In this chapter we discuss three of the most widely-used classifiers: logistic regression , linear discriminant analysis , and K-nearest neighbors.
Unfortunately, in general there is no natural way to convert a qualitative response variable with more than two levels into a quantitative response that is ready for linear regression.
Logistic Regression
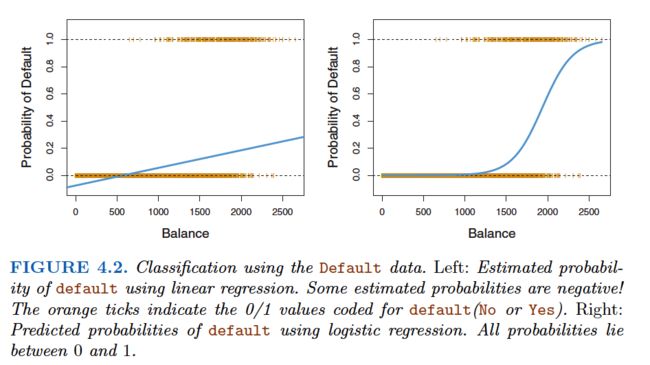
To avoid this problem, we must model p(X) using a function that gives outputs between 0 and 1 for all values of X. Many functions meet this description. In logistic regression, we use the logistic function:
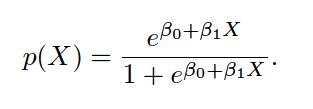
we use a method called maximum likelihood to fit the model.
After a bit of manipulation, we find that:
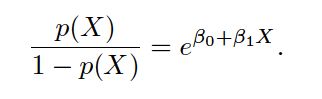
is called the odds
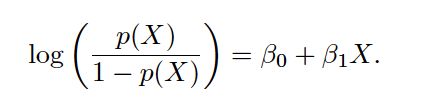
The left-hand side is called the log-odds or logit.(逻辑回归的命名原因在此)
We see that the logistic regression model has a logit that is linear in X.
Estimating the Regression Coefficients
maximum likelihood:This intuition can be formalized using a mathematical equation called a likelihood function
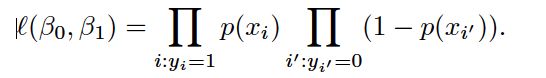
The estimates ˆβ0 and ˆβ1 are chosen to maximize this likelihood function.
Maximum likelihood is a very general approach that is used to fit many of the non-linear models that we examine throughout this book. In the linear regression setting, the least squares approach is in fact a special case of maximum likelihood.
Making Predictions
just calc it.
Multiple Logistic Regression
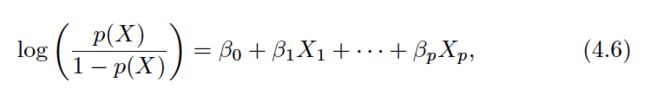
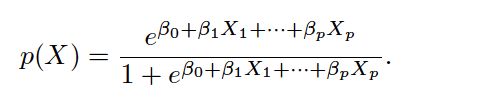
we use the maximum likelihood method to estimate β0, β1, . . . , βp.
Logistic Regression for>2 Response Classes
The two-class logistic regression models discussed in the previous sections have multiple-class extensions, but in practice they tend not to be used all that often. One of the reasons is that the method we discuss in the next section, discriminant analysis, is popular for multiple-class classification. So we do not go into the details of multiple-class logistic regression here, but simply note that such an approach is possible, and that software for it is available in R.(逻辑回归也是可以适用多分类数据集的噢,只是不常用,LDA更常用于多分类数据集)
Linear Discriminant Analysis
In this alternative approach, we model the distribution of the predictors X separately in each of the response classes (i.e. given Y), and then use Bayes’ theorem to flip these around into estimates for Pr(Y= k|X= x ). When these distributions are assumed to be normal, it turns out that the model is very similar in form to logistic regression.
Why do we need another method, when we have logistic regression?
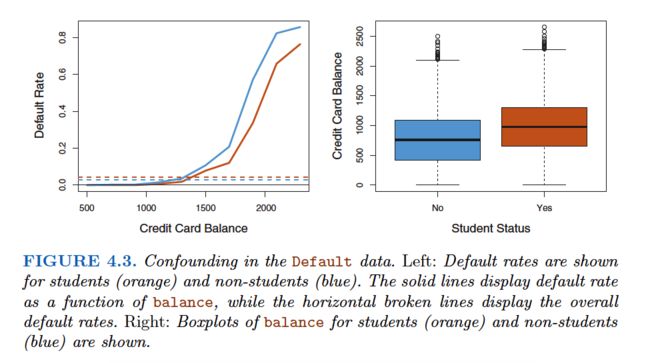
• When the classes are well-separated, the parameter estimates for the logistic regression model are surprisingly unstable. Linear discriminant analysis does not suffer from this problem.(看指数函数的S曲线就知道了)
• If n is small and the distribution of the predictors X is approximately normal in each of the classes, the linear discriminant model is again more stable than the logistic regression model.(训练集比较小而且分类数据分布遵从正太分布时逻辑回归不好使)
• As mentioned in Section 4.3.5, linear discriminant analysis is popular when we have more than two response classes.(多分类)
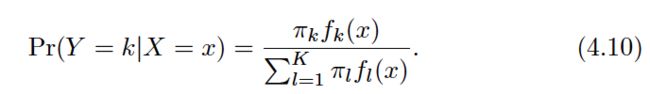
In general, estimating πk is easy if we have a random sample of Ys from the population.(Let πk represent the overall or prior probability that a randomly chosen observation comes from the kth class)
Let fk(X) ≡Pr(X=x|Y=k) denote the density function of X for an observation that comes from the kth class.
Linear Discriminant Analysis for p= 1
Suppose we assume that fk(x) is normal or Gaussian . In the one-dimensional setting, the normal density takes the form:
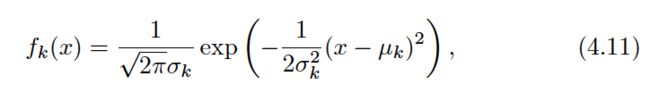
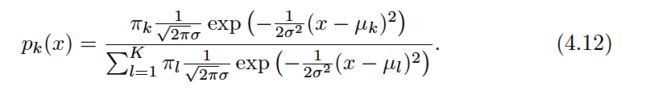
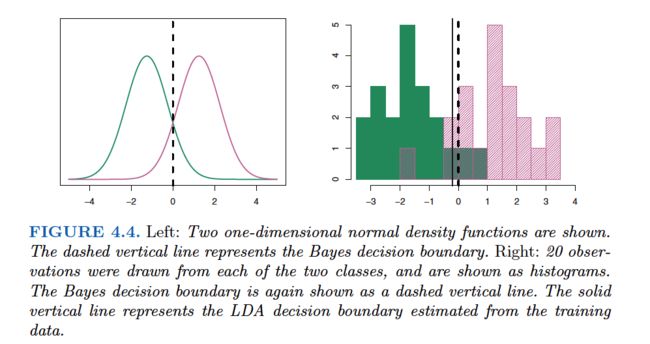
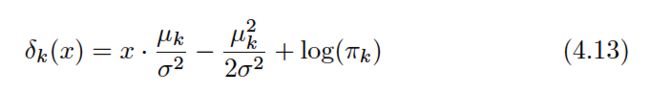
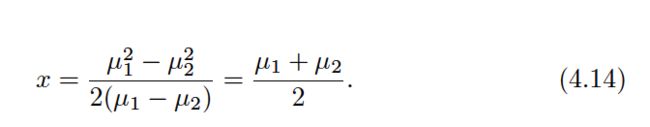
The linear discriminant analysis (LDA) method approximates the Bayes classifier by plugging estimates for πk, μk, and σ2into (4.13). In particular, the following estimates are used:
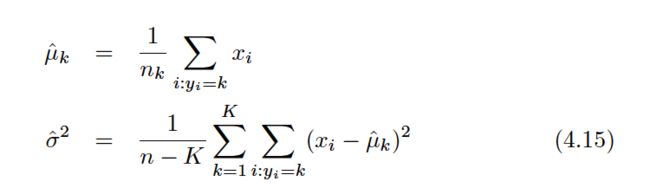


The word linear in the classifier’s name stems from the fact that the discriminant functions ˆδk(x) in (4.17) are linear functions of x(as opposed to a more complex function of x).
To reiterate, the LDA classifier results from assuming that the observations within each class come from a normal distribution with a class-specific mean vector and a common variance σ2, and plugging estimates for these parameters into the Bayes classifier.
Linear Discriminant Analysis for p >1
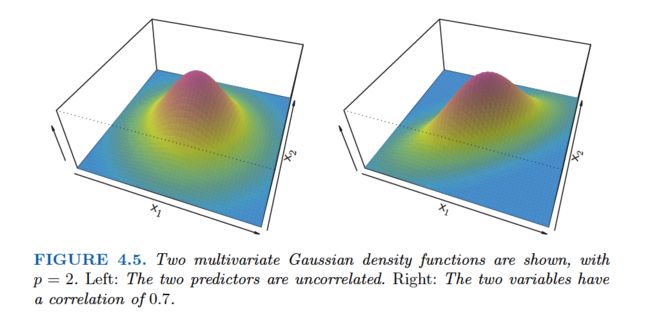
We now extend the LDA classifier to the case of multiple predictors. To do this, we will assume that X= (X1,X2, . . .,Xp) is drawn from a multivariate Gaussian(or multivariate normal) distribution, with a class-specific mean vector and a common covariance matrix.We begin with a brief review of such a distribution.
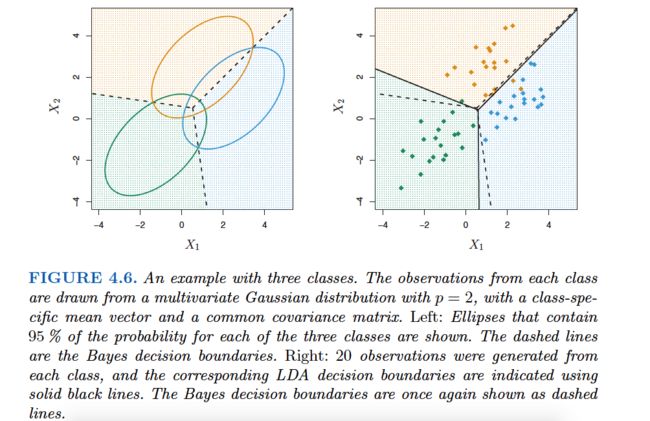
Quadratic Discriminant Analysis
Like LDA, the QDA classifier results from assuming that the observations from each class are drawn from a Gaussian distribution, and plugging estimates for the parameters into Bayes’ theorem in order to perform prediction.
However, unlike LDA, QDA assumes that each class has its own covariance matrix. That is, it assumes that an observation from the kth class is of the formX∼N(μk,Σk), where Σk is a covariance matrix for the kth class. Under this assumption, the Bayes classifier assigns an observation X=x to the class for which
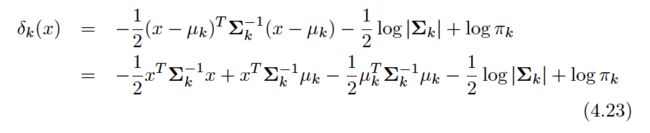
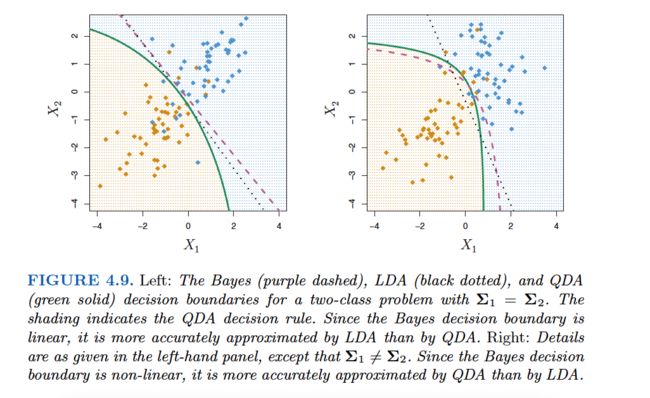
A Comparison of Classification Methods
Though their motivations differ, the logistic regression and LDA methods are closely connected.Consider the two-class setting with p= 1 predictor, and let p1(x ) and p2(x ) = 1−p1(x ) be the probabilities that the observation X= x belongs to class 1 and class 2, respectively. In the LDA framework, we can see from (4.12) to (4.13) (and a bit of simple algebra) that the log odds is given by:
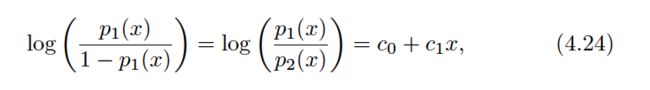
where c0 and c1 are functions ofμ1, μ2, andσ2. From (4.4), we know that in logistic regression.
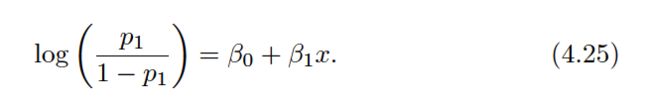
both logistic regression and LDA produce linear decision boundaries. The only difference between the two approaches lies in the fact that β0 and β1 are estimated using maximum likelihood, where as c0 and c1 are computed using the estimated mean and variance from a normal distribution.
This same connection between LDA and logistic regression also holds for multidimensional data with p >1.
Hence KNN is a completely non-parametric approach.
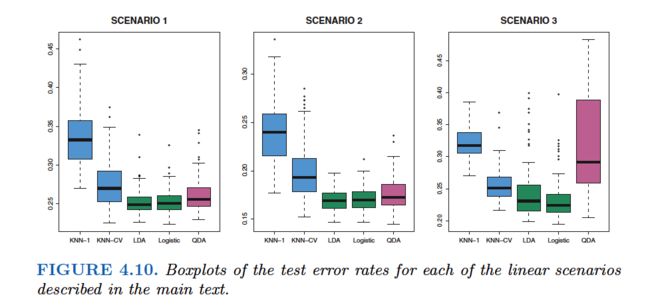
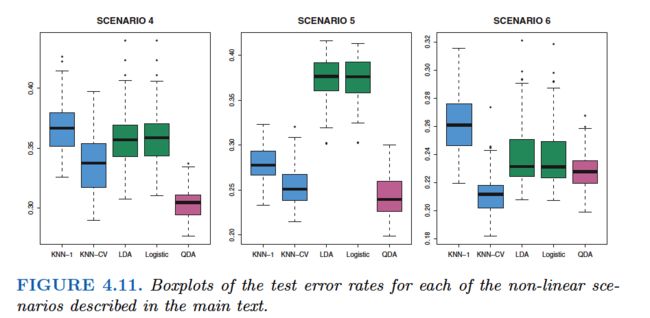
Finally, QDA serves as a compromise between the non-parametric KNN method and the linear LDA and logistic regression approaches.