1. 安装ElatsticSearch环境:
首先,安装JRE,然后安装和启动ElasticSearch(使用Homebrew安装):
$ brew install elasticsearch
$ elasticsearch #启动es
$ brew list elasticsearch #查看es安装路径
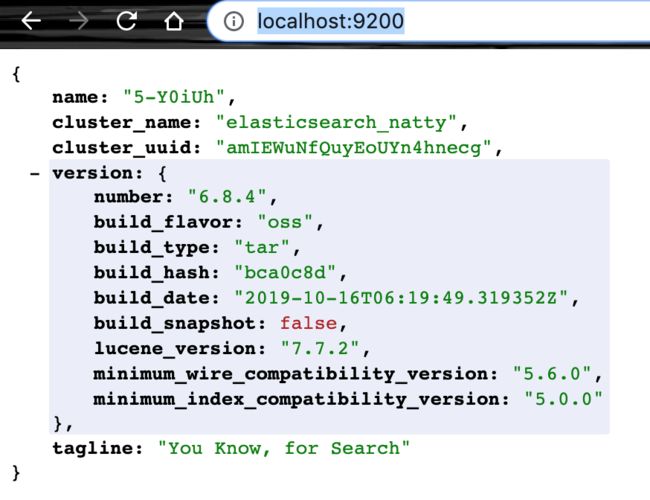
ES的默认的9300端口用于节点间通信,适用于Java API,而端口9200默认用户HTTP通信。浏览器访问localhost的9300端口(es默认监听从9200端口进入的HTTP请求),http://localhost:9200/ 有如下回应
Elasticsearch kopf 是一个ES监控和发送请求的 图形化工具,Github地址: https://github.com/lmenezes/elasticsearch-kopf
重要:官网使用手册https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
2. ES的基本操作和环境配置:
ES最重要的两个操作分别是索引数据和搜索数据,其中搜索数据更加重要。
2.1 索引数据
我随便新建一个索引
3.索引、更新和删除数据
3.1 使用映射来定义文档
从数据的逻辑划分来看 ,可以认为索引是数据库,而类型是数据库中的表,文档是数据行。但是从物理上,同一个 Elasticsearch 索引中的所有文挡,无论何种类型,都是存储在属于相同分片的同一组文件中。当多个类型中出现同样的字段名称时,两个同名的字段应该有同样的设置。类型包含了映射中每个字段的定义,映射包括了该类型的文档中可能出现的所有字段。
下面代码创建一个索引(索引名crud_index_test,类型名:poi,文档名:B0FFG77NR6):
curl -H 'Content-Type: application/json' -XPUT 'localhost:9200/crud_index_test/poi/B0FFG77NR6' -d'{
"name": "南京格瑞特金属幕墙板制造有限公司(东北门)",
"pc_type": 2,
"create_time": "2019-11-08",
"enable": true,
"name_quanpin": [
"nan'jing'jia'chang'mei'dian'zi'shang'wu",
"nanjingjiachangmeidianzishangwuyouxiangongsi"
]
}'
因为ES会在创建文档时,自动为我们生成映射文件。下面代码可以查看某个索引的映射,使用_mapping,其中参数?pretty可以结构化输出(JSON格式)我们的返回结果:
curl -XGET 'localhost:9200/crud_index_test/_mapping/poi?pretty'
{
"crud_index_test" : {
"mappings" : {
"poi" : {
"properties" : {
"create_time" : {
"type" : "date"
},
"enable" : {
"type" : "boolean"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name_quanpin" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"pc_type" : {
"type" : "long"
}
}
}
}
}
}
如果在现有的基础上再设置一个映射,Elasticsearch会将两者进行合并。例如,下边请求直接修改poi类型的映射,该操作会在原有映射基础上增加一个string类型的poi_address字段。
curl -H 'Content-Type: application/json' -XPUT 'localhost:9200/crud_index_test/_mapping/poi' -d'
{
"poi": {
"properties": {
"poi_address": {
"type": "text"
}
}
}
}'
日期的format,可以在官网参考:www.elastic.co/guide/reference/mapping/date-format/
修改映射时,需要注意如果修改原有的类型,那么会失败,除非把所有索引的数据删除后,重新索引。
3.2 数据类型、数组、多字段
Elasticsearch中一个字段可以是核心类型,也可以是一个从核心类型派生的复杂类型(如数组)。核心类型包括: 字符串、数值、日期、布尔几种类型。
1.在字段mapping中,有一个字段级的index,其取值有几种选择:
true/false:是否被索引。
2.对于日期类型,我们可以指定其格式,例如yyyy-MM-dd等。
curl -H 'Content-Type: application/json' -XPUT 'localhost:9200/crud_index_test/_mapping/poi' -d'
{
"poi": {
"properties": {
"parent_id": {
"type": "text",
"index":true
},
"end_date": {
"type": "date",
"format":"yyyy-MM-dd"
}
}
}
}'
3.在mapping中,如何定义一个数组呢,其实跟core type无异,数组是字符串类型,直接设置为text类型即可。
3.3 预定义字段
官网参考
常见常用的一些预定义字段包括: _source在索引文档的时候,存储原始的JSON文档。_id、 _type 和_index唯一识别文档。使用_size来索引原始JSON内容的大小。_routing控制文档路由到哪些分片。
预定义的字段总是以下划线开头。我们无需构建,这些字段es为文档添加的元数据。
1._source 字段按照原有格式来存储原有的文档。
在我们查询某个文档(需要索引/类型/文档id三级)时,返回结果就会有_source字段,_source字段按照原有格式来存储原有的文档。 同时,也可以通过stored_fields查具体字段,例如:
curl -XGET 'localhost:9200/crud_index_test/poi/B0FFG77NR6?pretty'
curl -XGET 'localhost:9200/crud_index_test/poi/B0FFG77NR6?pretty&stored_fields=name,pc_type'
- _id,_type,_index
分别指的文档id,类型和索引。
curl -XGET 'localhost:9200/_search?q=_index:crud_index_test&pretty'
3.4 更新文档
文档的更新包括检索文档、处理文档、并重新索引文档,直至先前的文档被覆盖。
修改部分字段,使用_update发送POST请求,来修改原来的文档,也可以通过upsert选项,类似sql中upsert语句。
curl -H 'Content-Type: application/json' -XPOST 'localhost:9200/crud_index_test/poi/B0FFG77NR6/_update?pretty' -d '{"doc" : { "pc_type":1}}'
curl -H 'Content-Type: application/json' -XPOST 'localhost:9200/crud_index_test/poi/B001907CB1/_update?pretty' -d '{
"doc":{
"pc_type":1
},
"upsert":{
"name":"新宁五金建材",
"address":"江宁区 将军大道99-36号",
"pc_type":2
}
}'
在更新过程中,需要注意冲突,可以使用版本来实现并发控制。
删除单个文档或者一组丈档。删除整个索引。关闭索引。其中,关闭的索引不允许读取或者写入操作,数据也不会加载到内存。但是索引还是保留在磁盘上。
为了完成删除,需要向其URL发送HTTP DELETE请求。同时,也可以删除查询匹配的那些文档。
curl -XDELETE 'localhost:9200/crud_index_test/poi/B001907CB1/?pretty'
curl -XPOST 'localhost:9200/crud_index_test/_close?pretty'
curl -XPOST 'localhost:9200/crud_index_test/_open?pretty'
4.搜索数据
(20191111)
4.1 搜索请求的结构
Elasticsearch的搜索是基于JSON文档或者是基于URL的请求,REST搜索请求使用_search的REST端点,通过_search来指定搜索的范围,例如,下面两个分别针对整个集群和crud_index_test索引来搜索:
curl -XGET 'localhost:9200/_search' -d ''
curl -XGET 'localhost:9200/crud_index_test/_search' -d ''
限制好请求范围后,就需要配置搜索请求中最为重要的模块,基本包括:query、size、from、size、sort等,详细可参考官网文档。在搜索时,可以使用基于URL和请求主体(JSON)的请求。其中,请求主体的方式更加灵活和强大。
下面语句使用了几个参数,分别介绍下它们的含义,from,size:返回索引结果集合中从第from个开始的size个索引。sort是按照某个字段来对结果索引集合来排序,_source是限制返回的结果的字段。
curl -XGET 'localhost:9200/crud_index_test/_search?pretty&from=1&size=5&sort=create_time:desc&_source=name,create_time,enable'
当执行更多高级搜索的时候,采用基于请求主体的搜索会使得你拥有更多的灵活性和选择性。用请求主体方式,重新生成上边的URL请求:
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"match_all":{
}
},
"from":0,
"size":5,
"sort":[
{
"create_time":"desc"
}
],
"_source":[
"name",
"create_time",
"enable"
]
}
'
简单介绍下,搜索返回结果一些关键key的意思。took:查询所用毫秒数。timed_out:表名是否有分片超时(也就是是否只返回了部分结果)。_shards:此次查询的分片使用情况,一共访问多少分片其中成功、忽略、失败的数量。hits:命中关键词元素中的命中文档数组。_source:原始的JSON文档。
4.2 查询和过滤器DSL
- match和term混合查询:
搜索的过滤器只是为“文档是否匹配这个查询”,返回简单的“是”或“否”的答案。过滤器可以比普通的查询更快而且还可以被缓存(不计算得分)。下面是一个过滤查询,包括查询和过滤器模块。filter部分用来筛选文档,不影响match部分文档得分。
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"牧奇"
}
}
],
"filter":[
{
"term":{
"create_time":"2019-11-10"
}
}
]
}
}
}'
- query_string查询:
query_string使用具有严格语法的解析器,根据提供的查询字符串(AND 和 OR等来组合查询)返回文档。默认情况下,query string查询将会搜索_all字段。但是可以使用default_field来指定默认的查询字段(如果在URL中没指定的话)。query_string查询的一个显著缺点是它实在是太强大了,可以写出很复杂的逻辑,但是如果用户输入了格式错误的查询,他们将得到返回的异常。
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"query_string":{
"query" : "(牧奇) OR (格瑞特)",
"default_field" : "name"
}
}
}'
- term查询和terms查询:
term既可以作为查询,也可以作为过滤器。对于term查询来讲,被搜索的关键词是没有经过分析的,文档中的同条必须要精确匹配才能作为结果返回,这一点是与match的主要区别。
和term查询相似,还可以使用term过滤器来限制结果文挡,使其包含特定的词条,不过无须计算得分(参考第1部分)。
和term查询类似,terms查询(注意这里多一个s)可以搜索某个文档字段中的多个词条。
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"term":{
"name_quanpin" : "mengbaotongzhuang"
}
}
}'
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"terms":{
"name_quanpin" : ["mengbaotongzhuang","nanjingnkpifuguanlimeijiameijiegongzuoshi"]
}
}
}'
4.3 match查询
match查询可以有多种行为方式。最常见的是布尔(boolean)和词组(phrase)。默认情况下,match查询使用布尔行为和OR操作符。例如,"萌宝 格瑞特"会搜索命中了萌宝或者格瑞特的文档。使用"operator":"and"修改为了并且的关系。
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"match":{
"name" : "萌宝 格瑞特"
}
}
}'
curl -H 'Content-Type: application/json' -XGET 'localhost:9200/crud_index_test/_search?pretty' -d '
{
"query":{
"match":{
"name":{
"query":"萌宝 格瑞特",
"operator":"and"
}
}
}
}'
第二个重要行为是作为 phrase 查询,每个单词的位置之间可以留有余地。这种余地称作slop,用于表示词组中多个分词之间的距离。使用match_phrase来查询。
phrase_prefix查询是和词组中最后一个词条进行前缀匹配。
multi_match查询和match查询很像,但是,多字段匹配允许你搜索多个字段中的值。对多个字段应用同一个搜索词。
4.4 组合查询或复合查询
bool查询允许你在单独的查询中组合任意数量的查询,指定的查询子句表明哪些部分是必须(must)匹配、应该(should)匹配或者是不能(must not)匹配上 Elasticsearch索引里的数据。
1.must匹配,只有匹配上这些查询的结果才会被返回。
2.should匹配,只有匹配上指定数量子句的文档才会被返回 。
3.如果没有指定must匹配的子句,文档至少要匹配一个should子句才能返回。
4.must not子句会使得匹配其的文档被移出结果集合。
5. 分析数据
5.1 Elasticsearch分析
分析(analysis)是在文档被发送并加入倒排索引之前,Elasticsearch在其主体上进行的操作。