationProperties(prefix = "spring.datasource.master1")
public DataSource dataSource1() {
return DataSourceBuilder.create().build();
}
/**
* 主写库2
* @return
*/
@Bean("master2")
@ConfigurationProperties(prefix = "spring.datasource.master2")
public DataSource dataSource2() {
return DataSourceBuilder.create().build();
}
/**
* 从读库1
* @return
*/
@Bean("master1_1")
@ConfigurationProperties(prefix = "spring.datasource.master11")
public DataSource dataSource1_1() {
return DataSourceBuilder.create().build();
}
/**
* 从读库2
* @return
*/
@Bean("master2_2")
@ConfigurationProperties(prefix = "spring.datasource.master22")
public DataSource dataSource2_2() {
return DataSourceBuilder.create().build();
}
@Bean(name = "shardDataSource")
@Primary
public DataSource shardDataSource(@Qualifier("master1") DataSource dataSource,
@Qualifier("master2") DataSource dataSource2,@Qualifier("master1_1") DataSource dataSource3,
@Qualifier("master2_2") DataSource dataSource4) throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
List configurationList = new ArrayList<>();
//1.读写分离配置一,master1为写库1,master1_1为读库1,这两个库将会在数据库层面进行配置主从数据同步
MasterSlaveRuleConfiguration masterSlaveRuleConfiguration = new MasterSlaveRuleConfiguration();
// 一组主从库分组
masterSlaveRuleConfiguration.setName("master1Config");
//主库名
masterSlaveRuleConfiguration.setMasterDataSourceName("master1");
List slaves = new ArrayList<>();
slaves.add("master1_1");
//从库列表
masterSlaveRuleConfiguration.setSlaveDataSourceNames(slaves);
//从库的负载选择策略 masterSlaveRuleConfiguration.setLoadBalanceAlgorithmType(MasterSlaveLoadBalanceAlgorithmType.ROUND_ROBIN);
configurationList.add(masterSlaveRuleConfiguration);
//2.读写分离配置二,master1为写库2,master2_2为读库2,这两个库将会在数据库层面进行配置主从数据同步
MasterSlaveRuleConfiguration masterSlaveRuleConfiguration2 = new MasterSlaveRuleConfiguration();
masterSlaveRuleConfiguration2.setName("master2Config");
masterSlaveRuleConfiguration2.setMasterDataSourceName("master2");
List slaves2 = new ArrayList<>();
slaves2.add("master2_2");
masterSlaveRuleConfiguration2.setSlaveDataSourceNames(slaves2);
masterSlaveRuleConfiguration2.setLoadBalanceAlgorithmType(MasterSlaveLoadBalanceAlgorithmType.ROUND_ROBIN);
configurationList.add(masterSlaveRuleConfiguration2);
//3,将读写分离配置加到主配置类中
shardingRuleConfig.setMasterSlaveRuleConfigs(configurationList);
// 4。将分库分表规则加入到主配置类中
shardingRuleConfig.getTableRuleConfigs().add(getUserLogTableRuleConfiguration());
// 打印SQL
Properties props = new Properties();
props.put("sql.show", true);
Map map = new HashMap<>();
map.put("master1", dataSource);
map.put("master2", dataSource2);
map.put("master1_1", dataSource3);
map.put("master2_2", dataSource4);
return new ShardingDataSource(shardingRuleConfig.build(map),
new ConcurrentHashMap(), props);
}
/**
* 配置用户日志读分库分表策略
* 1。 根据user_ip的hashcode进行分库,写入不同主库
* 目前主写库有两个:master1,master2
* 2。根据invoke_time进行分表,写入不同的子表
* 目前子表有:
* auth_user_log,默认表
* auth_user_log_201903,19年第三季度表
* auth_user_log_201904,19年第四季度表
* @return
*/
@Bean
TableRuleConfiguration getUserLogTableRuleConfiguration() {
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable("auth_user_log");
orderTableRuleConfig.setLogicIndex("invoke_time");
//设置数据库分库策略,根据ip的hash值,按2的倍数分库
orderTableRuleConfig.setDatabaseShardingStrategyConfig(
new StandardShardingStrategyConfiguration("user_ip", UserLogDbShardingAlgorithm.class.getName()));
// 设置分表策略
orderTableRuleConfig.setTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("invoke_time", UserLogTableShardingAlgorithm.class.getName(),
UserLogTableRangeShardingAlgorithm.class.getName()));
// 设置数据节点,格式为dbxx.tablexx。这里的名称要和map的别名一致。下面两种方式都可以
orderTableRuleConfig.setActualDataNodes(UserLogTableRangeShardingAlgorithm.toUserLogDbConfigString());
return orderTableRuleConfig;
}
@Bean(name = "transactionManager")
public DataSourceTransactionManager registerPowerTransactionManager(
@Qualifier("shardDataSource") DataSource shardDataSource) throws Throwable {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(shardDataSource);
return dataSourceTransactionManager;
}
//
@Bean(name = "sqlSessionFactory")
public SqlSessionFactoryBean sqlSessionFactoryBean(@Qualifier("shardDataSource") DataSource shardDataSource)
throws Throwable {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(shardDataSource);
//mapper
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Resource[] mapperResources = resolver.getResources("classpath:mapper/*Mapper.xml");
sqlSessionFactoryBean.setMapperLocations(mapperResources);
//mybatis-config
ResourceLoader loader = new DefaultResourceLoader();
Resource configLocation = loader.getResource("classpath:mybatis-config.xml");
sqlSessionFactoryBean.setConfigLocation(configLocation);
return sqlSessionFactoryBean;
}
}
分库配置讲解:
- 简单的规则模拟
- 注意:
匹配配置的数据源别名,此处注意,当配置主从集群的时候,这块dbNmame是主从组的组名,如果不配置集群组时,这里配置的是两个库自己的别名,如此时没有主从的话,此处匹配master1和master2
public class UserLogDbShardingAlgorithm implements PreciseShardingAlgorithm {
private static final String DB1 = "master1Config";
private static final String DB2 = "master2Config";
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
String dbNmame;
//简单的规则模拟场景,具体算法根据实际处理
String ip = shardingValue.getValue();
int i = ip.hashCode();
dbNmame = i % 2 == 0 ? DB1 : DB2;
// 匹配配置的数据源别名,此处注意,当配置主从集群的时候,这块dbNmame是主从组的组名,如果不配置集群组时,这里配置的是两个库自己的别名,如此时没有主从的话,此处匹配master1和master2
for (String each : availableTargetNames) {
if (each.equals(dbNmame)) {
return each;
}
}
throw new IllegalArgumentException();
}
}
分表规则讲解:
- 示例为RangeShardingAlgorithm类型配置进行范围时间段分表配置,简单equey处理逻辑类似,只是shardingValue只有一个值
- 我们的处理是根据传入时间的月份进行按季度匹配对应表名
- 且此处通过dbConfig进行配置相关所有表名,此处一样注意
master1Config此处为主从集群组名,当不需要主从时,此处配置为两个主库名即可
public class UserLogTableRangeShardingAlgorithm implements RangeShardingAlgorithm {
private static final String TblUserLogName = "auth_user_log";
public static final Map dbConfig = new HashMap<>();
static {
dbConfig.put(0, "master1Config." + TblUserLogName+",master2Config."+TblUserLogName);
dbConfig.put(2019, "master1Config.auth_user_log_201903,master1Config.auth_user_log_201904,master2Config.auth_user_log_201903,master2Config.auth_user_log_201904");
}
public static String toUserLogDbConfigString() {
Collection values = dbConfig.values();
if (values.size() > 0) {
StringBuilder stringBuilder = new StringBuilder();
values.stream().forEach(value -> stringBuilder.append(value).append(","));
return stringBuilder.substring(0, stringBuilder.length() - 1);
}
return TblUserLogName;
}
@Override
public Collection doSharding(Collection collection,
RangeShardingValue shardingValue) {
List result = Arrays.asList(TblUserLogName);
Range valueRange = shardingValue.getValueRange();
Timestamp start = valueRange.lowerEndpoint();
Timestamp end = valueRange.upperEndpoint();
shardingTableNames(result, start);
shardingTableNames(result, end);
result.retainAll(collection);
if (CollectionUtils.isEmpty(result)) {
throw new IllegalArgumentException();
}
return result;
}
/**
*根据时间进行分季度分表配置
**/
private void shardingTableNames(List result, Timestamp start) {
String tb_name;
Calendar c = Calendar.getInstance();
c.setTimeInMillis(start.getTime());
int year = c.get(Calendar.YEAR);
int month = c.get(Calendar.MONTH);
if (dbConfig.keySet().contains(year)) {
if (month >= 1 && month <= 3) {
tb_name = TblUserLogName + "_" + year + "01";
result.add(tb_name);
}
if (month >= 4 && month <= 6) {
tb_name = TblUserLogName + "_" + year + "02";
result.add(tb_name);
}
if (month >= 7 && month <= 9) {
tb_name = TblUserLogName + "_" + year + "03";
result.add(tb_name);
}
if (month >= 10 && month <= 12) {
tb_name = TblUserLogName + "_" + year + "04";
result.add(tb_name);
}
}
}
}
总结
到此分库、分表、读写分离的具体配置说明就说完了.shariding-jdbc通过客户端在datasource层进行封装,在sql的执行过程中进行二次封装.实现分库分表规则,简单实用.不想mycat等需要运维配置代理进行维护处理.