我是在深入学习 kotlin 时第一次看到协程,作为传统线程模型的进化版,虽说协程这个概念几十年前就有了,但是协程只是在近年才开始兴起,应用的语言有:go 、goLand、kotlin、python , 都是支持协程的,可能不同平台 API 上有差异
首次学习协程可能会费些时间,协程和 thread 类似,但是和 thread 有很大区别,搞懂,学会,熟悉协程在线程上如何运作是要钻研一下的,上手可能不是那么快
- 官方中文文档:kotlin 中文文档
- 简友资料库:JohnnyShieh
这里有个很有建设性意见的例子,Coroutines 代替 rxjava
- Kotlin 1.3 Coroutines+Retrofit+Okhttp使用
怎么理解协程
我们先来把协程这个概念搞懂,不是很好理解,但是也不难理解
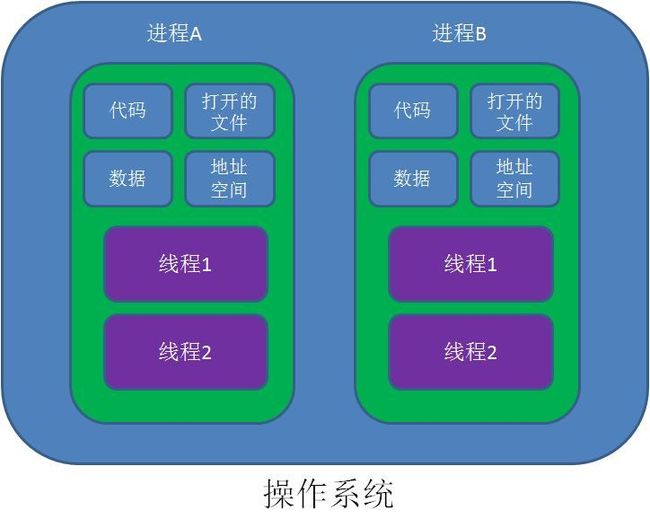
协程 - 也叫微线程,是一种新的多任务并发的操作手段(也不是很新,概念早就有了)
- 特征:协程是运行在单线程中的并发程序
- 优点:省去了传统 Thread 多线程并发机制中切换线程时带来的线程上下文切换、线程状态切换、Thread 初始化上的性能损耗,能大幅度唐提高并发性能
- 漫画版概念解释:漫画:什么是协程?
- 简单理解:在单线程上由程序员自己调度运行的并行计算
下面是关于协程这个概念的一些描述:
协程的开发人员 Roman Elizarov 是这样描述协程的:协程就像非常轻量级的线程。线程是由系统调度的,线程切换或线程阻塞的开销都比较大。而协程依赖于线程,但是协程挂起时不需要阻塞线程,几乎是无代价的,协程是由开发者控制的。所以协程也像用户态的线程,非常轻量级,一个线程中可以创建任意个协程。
Coroutine,翻译成”协程“,初始碰到的人马上就会跟进程和线程两个概念联系起来。直接先说区别,Coroutine是编译器级的,Process和Thread是操作系统级的。Coroutine的实现,通常是对某个语言做相应的提议,然后通过后成编译器标准,然后编译器厂商来实现该机制。Process和Thread看起来也在语言层次,但是内生原理却是操作系统先有这个东西,然后通过一定的API暴露给用户使用,两者在这里有不同。Process和Thread是os通过调度算法,保存当前的上下文,然后从上次暂停的地方再次开始计算,重新开始的地方不可预期,每次CPU计算的指令数量和代码跑过的CPU时间是相关的,跑到os分配的cpu时间到达后就会被os强制挂起。Coroutine是编译器的魔术,通过插入相关的代码使得代码段能够实现分段式的执行,重新开始的地方是yield关键字指定的,一次一定会跑到一个yield对应的地方
对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。协程能保留上一次调用时的状态,不需要像线程一样用回调函数,所以性能上会有提升。缺点是本质是个单线程,不能利用到单个CPU的多个核
协程和线程的对比:
-
Thread - 线程拥有独立的栈、局部变量,基于进程的共享内存,因此数据共享比较容易,但是多线程时需要加锁来进行访问控制,不加锁就容易导致数据错误,但加锁过多又容易出现死锁。线程之间的调度由内核控制(时间片竞争机制),程序员无法介入控制(
即便我们拥有sleep、yield这样的API,这些API只是看起来像,但本质还是交给内核去控制,我们最多就是加上几个条件控制罢了),线程之间的切换需要深入到内核级别,因此线程的切换代价比较大,表现在:
* 线程对象的创建和初始化
* 线程上下文切换
* 线程状态的切换由系统内核完成
* 对变量的操作需要加锁
-
Coroutine 协程是跑在线程上的优化产物,被称为轻量级 Thread,拥有自己的栈内存和局部变量,共享成员变量。传统 Thread 执行的核心是一个while(true) 的函数,本质就是一个耗时函数,Coroutine 可以用来直接标记方法,由程序员自己实现切换,调度,不再采用传统的时间段竞争机制。在一个线程上可以同时跑多个协程,同一时间只有一个协程被执行,在单线程上模拟多线程并发,协程何时运行,何时暂停,都是有程序员自己决定的,使用:
yield/resumeAPI,优势如下:- 因为在同一个线程里,协程之间的切换不涉及线程上下文的切换和线程状态的改变,不存在资源、数据并发,所以不用加锁,只需要判断状态就OK,所以执行效率比多线程高很多
-
协程是非阻塞式的(也有阻塞API),一个协程在进入阻塞后不会阻塞当前线程,当前线程会去执行其他协程任务
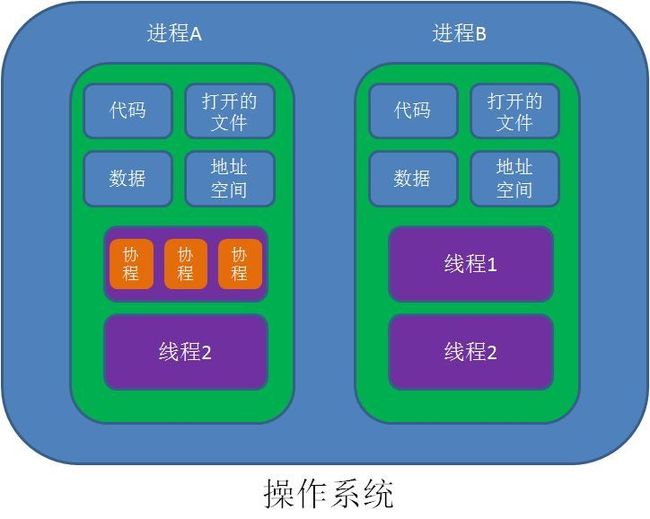
程序员能够控制协程的切换,是通过yield API 让协程在空闲时(比如等待io,网络数据未到达)放弃执行权,然后在合适的时机再通过resume API 唤醒协程继续运行。协程一旦开始运行就不会结束,直到遇到yield交出执行权。Yield、resume 这一对 API 可以非常便捷的实现异步,这可是目前所有高级语法孜孜不倦追求的
拿 python 代码举个例子,在一个线程里运行下面2个方法:
def A():
print '1'
print '2'
print '3'
def B():
print 'x'
print 'y'
print 'z'
假设由协程执行,每个方法都用协程标记,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:1 2 x y 3 z
添加依赖
在 module 项目中添加下面的依赖:
kotlin{
experimental {
coroutines 'enable'
}
}
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.1.1'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.1.1'
kotlin Coroutine 部分在最近几个版本变化较大,推荐大家使用 kotlin 的最新版本 1.3.21,同时 kotlin 1.3.21 版本 kotlin-stdlib-jre7 支持库更新为 kotlin-stdlib-jdk7
buildscript {
ext.kotlin_version = '1.3.21'
......
}
implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlin_version"
kotlin 种协程的概念
文章开头已经介绍了协程的概念,但毕竟平台不同,也许多协程也有不一样的地方,我们还是看看 kotlin 中的协程的描述,下面来自官方文档:
协程通过将复杂性放入库来简化异步编程。程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。该库可以将用户代码的相关部分包装为回调、订阅相关事件、在不同线程(甚至不同机器)上调度执行,而代码则保持如同顺序执行一样简单
总结下,协程是跑在线程上的,一个线程可以同时跑多个协程,每一个协程则代表一个耗时任务,我们手动控制多个协程之间的运行、切换,决定谁什么时候挂起,什么时候运行,什么时候唤醒,而不是 Thread 那样交给系统内核来操作去竞争 CPU 时间片
协程在线程中是顺序执行的,既然是顺序执行的那怎么实现异步,这自然是有手段的。Thread 中我们有阻塞、唤醒的概念,协程里同样也有,挂起等同于阻塞,区别是 Thread 的阻塞是会阻塞当前线程的(此时线程只能空耗 cpu 时间而不能执行其他计算任务,是种浪费),而协程的挂起不会阻塞线程。当线程接收到某个协程的挂起请求后,会去执行其他计算任务,比如其他协程。协程通过这样的手段来实现多线程、异步的效果,在思维逻辑上同 Thread 的确有比较大的区别,大家需要适应下思路上的变化
suspend 关键字
协程天然亲近方法,协程表现为标记、切换方法、代码段,协程里使用 suspend 关键字修饰方法,既该方法可以被协程挂起,没用suspend修饰的方法不能参与协程任务,suspend修饰的方法只能在协程中只能与另一个suspend修饰的方法交流
suspend fun requestToken(): Token { ... } // 挂起函数
suspend fun createPost(token: Token, item: Item): Post { ... } // 挂起函数
fun postItem(item: Item) {
GlobalScope.launch { // 创建一个新协程
val token = requestToken()
val post = createPost(token, item)
processPost(post)
// 需要异常处理,直接加上 try/catch 语句即可
}
}
创建协程
kotlin 里没有 new ,自然也不像 JAVA 一样 new Thread,另外 kotlin 里面提供了大量的高阶函数,所以不难猜出协程这里 kotlin 也是有提供专用函数的。kotlin 中 GlobalScope 类提供了几个携程构造函数:
- launch - 创建协程
- async - 创建带返回值的协程,返回的是 Deferred 类
- withContext - 不创建新的协程,在指定协程上运行代码块
- runBlocking - 不是 GlobalScope 的 API,可以独立使用,区别是 runBlocking 里面的 delay 会阻塞线程,而 launch 创建的不会
kotlin 在 1.3 之后要求协程必须由 CoroutineScope 创建,CoroutineScope 不阻塞当前线程,在后台创建一个新协程,也可以指定协程调度器。比如 CoroutineScope.launch{} 可以看成 new Coroutine
来看一个最简单的例子:
Log.d("AA", "协程初始化开始,时间: " + System.currentTimeMillis())
GlobalScope.launch(Dispatchers.Unconfined) {
Log.d("AA", "协程初始化完成,时间: " + System.currentTimeMillis())
for (i in 1..3) {
Log.d("AA", "协程任务1打印第$i 次,时间: " + System.currentTimeMillis())
}
delay(500)
for (i in 1..3) {
Log.d("AA", "协程任务2打印第$i 次,时间: " + System.currentTimeMillis())
}
}
Log.d("AA", "主线程 sleep ,时间: " + System.currentTimeMillis())
Thread.sleep(1000)
Log.d("AA", "主线程运行,时间: " + System.currentTimeMillis())
for (i in 1..3) {
Log.d("AA", "主线程打印第$i 次,时间: " + System.currentTimeMillis())
}
协程初始化开始,时间: 1553752816027
协程初始化完成,时间: 1553752816060
协程任务1打印第1 次,时间: 1553752816060
协程任务1打印第2 次,时间: 1553752816060
协程任务1打印第3 次,时间: 1553752816060
主线程 sleep ,时间: 1553752816063
协程任务2打印第1 次,时间: 1553752816567
协程任务2打印第2 次,时间: 1553752816567
协程任务2打印第3 次,时间: 1553752816567
主线程运行,时间: 1553752817067
主线程打印第1 次,时间: 1553752817068
主线程打印第2 次,时间: 1553752817068
主线程打印第3 次,时间: 1553752817068
以 launch 函数为例
launch 函数定义:
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
launch 是个扩展函数,接受3个参数,前面2个是常规参数,最后一个是个对象式函数,这样的话 kotlin 就可以使用以前说的闭包的写法:() 里面写常规参数,{} 里面写函数式对象的实现,就像上面的例子一样,刚从 java 转过来的朋友看着很别扭不是,得适应
GlobalScope.launch(Dispatchers.Unconfined) {...}
我们需要关心的是 launch 的3个参数和返回值 Job:
- CoroutineContext - 可以理解为协程的上下文,在这里我们可以设置 CoroutineDispatcher 协程运行的线程调度器,有 4种线程模式:
- Dispatchers.Default
- Dispatchers.IO -
- Dispatchers.Main - 主线程
- Dispatchers.Unconfined - 没指定,就是在当前线程
不写的话就是 Dispatchers.Default 模式的,或者我们可以自己创建协程上下文,也就是线程池,newSingleThreadContext 单线程,newFixedThreadPoolContext 线程池,具体的可以点进去看看,这2个都是方法
val singleThreadContext = newSingleThreadContext("aa")
GlobalScope.launch(singleThreadContext) { ... }
- CoroutineStart - 启动模式,默认是DEAFAULT,也就是创建就启动;还有一个是LAZY,意思是等你需要它的时候,再调用启动
- DEAFAULT - 模式模式,不写就是默认
- ATOMIC -
- UNDISPATCHED
- LAZY - 懒加载模式,你需要它的时候,再调用启动,看这个例子
var job:Job = GlobalScope.launch( start = CoroutineStart.LAZY ){
Log.d("AA", "协程开始运行,时间: " + System.currentTimeMillis())
}
Thread.sleep( 1000L )
// 手动启动协程
job.start()
- block - 闭包方法体,定义协程内需要执行的操作
- Job - 协程构建函数的返回值,可以把 Job 看成协程对象本身,协程的操作方法都在 Job 身上了
- job.start() - 启动协程,除了 lazy 模式,协程都不需要手动启动
- job.join() - 等待协程执行完毕
- job.cancel() - 取消一个协程
- job.cancelAndJoin() - 等待协程执行完毕然后再取消
GlobalScope.async
async 同 launch 唯一的区别就是 async 是有返回值的,看下面的例子:
GlobalScope.launch(Dispatchers.Unconfined) {
val deferred = GlobalScope.async{
delay(1000L)
Log.d("AA","This is async ")
return@async "taonce"
}
Log.d("AA","协程 other start")
val result = deferred.await()
Log.d("AA","async result is $result")
Log.d("AA","协程 other end ")
}
Log.d("AA", "主线程位于协程之后的代码执行,时间: ${System.currentTimeMillis()}")
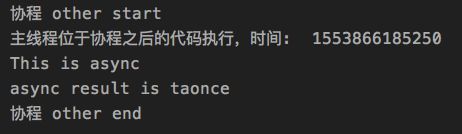
async 返回的是 Deferred 类型,Deferred 继承自 Job 接口,Job有的它都有,增加了一个方法 await ,这个方法接收的是 async 闭包中返回的值,async 的特点是不会阻塞当前线程,但会阻塞所在协程,也就是挂起
但是注意啊,async 并不会阻塞线程,只是阻塞锁调用的协程
runBlocking
runBlocking 和 launch 区别的地方就是 runBlocking 的 delay 方法是可以阻塞当前的线程的,和Thread.sleep() 一样,看下面的例子:
fun main(args: Array) {
runBlocking {
// 阻塞1s
delay(1000L)
println("This is a coroutines ${TimeUtil.getTimeDetail()}")
}
// 阻塞2s
Thread.sleep(2000L)
println("main end ${TimeUtil.getTimeDetail()}")
}
~~~~~~~~~~~~~~log~~~~~~~~~~~~~~~~
This is a coroutines 11:00:51
main end 11:00:53
runBlocking 通常的用法是用来桥接普通阻塞代码和挂起风格的非阻塞代码,在 runBlocking 闭包里面启动另外的协程,协程里面是可以嵌套启动别的协程的
协程的挂起和恢复
前面说过,协程的特点就是多个协程可以运行在一个线程内,单个协程挂起后不会阻塞当前线程,线程还可以继续执行其他任务。学习协程最大的难点是搞清楚协程是如何运行的、何时挂起、何时恢复,多个协程之间的组织运行、协程和线程之间的组织运行
1. 协程执行时, 协程和协程,协程和线程内代码是顺序运行的
这点是和 thread 最大的不同,thread 线程之间采取的是竞争 cpu 时间段的方法,谁抢到谁运行,由系统内核控制,对我们来说是不可见不可控的。协程不同,协程之间不用竞争、谁运行、谁挂起、什么时候恢复都是由我们自己控制的
最简单的协程运行模式,不涉及挂起时,谁写在前面谁先运行,后面的等前面的协程运行完之后再运行。涉及到挂起时,前面的协程挂起了,那么线程不会空闲,而是继续运行下一个协程,而前面挂起的那个协程在挂起结速后不会马上运行,而是等待当前正在运行的协程运行完毕后再去执行
典型的例子:
GlobalScope.launch(Dispatchers.Unconfined) {
for (i in 1..6) {
Log.d("AA", "协程任务打印第$i 次,时间: ${System.currentTimeMillis()}")
}
}
for (i in 1..8) {
Log.d("AA", "主线程打印第$i 次,时间: ${System.currentTimeMillis()}")
}
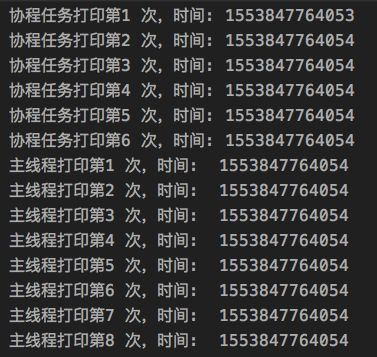
2. 协程挂起时,就不会执行了,而是等待挂起完成且线程空闲时才能继续执行
大家还记得 suspend 这个关键字吗,suspend 表示挂起的意思,用来修饰方法的,一个协程内有多个 suspend 修饰的方法顺序书写时,代码也是顺序运行的,为什么,suspend 函数会将整个协程挂起,而不仅仅是这个 suspend 函数
-
1. 单携程内多 suspend 函数运行
suspend 修饰的方法挂起的是协程本身,而非该方法,注意这点,看下面的代码体会下
suspend fun getToken(): String {
delay(300)
Log.d("AA", "getToken 开始执行,时间: ${System.currentTimeMillis()}")
return "ask"
}
suspend fun getResponse(token: String): String {
delay(100)
Log.d("AA", "getResponse 开始执行,时间: ${System.currentTimeMillis()}")
return "response"
}
fun setText(response: String) {
Log.d("AA", "setText 执行,时间: ${System.currentTimeMillis()}")
}
// 运行代码
GlobalScope.launch(Dispatchers.Main) {
Log.d("AA", "协程 开始执行,时间: ${System.currentTimeMillis()}")
val token = getToken()
val response = getResponse(token)
setText(response)
}
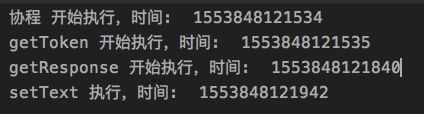
在 getToken 方法将协程挂起时,getResponse 函数永远不会运行,只有等 getToken 挂起结速将协程恢复时才会运行
2. 多协程间 suspend 函数运行
GlobalScope.launch(Dispatchers.Unconfined){
var token = GlobalScope.async(Dispatchers.Unconfined) {
return@async getToken()
}.await()
var response = GlobalScope.async(Dispatchers.Unconfined) {
return@async getResponse(token)
}.await()
setText(response)
}
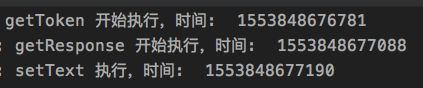
注意我外面要包裹一层 GlobalScope.launch,要不运行不了。这里我们搞了2个协程出来,但是我们在这里使用了await,这样就会阻塞外部协程,所以代码还是按顺序执行的。这样适用于多个同级 IO 操作的情况,这样写比 rxjava 要省事不少
3. 协程挂起后何时恢复
这个问题值得我们研究,毕竟代码运行是负载的,协程之外线程里肯定还有需要执行的代码,我们来看看前面的代码在挂起后何时才能恢复执行。我们把上面的方法延迟改成 1ms ,2ms
suspend fun getToken(): String {
delay(1)
Log.d("AA", "getToken 开始执行,时间: ${System.currentTimeMillis()}")
return "ask"
}
suspend fun getResponse(token: String): String {
delay(2)
Log.d("AA", "getResponse 开始执行,时间: ${System.currentTimeMillis()}")
return "response"
}
fun setText(response: String) {
Log.d("AA", "setText 执行,时间: ${System.currentTimeMillis()}")
}
GlobalScope.launch(Dispatchers.Unconfined) {
Log.d("AA", "协程 开始执行,时间: ${System.currentTimeMillis()}")
val token = getToken()
val response = getResponse(token)
setText(response)
}
for (i in 1..10) {
Log.d("AA", "主线程打印第$i 次,时间: ${System.currentTimeMillis()}")
}
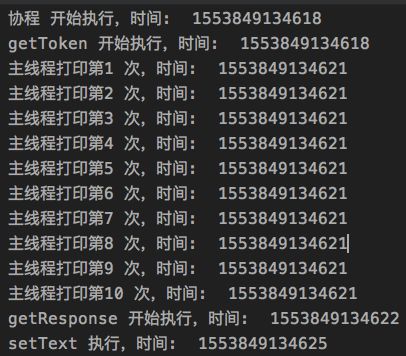
协程挂起后,虽然延迟的时间到了,但是还得等到线程空闲时才能继续执行,这里要注意,协程可没有竞争 cpu 时间段,协程挂起后即便可以恢复执行了也不是马上就能恢复执行,需要我们自己结合上下文代码去判断,这里写不好是要出问题的
4. 协程挂起后再恢复时在哪个线程运行
为什么要写这个呢,在 Thread 中不存在这个问题,但是协程中有句话这样说的:哪个线程恢复的协程,协程就运行在哪个线程中,我们分别对 kotlin 提供的 3个协程调度器测试一下。我们用这段代码测试,分别设置 3个协程调度器
GlobalScope.launch(Dispatchers.Main){
Log.d("AA", "协程测试 开始执行,线程:${Thread.currentThread().name}")
var token = GlobalScope.async(Dispatchers.Unconfined) {
return@async getToken()
}.await()
var response = GlobalScope.async(Dispatchers.Unconfined) {
return@async getResponse(token)
}.await()
setText(response)
}
Log.d("AA", "主线程协程后面代码执行,线程:${Thread.currentThread().name}")
-
Dispatchers.Main

看来 Dispatchers.Main 这个调度器在协程挂起后会一直跑在主线程上,但是有一点注意啊,主线程中写在程后面的代码先执行了,这就有点坑了,要注意啊,Dispatchers.Main 是以给主线程 handle 添加任务的方式现实在主线程上的运行的 -
Dispatchers.Unconfined
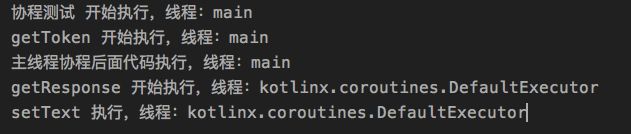
Dispatchers.Unconfined 在首次挂起之后再恢复运行,所在线程已经不是首次运行时的主线程了,而是默认线程池中的线程,这里要特别注意啊,看来协程的唤醒不是那么简单的,协程内部做了很多工作 -
Dispatchers.IO
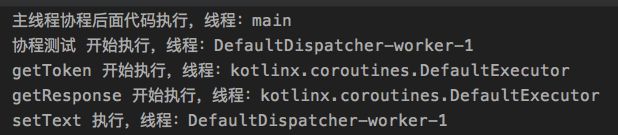
看来 Dispatchers.IO 这个调度器在协程挂起后,也是切到默认线程池去了,不过最后又切回最开始的 IO 线程了
注意协程内部,若是在前面有代码切换了线程,后面的代码若是没有指定线程,那么就是运行在这个切换到的线程上的,所以大家看上面的测试结果,setText 执行的线程都和上一个方法一样
我们最好给异步任务在外面套一个协程,这样我们可以挂挂起整个异步任务,然后给每段代码指定运行线程调度器,这样省的因为协程内部挂起恢复变更线程而带来的问题
在 Kotlin Coroutines封装异步回调、协程间关系及协程的取消 一文中,作者分析了源码,非 Dispatchers.Main 调度器的协程,会在协程挂起后把协程当做一个任务 DelayedResumeTask 放到默认线程池 DefaultExecutor 队列的最后,在延迟的时间到达才会执行恢复协程任务。虽然多个协程之间可能不是在同一个线程上运行的,但是协程内部的机制可以保证我们书写的协程是按照我们指定的顺序或者逻辑自行
看个例子:
suspend fun getToken(): String {
Log.d("AA", "getToken start,线程:${Thread.currentThread().name}")
delay(100)
Log.d("AA", "getToken end,线程:${Thread.currentThread().name}")
return "ask"
}
suspend fun getResponse(token: String): String {
Log.d("AA", "getResponse start,线程:${Thread.currentThread().name}")
delay(200)
Log.d("AA", "getResponse end,线程:${Thread.currentThread().name}")
return "response"
}
fun setText(response: String) {
Log.d("AA", "setText 执行,线程:${Thread.currentThread().name}")
}
// 实际运行
GlobalScope.launch(Dispatchers.IO) {
Log.d("AA", "协程测试 开始执行,线程:${Thread.currentThread().name}")
var token = GlobalScope.async(Dispatchers.IO) {
return@async getToken()
}.await()
var response = GlobalScope.async(Dispatchers.IO) {
return@async getResponse(token)
}.await()
setText(response)
}
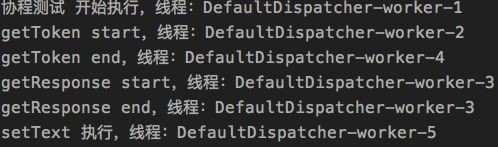
5. relay、yield 区别
relay 和 yield 方法是协程内部的操作,可以挂起协程,区别是 relay 是挂起协程并经过执行时间恢复协程,当线程空闲时就会运行协程;yield 是挂起协程,让协程放弃本次 cpu 执行机会让给别的协程,当线程空闲时再次运行协程。我们只要使用 kotlin 提供的协程上下文类型,线程池是有多个线程的,再次执行的机会很快就会有的。
除了 main 类型,协程在挂起后都会封装成任务放到协程默认线程池的任务队列里去,有延迟时间的在时间过后会放到队列里去,没有延迟时间的直接放到队列里去
6. 协程的取消
我们在创建协程过后可以接受一个 Job 类型的返回值,我们操作 job 可以取消协程任务,job.cancel 就可以了
// 协程任务
job = GlobalScope.launch(Dispatchers.IO) {
Log.d("AA", "协程测试 开始执行,线程:${Thread.currentThread().name}")
var token = GlobalScope.async(Dispatchers.IO) {
return@async getToken()
}.await()
var response = GlobalScope.async(Dispatchers.IO) {
return@async getResponse(token)
}.await()
setText(response)
}
// 取消协程
job?.cancel()
Log.d("AA", "btn_right 结束协程")
协程的取消有些特质,因为协程内部可以在创建协程的,这样的协程组织关系可以称为父协程,子协程:
- 父协程手动调用 cancel() 或者异常结束,会立即取消它的所有子协程
- 父协程必须等待所有子协程完成(处于完成或者取消状态)才能完成
- 子协程抛出未捕获的异常时,默认情况下会取消其父协程
现在问题来了,在 Thread 中我们想关闭线程有时候也不是掉个方法就行的,需要我们自行在线程中判断县城是不是已经结束了。在协程中一样,cancel 方法只是修改了协程的状态,在协程自身的方法比如 realy,yield 等中会判断协程的状态从而结束协程,但是若是在协程我们没有用这几个方法怎么办,比如都是逻辑代码,这时就要我们自己手动判断了,使用 job.isActive ,isActive 是个标记,用来检查协程状态
其他内容
我也是初次学习使用协程,这里放一些暂时没高彻底的内容
- Mutex 协程互斥锁
线程中锁都是阻塞式,在没有获取锁时无法执行其他逻辑,而协程可以通过挂起函数解决这个,没有获取锁就挂起协程,获取后再恢复协程,协程挂起时线程并没有阻塞可以执行其他逻辑。这种互斥锁就是 Mutex,它与 synchronized 关键字有些类似,还提供了 withLock 扩展函数,替代常用的 mutex.lock; try {...} finally { mutex.unlock() }
更多的使用经验就要大家自己取找找了
fun main(args: Array) = runBlocking {
val mutex = Mutex()
var counter = 0
repeat(10000) {
GlobalScope.launch {
mutex.withLock {
counter ++
}
}
}
println("The final count is $counter")
}
协程应用
- 协程请求网络数据
我们用带返回值的协程 GlobalScope.async 在 IO 线程中去执行网络请求,然后通过 await 返回请求结果,用launch 在主线程中更新UI就行了,注意外面用 runBlocking 包裹
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
coroutine.setOnClickListener { click() }
}
private fun click() = runBlocking {
GlobalScope.launch(Dispatchers.Main) {
coroutine.text = GlobalScope.async(Dispatchers.IO) {
// 比如进行了网络请求
// 放回了请求后的结构
return@async "main"
}.await()
}
}
}
- 使用Kotlin的协程实现简单的异步加载