1 准备工作
1.1 节点准备
在开始安装系统之前,我们需要先准备5个节点,他们均通过CentOS 7 Minimal方式安装。网络及系统规划如下:
| 主机名称 | IP地址 | 操作系统 | 身份 |
|---|---|---|---|
| master | 192.168.137.100 | CentOS 7 | NameNode、ResourceManager、NtpServer |
| secondary | 192.168.137.101 | CentOS 7 | SecondaryNameNode、NodeManager |
| slave1 | 192.168.137.102 | CentOS 7 | DataNode、NodeManager |
| slave2 | 192.168.137.103 | CentOS 7 | DataNode、NodeManager |
| slave3 | 192.168.137.104 | CentOS 7 | DataNode、NodeManager |
| 主机 | NN | DN | RM | NM | Hive |
|---|---|---|---|---|---|
| master | Y | Y | Y | ||
| secondary | Y | Y | Y | ||
| slave1 | Y | Y | |||
| slave2 | Y | Y | |||
| slave3 | Y | Y |
1.2 系统架构
在开始配置master和slave节点之前,了解Hadoop集群的不同组件十分重要。
1.2.1 Master ——NameNode
主节点上主要包括了分布式文件系统、资源调度。它主要包括两个守护进程:
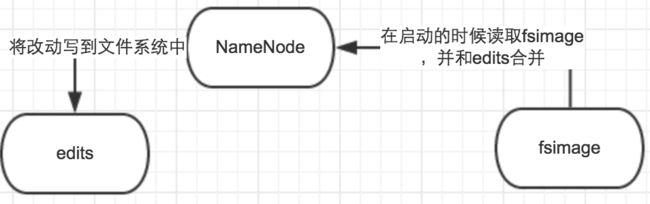
1、NameNode
主要用来管理分布式文件系统,保存HDFS的元数据信息,比如命名空间信息、块信息等。类似于Linux Ext4文件系统的inode信息,Windows FAT文件系统的文件分配表。
当它运行的时候,这些信息是放在内存中的,只有重启的时候,才会将这些信息持久化到磁盘中。
2、ResourceManager
通过YARN来管理资源,让分布式系统中的任务,可以在各个slave节点上正常执行。
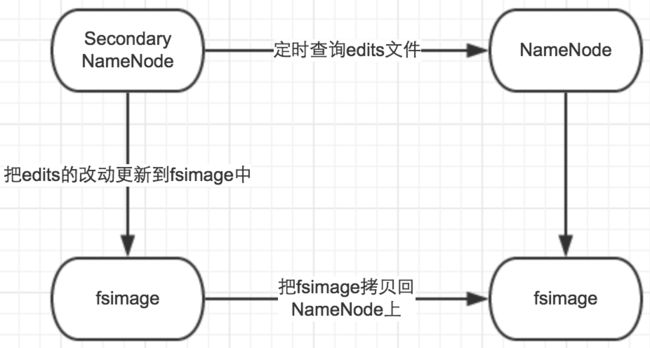
1.2.2 Secondary——NameNode
单从名字上,它好像是Master NameNode的备份,实际上不是,它是用来在系统中提供CheckPoint Node——辅助NameNode正常工作的。
1.2.3 slave——数据节点
数据节点主要用来保存实际的数据,以及运行各种任务。一般也包括两个守护进程:
1、DataNode
从物理层面负责数据的存储。
2、NodeManager
管理节点上任务的执行。
2. 系统安装
为了方便,建议大家使用Vmware虚拟机安装——可以安装一个系统,装好必要的软件JDK并设置好环境变量之后,再克隆生成其他几个。
2.1 系统准备
CentOS下载: http://mirrors.163.com/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1804.iso
VMware Workstation Pro v14.0下载: https://download3.vmware.com/software/wkst/file/VMware-workstation-full-14.0.0-6661328.exe
序列号:**FF31K-AHZD1-H8ETZ-8WWEZ-WUUVA**
2.2 系统安装
2.2.1 安装CentOS 7
安装5台CentOS系统,名称分别为master、secondary、slave1、slave2和slave3。
2.2.2 创建用户并设置密码
在每台电脑上,分别执行以下指令创建用户,设置密码:
useradd -m hadoop -G hadoop -s /bin/bash
passwd hadoop
2.2.3 配置网络
我们通过手工方式来设置电脑的IP地址。注意:每台电脑的IP地址应该是不一致的。
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # 静态IP地址
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=9b6a5e1f-fd3b-4324-ab4c-7b2be4846ca8
DEVICE=ens33
ONBOOT=yes # 开机自动启用
IPADDR="192.168.137.100" # IP地址(同一网络中,每台应该不一致)
PREFIX="24"
GATEWAY="192.168.137.2" # 网关
DNS1="61.128.192.68" # DNS服务器
ZONE=public
2.2.4 配置主机名
编辑每台电脑上的/etc/hostname,依次设置为:
master
master
secondary
secondary
slave1
slave1
slave2
slave2
slave3
slave3
2.2.5 配置主机域名解析
将每台电脑上的/etc/hosts,全部按照以下设置(全都一样):
192.168.137.100 master
192.168.137.101 secondary
192.168.137.102 slave1
192.168.137.103 slave2
192.168.137.104 slave3
2.3 软件安装
2.3.1 Java安装
执行以下指令,安装JDK(Java Development Kit)——Hadoop运行必备。
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
yum install wget
yum install ntp
2.3.2 设置Java环境变量
先编辑/etc/profile,在文件最后加入以下内容:
# Setting Java Home Environment
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
export PATH=$PATH:$JAVA_HOME/bin
然后执行:
source /etc/profile
java -version
如果看到以下信息,则说明JDK安装成功:

2.4网络设置
2.4.1 关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
2.4.2 关闭SELinux
SELinux是用来加强Linux安全的一种机制,不过在使用hadoop的时候,最好在每台电脑上都关闭它:
1、临时关闭
命令行执行:
setenforce 0
2、永久关闭
编辑/etc/selinux/config文件,将:
SELINUX=enforcing
修改为:
SELINUX=disable
重启计算机之后,即永久生效。
2.4.3 设置免密登录
Hadoop集群的启动,是master来自动控制其他计算机的。为了达到这个目标,我们首先要在master上可以不用输入密码通过ssh登录secondary、slave1、slave2和slave3计算机。
1、设置密钥
在master电脑上,执行以下指令生成密钥(ssh-keygen的生成步骤比较多,可以直接按回车):
ssh-keygen -t rsa
2、分发密钥
接下来分发密钥到每台电脑上(包括本机的Master):
ssh-copy-id master
ssh-copy-id secondary
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
3、测试免密登录
在master电脑上,执行:
ssh master
ssh secondary
ssh slave1
ssh slave2
ssh slave3
如果可以全部不用输入密码访问,则大功告成。
3 安装Hadoop
绝大多数朋友采用的Hadoop安装方式,都是通过手工方式安装的,本文也是如此。
3.0 准备hadoop安装目录
在每台电脑上,执行以下指令准备hadoop安装目录:
sudo mkdir -p /opt/hadoop
sudo chown -R hadoop /opt/hadoop
3.1 下载hadoop
hadoop目前的最新版本,是3.0.1。所有的版本,都可以在 这里下载。
这个压缩包里面,已经包括了Hadoop HDFS、Yarn、Map Reduce等各种组件,我们不需要单独下载。
cd /home/hadoop
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gz
sudo mkdir -p /opt/hadoop
sudo chown -R hadoop /opt/hadoop
3.2 解压缩
tar zxvf hadoop-3.0.1.tar.gz
这样一来,在/home/hadoop/下会出现一个hadoop-3.0.1子目录,Hadoop的所有组件都在这个目录中——它就是Hadoop系统的家目录,将它拷贝到/opt/hadoop下。
mv hadoop-3.0.1/* /opt/hadoop/
3.3 配置HDFS运行环境
同样,编辑/etc/profile。在文件的最后,加入以下内容:
# Hadoop Environment Variables
export HADOOP_HOME=/opt/hadoop/
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib:$JRE_HOME/ lib:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*:$HADOOP_HOME/share/hadoop/mapreduce/*
3.4 配置Hadoop
hadoop的配置文件,都位于$HADOOP_HOME/etc/hadoop目录下。
3.4.1 hadoop-env.sh
用vi编辑hadoop-env.sh文件。
vi /opt/modules/hadoop/etc/hadoop/hadoop-env.sh
配置JAVA_HOME变量:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
3.4.1 core-site.xml
用vi编辑core-site.xml文件。
vi $HADOOP_HOME/etc/hadoop/core-site.xml
具体配置信息如下:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/home/hadoop/data/hadoop
3.4.2 hdfs-site.xml
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
具体配置信息如下:
dfs.namenode.secondary.http-address
master:50090
dfs.replication
2
dfs.namenode.name.dir
file:/home/hadoop/data/hadoop/dfs/name
dfs.datanode.data.dir
file:/home/hadoop/data/hadoop/dfs/data
dfs.secondary.http.address
secondary:50090
3.4.3 配置slaves
在/opt/hadoop/etc/hadoop/slaves(hadoop 2.x及以前的版本,文件名为slaves, 3.x之后为workers,hostname或者IP地址,一行一个:
vi $HADOOP_HOME/etc/hadoop/slaves
slave1
slave2
slave3
3.4.4 分发
1、创建需要分发配置文件的机器列表 /opt/hadoop/machines,包括如下内容:
secondary
slave1
slave2
slave3
2、分发hadoop
for x in `cat /opt/hadoop/machines` ; \
do echo $x ; \
scp -r /opt/hadoop/ $x:/opt/hadoop/ ; \
done;
3.4.5 运行HDFS
1、格式化hdfs文件系统
在master上,执行:
hdfs namenode -format
格式化文件系统。
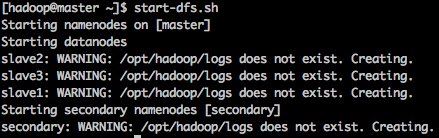
2、启动hdfs服务
在hadoop-master上,执行:
start-dfs.sh
你会看到启动了一个NameNode,一个Secondary NameNode和3个DataNode。
3.4.4 测试启动成功
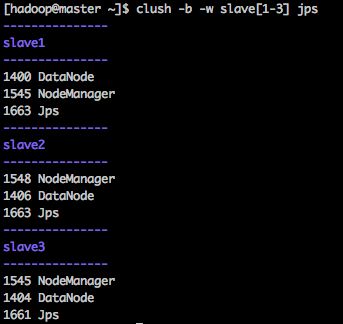
在hadoop-master和各台计算机上,分别执行执行:
jps
你会看到程序的运行结果。
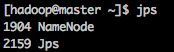
1、Hadoop-master
主要包括NameNode进程。
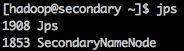
2、Hadoop-Secondary
主要包括Secondary NameNode进程。
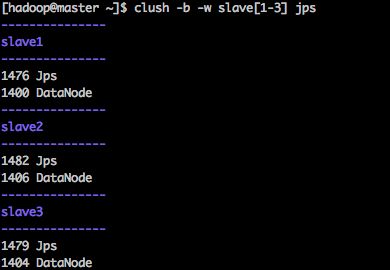
3、Hadoop-slave1、Hadoop-slave2和Hadoop-slave3
主要包括DataNode进程。
3.5 配置YARN和Map Reduce
3.5.1 配置mapreduce
编辑mapred-site.xml 文件:
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
3.5.2 配置YARN
编辑yarn-site.xml文件:
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
3.5.3 启动YARN
执行以下指令启动yarn:
start-yarn.sh
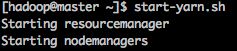
这将会启动ResourceManager和NodeManager。
其中,ResourceManager在NodeName上运行,NodeManager在Slave上运行。
4 安装ntp时间服务
hadoop服务,要求各个节点的时间严格同步,所以我们需要在master上创建一个ntp时间服务,其他节点跟它同步。
4.1 安装ntp服务
执行以下指令安装:
sudo yum install ntp
4.2 配置时间同步
我们使用,hadoop、hbase等服务时,要求各个节点的时间严格同步。这就需要用到时间同步服务器,不过我们常见的Internet时间同步服务器不太靠谱,所以我们需要搭建一个ntp时间服务——最好让其他节点与它同步。
4.2.1 最简单的方法
直接与Aliyun时钟服务器同步:
传送门: ntp时间同步配置
5 安装hive
5.1 安装hive
5.1.1 准备工作
在master上下载、解压缩
wget wget http://mirrors.hust.edu.cn/apache/hive/hive-3.1.0/apache-hive-3.1.0-bin.tar.gz
tar zxvf apache-hive-3.1.0-bin.tar.gz
5.1.2 转移到Hive目录
在每台电脑上,创建hive目录:
sudo mkdir -p /opt/hive
在master电脑上,转移文件到Hive目录
sudo mv apache-hive-3.1.0-bin/* /opt/hive/
5.1.4 设置hive目录访问权限
chown -R hadoop:hadoop /opt/hive
5.1.4 分发Hive目录到所有节点
for x in `cat /opt/hadoop/machines` ; \
do echo $x ; \
scp /opt/hive/ $x:/opt/hive/ ; \
done;
5.1.5 设置Hive环境变量
sudo vi /etc/profile
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
5.2 配置hive目录及访问权限
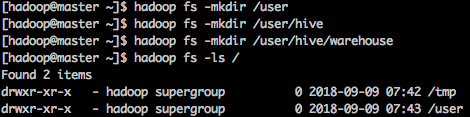
在hadoop-master上,执行以下指令:
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hive
hadoop fs -mkdir /user/hive/warehouse
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /user/hive/warehouse
5.3 配置hive
默认配置下的Hive,使用的是Derby元数据库,它只能从本地连接,并且只支持一个用户。所以我们就直接改为MySQL数据库作为元数据库。
5.3.1安装MySQL
sudo yum install mariadb-server mariadb
sudo systemctl start mariadb
sudo systemctl enable mariadb
5.3.2 配置MySQL允许远程访问
MySQL默认配置下,不允许远程访问。我们要修改为允许远程访问。在Master主机上,执行以下指令登录MySQL:
mysql -u root
然后新建root可以从远程访问的账号,并授权:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'password' WITH GRANT OPTION;
FLUSH PRIVILEGES;
5.3.1 设置环境变量
5.3.2 配置hive-env.sh
cd /opt/hive/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
主要配置一个参数:指定HADOOP_HOME目录。如果本机已经安装了Hadoop,并且设置了HADOOP_HOME环境变量,则不需要配置。
5.3.2 设置hive-site.xml
修改hive配置文件
cd hive-2.3.3/conf
cp hive-default.xml.template hive-site.xml
vi hive-site.xml
system:java.io.tmpdir
/opt/hive/iotmp
system:user.name
${user.name}
javax.jdo.option.ConnectionURL
jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
All4Icode
5.3.6 准备MySQL驱动
sudo yum install unzip
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.47.zip
unzip mysql-connector-java-5.1.47.zip
cp mysql-connector-java-5.1.47/mysql-connector-java-5.1.47.jar /opt/hive/lib
5.3.7 初始化MySQL元数据库
schematool -initSchema -dbType mysql
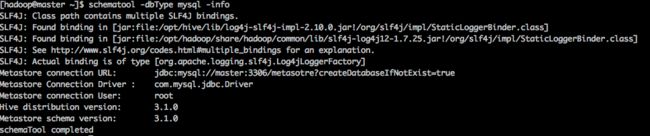
看下初始化的数据库信息:
schematool -dbType mysql -info
5.4 启动
[hadoop@master ~]$ hive
hive> show databases;
OK
default
Time taken: 1.139 seconds, Fetched: 1 row(s)
hive> create table test(id int, name string);
OK
Time taken: 0.742 seconds
hive> show tables;
OK
test
Time taken: 0.082 seconds, Fetched: 1 row(s)
hive>
5.5 简单使用
5.5.1 看下hive在hdfs中创建的目录
hadoop fs -ls -R /user/hive
5.5.2 看下hive在MySQL中创建的表
mysql> use metastore;
mysql> select * from TBLS;

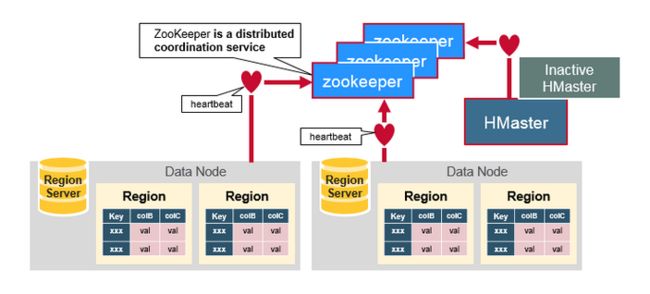
6 安装HBase
6.0 HBase架构图
6.1 准备工作
1、下载
wget http://mirrors.shu.edu.cn/apache/hbase/2.0.2/hbase-2.0.2-bin.tar.gz
2、解压缩
tar zxvf hbase-2.0.2-bin.tar.gz
3、设置目录
在Master电脑上:
sudo mkdir /opt/hbase
sudo chown -R hadoop:hadoop /opt/hbase
mv hbase-2.0.2/* /opt/hbase/
secondary、slave1、slave2、slave3电脑上:
sudo mkdir /opt/hbase
sudo chown -R hadoop:hadoop /opt/hbase
4、设置HBase环境变量
我们计划在master电脑启用HBase master、几台slave电脑上启用RegionServer。
在master电脑上,编辑/etc/profile文件,加入相关的环境变量:
sudo vi /etc/profile
在文件的最后加入以下信息:
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
分发到每台电脑上,执行以下指令使设置生效:
sudo scp /etc/profile root@slave1:/etc/profile
sudo scp /etc/profile root@slave2:/etc/profile
sudo scp /etc/profile root@slave3:/etc/profile
master、slave1、slave2、slave3电脑上分别执行以下指令:
source /etc/profile
6.2 配置
HBase的配置文件,都位于$HBASE_HOME下的conf目录中:
1、hbase-env.sh
主要用来设置JAVA_HOME环境变量,我们是集中在/etc/profile中进行设置——这里可以不用设置。
# 根据自己的实际JAVA_HOME目录配置
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
# 默认使用自带的Zookeeper,配置为false则使用我们部署的
export HBASE_MANAGES_ZK=false
2、 hbase-site.xml
hbase.tmp.dir
home/hadoop/data/hbase/tmp
# HBase的hdfs根目录
hbase.rootdir
hdfs://master:9000/hbase
#采用zookeeper分部署部署
hbase.cluster.distributed
true
# zookeeper节点
hbase.zookeeper.quorum
slave1,slave2,slave3
3、 regionservers
编辑regionservers:
vi $HBASE_HOME/conf/regionservers
保证内容如下:
slave1
slave2
slave3
6.3 分发文件
scp -r /opt/hbase/* slave1:/opt/hbase
scp -r /opt/hbase/* slave2:/opt/hbase
scp -r /opt/hbase/* slave3:/opt/hbase
6.3 启动HBase
执行start-hbase.sh。
start-hbase.sh
至此,包括hadoop、yarn、hive和HBase不适用HA的服务器集群搭建完毕。