声明:本文已授权公众号「AI极客研修站」独家发布
原文链接
我的GitHub博客地址
上一篇文章,我用了4000字这样比较长的篇幅,介绍了一些金融和量化交易相关的基本知识,还大概说了下人工智能在金融方面使用的优劣。这篇文章我们将用一个具体代码来进行一波股票价格预测的实战。
之前也说了,量化交易本身只是一种交易模式,只要在量化交易软件中输入了策略,计算机就会根据策略进行自动化交易。我们机器学习生成的不过是量化交易步骤中的策略阶段,暂时我们不用考虑交易方面的接入,这个涉及到很多交易 API 相关的知识。交易平台开发框架,我介绍一个Github上基于Python的开源框架,大家可以了解一下:vnpy。
OK,下面我就把关注点集中在价格预测这件事上。我们都知道,不论用机器学习做什么,首先我们得需要一些数据源,并且还需要有一些途径来进行回测。那么像股票或者其他金融盘口的数据是有很多途径可以获取的,我今天给大家介绍一个我平时经常用的平台:RiceQuant米筐量化交易平台(非广告)。
这个平台有自己的一套Python API和编译器iPython NoteBook来进行量化交易策略的开发。代码只需要在特定的方法内实现好逻辑,就可以一键生成测试结果,结果会自动的解析出回测收益曲线以及一些指标来给你参考。就像这样
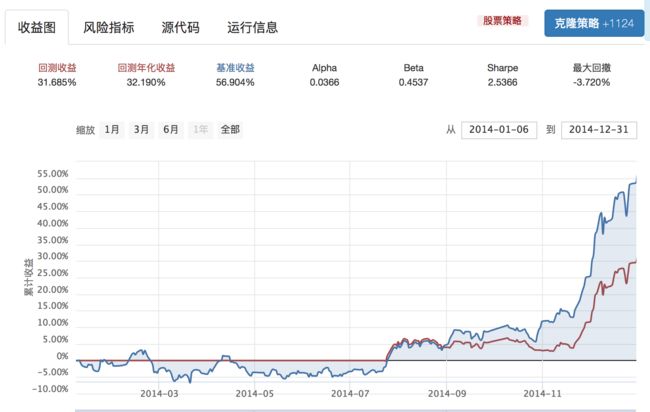
具体的API我就不多介绍了,有兴趣的同学可以直接去官网查看API文档,非常详细。https://www.ricequant.com/api/python/chn
在这里,我将通过数据进行一些简单的机器学习操作,并没有用到能够得到回测的那些API。需要提前了解的一个API就是get_price函数,比如下面这句话就代表了获取CSI300指数过去一年的原始历史数据,返回类型是我们非常熟悉的pandas中的DataFrame。
df = get_price('CSI300.INDX','2005-01-05','2015-01-01').reset_index()[['open','close']]
这个函数只能在米筐线上编译器中使用。我们拿到这个数据,就可以通过Python数据分析三剑客来进行花式操作了。我们这里用一些比较简单的特征来进行我们的预测。那就是前两天的涨跌幅,把前两天的涨跌幅作为特征输入,再把该天的实际涨跌幅作为输出,这样的一组数据作为训练样本。
当然了,这种特征的选择是非常简单的,预测结果肯定不够理想,实际工程中,特征的定性和定量是最重要也是最复杂的,比如行情都会有很多指标,像MACD、VR,都是很重要的指标,我们这里这样选择特征只是为了方便演示。
既然我们是通过涨跌幅来作为特征,首先得把涨跌幅这个数据给弄出来,刚刚通过 get_price 获得的是每一天的开盘和收盘价格,那么计算涨跌幅就简单了
>>> up_and_down=df['close']-df['open'] > 0 # 获取涨跌情况
>>> rate_of_return = (df['close']-df['open'])/df['open'] # 获取涨跌幅
>>> up_and_down_statistic = up_and_down.value_counts() # 获取涨跌天数
然后,我们使用matplotlib.pyplot来绘制下涨跌天数的柱状图
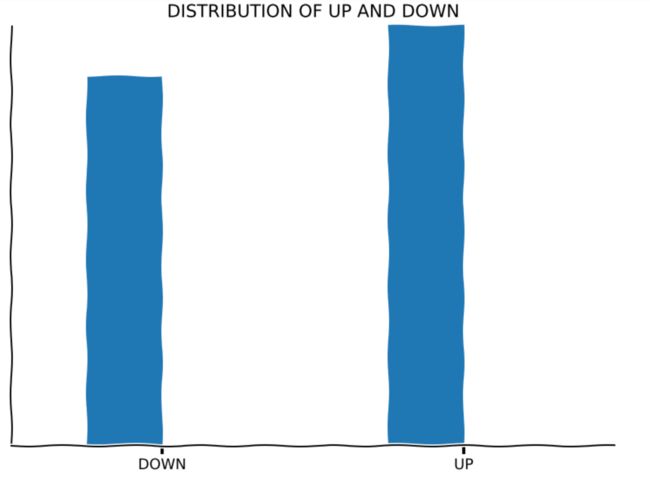
很奇怪,在ipython notebook使用pyplot有时候会画出来弯曲的,将就看咯
从图上我们可以清晰的看出来,这10年中,最后收盘价是涨的情况还是偏多一点的。我们还可以看一些别的数据,比如我们就打印一下每天涨跌图。
rate_of_return.plot(kind='line', style='k--', figsize=(15, 10), title='Daily Yield Changes Over Time Series')
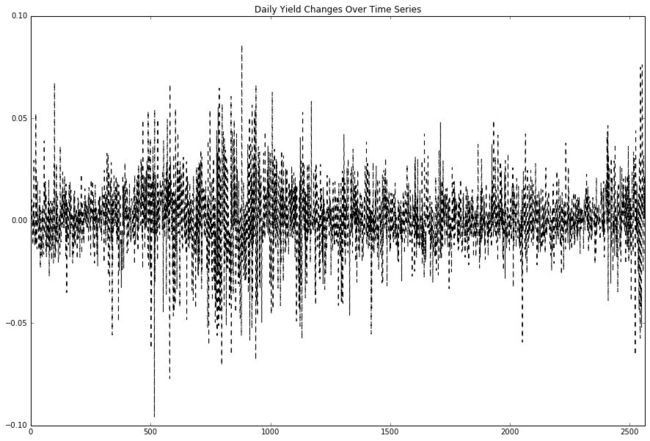
从这个图我们就可以比较清晰的看出来这2000多的交易日里面的一些行情情况了,比如中间有段宽幅波动奇大的区间,这说明这会是个牛市,对应到07年那会的牛市。我还记得那会我刚上初中,每天中午回家,我爸爸就告诉我他今天股票又赚了多少多少钱,可开心。
当然了,你还可以利用画图进行更多的数据分析,下面我们将编写一个简单的机器学习代码,看看使用这样一个简单的特征,这段数据跑下来,能有多少的价格预测正确率。
我们在这里预测的是收盘涨跌情况,是个分类问题,所以我们这里选择SVM来进行分类。每个新数据都会被再次进行fit拟合以便提高下次预测的准确率。代码如下:
import pandas as pd
import numpy as np
from __future__ import division
from sklearn import svm
from collections import deque
import matplotlib.pyplot as plt
window = 2
# 米筐获取某一品种历史数据的DataFrame,注意得从2005-01-04开始
df = get_price('CSI300.INDX', '2005-01-05', '2015-07-25').reset_index()[['open', 'close']]
up_and_down = df['close'] - df['open'] > 0
print(len(up_and_down))
X = deque()
y = deque()
clf = svm.LinearSVC() # SVM
prediction = 0
test_num = 0 # 测试总数
win_num = 0 # 正确预测数
current_index = 400 # 起始位置
for current_index in range(current_index, len(up_and_down)-1, 1):
fact = up_and_down[current_index+1]
X.append(list(up_and_down[(current_index-window): current_index]))
y.append(up_and_down[current_index])
if len(y) > 100 and len(y) % 50 == 0:
test_num += 1
clf.fit(X, y)
prediction = clf.predict(list(up_and_down[(current_index-window+1): current_index+1]))
if prediction[0] == fact:
win_num += 1
print(win_num)
print("预测准确率为",win_num/test_num)
最后输出的结果为58.53%,如果一个价格预测软件仅通过历史数据就能达到百分之60左右的正确率,实际上这已经是一个非常不错的结果了,不过我们这里的结果说服力不够强,首先我们的特征过于简单,再有就是为了节省训练时间,实际上我把样本的拟合规模缩短了很多,我只在50的倍数位置进行预测,所以我最终的预测样本数量大概只有40来个。
上面的代码部分参考了米筐社区中一位叫陆东旭的同学。这个社区现在还是挺活跃的,我看的帖子还是三年前的。可以说,早在几年前,国内就有这样量化交易和AI的社区了,可见前人们早已在路上,等到我们都认为需要去接触这些东西的时候,他们已经跑的更加远了。
不过没关系,后来者居上,也是一件挺有意思的事。
上面的代码实际上是最粗暴和原始的代码,通过自己写循环未免也太麻烦了,所以这个平台后来更新了 API,就像我文章开头说的那样,只需要在提供好的空方法里填充逻辑,就可以快速的进行回测操作了。比如下面就是官方的API文档介绍。
# 在这个方法中编写任何的初始化逻辑。context对象将会在你的算法策略的任何方法之间做传递。
def init(context):
context.s1 = "000001.XSHE"
# 是否已发送了order
context.fired = False
# 你选择的证券的数据更新将会触发此段逻辑,例如日或分钟历史数据切片或者是实时数据切片更新
def handle_bar(context, bar_dict):
# 开始编写你的主要的算法逻辑
# bar_dict[order_book_id] 可以拿到某个证券的bar信息
# context.portfolio 可以拿到现在的投资组合状态信息
# 使用order_shares(id_or_ins, amount)方法进行落单
# TODO: 开始编写你的算法吧!
if not context.fired:
# order_percent并且传入1代表买入该股票并且使其占有投资组合的100%
order_percent(context.s1, 1)
context.fired = True
好了,今天就是简单的通过米筐来介绍下如何通过一些第三方数据获取API,并结合 Python 的数据分析库来做一些有趣的事情。下篇文章再见咯!
推荐阅读
分享一些学习AI的小干货
量化交易与人工智能到底是咋回事