1.C++三个特殊的函数(Big Three)
拷贝构造函数,赋值构造函数和析构函数。一般情况下,一个类里面只要有指针,就一定要定义拷贝构造函数和赋值构造函数。系统默认的拷贝构造函数只能对对象进行浅复制,浅复制只是将对象的数据进行拷贝,而没有生成新的内存空间,可以理解为两个对象同时指向同一个内存地址,只是拷贝了指针,这是一种危险的行为,容易造成内存泄漏。而深复制是建立一块新的内存地址,然后将数据拷贝到这个新的内存之中。以拷贝复制为例,进行
String a = b;的深复制行为
Sting &String::operator = (const String &str)
{
if(this == &str)
return *this;
delete []m_data;
m_data = new char[strlen(str.m_data)+1];
strcpy(m_data, str.m_data);
return *this;
}
以上就是一个拷贝赋值函数,首先检测是否为自我赋值(a = a),然后清除要赋值对象里面的数据,然后喂对象分配一块内存,最后将数据赋值到这块内存。这里需要注意的是检测自我赋值,检测自我赋值不仅仅可以提高效率,更重要的一点是能够避免程序出错。如果没有这个功能,当进行 a=a是,由于这是同一个对象,指向的是同一块内存,当执行
delete []m_data时,会将对象内存清除,里面就没有数据,会造成程序运行时出错。
析构函数可以理解为对对象进行收尾工作,当对象所在的作用域结束之后,酒会调用析构函数,系统会有默认的析构函数,但值得注意的是,当构造函数使用了new时,析构函数一定要使用delete,在程序中,一个new,一定要对应一个delete,不然就会造成内存泄漏。
2.堆,栈与内存管理
以前对堆和栈的概念与区别,以及它们要干什么都是混乱的,现在才总算有了一些了解。
栈(Stack),是存在于某个作用域的一块内存,当你调用相应的函数时,函数体本身就会形成一个栈,来放置需要接收的函数,在函数体内声明的仁和变量,其内存块都是取自于栈,但函数调用结束后,系统会自动释放栈的内存,也就是说栈所占用的内存又系统自动管理,当相应的作用域结束后,系统就会自动清理栈的内存。也可以理解为栈内存放的是auto object,系统自动管理对象。
堆(Heap),堆是一块全局的内存空间,可以动态分配内存,是用new,在程序的任意地方都可以得到,在这里再次强调,使用new,就一定要用delete来释放内存,不然将会造成内存泄漏。static local object是存放在堆中,此对象在作用域结束后任然存在,之道程序结束。还有就是global object全局对象。
在这里来简单说一下new和delete的运行机制
new(Complex pc = new Complex(1, 2)):
首先根据数据内容创建一块内存,其实就是在内部调用malloc函数,
void mem = operator new (sizeof(Complex))
然后就是转型,也就是强制类型转换
pc = static_cast
最后就是将数据内容传入到内存中。new简单来说,就是先创建内存,然后调用构造函数。
而delete就恰恰相反,首先调用析构函数,将内存块里面的数据清除,然后再释放内存块。
需要注意的是,动态分配内存块并不是你的数据需要多少,就会给你分配多少,实际是分配的内存块远多于数据所需的内存,用于回收和调试。
还要注意的是,使用new和delete来创建和删除数组时的用法,delete []p,不然将无法释放数组的内存。
还要注意的是,在如果在一个类里面定义了static函数或者数据,那么static数据将与对象脱离,就可以说static数据不受对象限制,当对象被销毁后,static数据还将存在,直到整个程序结束为止。同时,static数据可以直接通过classname来调用,比如
class Account
{
public:
static double m_rate;
static void set_rate(const double &x)
{
m_rate = x;
}
};
int main
{
Account::set_rate(5.0);
Account a;
a.set_rate(7.0);
return 0;
}
3.单例(Singleton)设计模式
单例设计模式在编程中是一种简单,但也是我么常用的一种设计模式,我以前习惯将其理解为就是对对象里的数据进行初始化,现在听了老师讲解后才发现自己的理解太狭隘。
单例模式保证一个类仅有一个实例,并提供一个访问它的全局访问点,也就是说,外界不能创建对象,单例类只有一个自己,只有一个唯一的接口,比如:
class A
{
public:
static A &getInstance() { return a;}
setup() {}
private:
A();
A(const A &rth);
static A a;
}
注意,如果 A &A::getInstance{return a;}创建在外部的话,当没人使用A时,既不存在对象a, 一旦有人使用,那么a就会一直存在,直到整个程序结束。static数据只能用static函数来获取,在上面的class A中,就是用static函数来获取static数据,要注意的是,static函数只能处理static数据,而且static函数没有this 指针。
在程序中,我们通过A::getInstance()来获得对象a,A::getInstance().setup(),来获得数据。
3.类模版 和 函数模版
类模版就是一个类通过绑定不同类型的数据,进行数据处理,比如
template
complex
complex
通过绑定不同的数据类型,来处理相应的数据。
函数模版无需绑定数据类型,它可以对传进来的数据进行实參推导,比如
const T &min(const T &a, T &b){ return b < a ? a:b;}
4.虚函数
虚函数就是最直接的理解就是在函数前面加上virtual关键字的函数,虚函数数的作用在我看来,就是方便子类对父类中函数的修改,方便子类对象和父类对象对同名函数的调用。比如下面的这个例子:
class A
{
public:
void print(){ cout<<"A...... "<
class B:public A
{
public:
void print(){cout<<"B......"<
5.继承
继承是体现C++多态性的一个重要特性,它是is-a的关系,我的理解它就是一种包含的关系,也就是说,子类包含类基类的特性,同时在基类的基础上可以添加有别于基类的行为。
比如下面的UML图
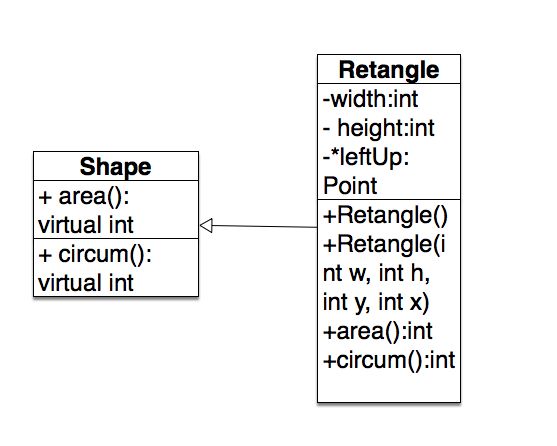
Rectangle类继承了Shape类,那么Retangle继承了Shape类的行为,注意Shape类里面有两个纯虚函数,只要类里面有纯虚函数,那么这个类就是抽象类,抽象类不能定义对象,而且继承了抽象类的子类必须要复写基类里面的纯虚函数,不然子类也会是抽象类。
这里要注意一个,基类里面的非虚函数就是不希望子类复写的函数,而虚函数就是基类希望子类去复写的函数。非虚函数也可以复写,但在父类和子类对象的使用过程中会带来不便,所以建议不要复写基类的非虚函数,如果一定要复写基类里面的函数,就将此函数定义为虚函数。
6.Composition
Composition模式我就把他理解为就是一个组合模式,老师说这是一种has-a 的关系,也就是包含关系,其实上面的UML中Retangle类就包含类一个Point类,完整的UML应该如下:

(由于用的软件问题,组合关系就用黑色箭头代替一下)
7.delagetion(委托设计模式)
委托设计模式就是通过一个中介来实现自己要完成的事。比如你现在租房,你会到58,赶集等网站去寻找房源,然后通过这个中介来同房东交流,当然你也可以直接找房东,但会浪费你的时间,结构图如下
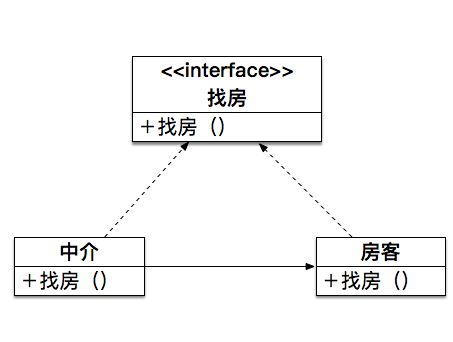
房客通过中介来找房,中介可以同时处理多个房客的需要,这就大量节省了房客的时间,但中介也要收取一定的费用,在委托模式中也一样,消耗一定的性能,但能大大提高程序的效率。