本文来自同步博客。
P.S. 不知道怎么显示数学公式以及更好的排版内容。所以如果觉得文章下面格式乱的话请自行跳转到上述链接。后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱。看原博客地址会有更好的体验。
前面两篇文章介绍了支持向量机SVM的基本原理,并利用Python实践了分割超平面的求解过程。
本篇文章将介绍SVM如何对非线性可分的数据进行分类。
基本原理
SVM处理线性不可分数据的关键在于把低维空间中线性不可分的数据映射到高维空间使其线性可分。然后再按线性可分数据进行处理。
就像下方展示的内容。有圆圈和星星两种不同的数据,在左边的一维空间中它们是无法线性分割的;而在右边二维空间中却可以用一条横线进行分割。

基于这个原理,很直观地,找到一个映射函数把样本向量x映射到高维空间的一个向量z。例如:对-\vec{x}=(x\_1, x\_2)-,可以有选择类似-\vec{z}=(1,x\_1,x\_2,x\_1^2, x\_2^2, 2x\_1x\_2)-的映射。利用这个映射,可以计算出每个数据点在高维空间中对应的向量。最后用这些向量求解-\vec{\alpha}、\vec{w}、b-。
这里需要思考一个问题:这样把每个数据都映射成另一个向量,然后在进行计算,比线性可分模型的SVM复杂了好多好多。还有要找到这样的映射也不是一件容易的事。有没有比较好的做法?答案肯定是有的,可以利用“核技巧”。
核技巧
实际上我们不需要计算每个数据在高维空间的向量。因为无论是求解-\vec{\alpha}-,还是求解分割超平面的-\vec{w}-和-b-,我们需要仅仅只有一个高维空间下对应两个向量的向量积。例如有数据点-\vec{x\_1},\vec{x\_2}-,对应的映射后的结果为-\vec{z\_1},\vec{z\_2}-,那么我们要的仅仅是-\vec{z\_1}^{T} \vec{z\_2}-这个向量积。这种处理方式且称为核技巧,用函数-K(x\_1,x\_2)-表示向量积-\vec{z\_1}^{T} \vec{z\_2}-。
首先,构造二次规划函数只需要-K(x\_1,x\_2)-:
L(\vec{\alpha}) = \sum\_{i}^{n}{\alpha\_i} - \frac{1}{2}\sum\_{i}^{n}{\sum\_{j}^{n}{\alpha\_i \alpha\_j y\_i y\_j \vec{z\_i}^{T} \vec{z\_j}}}, \sum\_{i}^{n}{\alpha\_i y\_i} = 0, \alpha\_i,\alpha\_j \ge 0, i,j = 1,2...n
得到-\vec{\alpha}-向量后,可以得到-\vec{w}-:
w = \sum\_{i}^{n}{\alpha\_i y\_i \vec{z\_i}}
取其中一个支持向量(假设下标为v),可计算b,也只需要-K(x\_1,x\_2)-:
b = \frac{1}{y\_v} - \vec{w}^{T}\vec{z\_v} = \frac{1}{y\_v} - \sum\_{i}^{n}{\alpha\_i y\_i \vec{z\_i}^{T}}\vec{z\_v} = \frac{1}{y\_v} - \sum\_{i}^{n}{\alpha\_i y\_i K(\vec{z\_i},\vec{z\_v})}
最后,对新数据的决策规则函数Rule如下,也只需要-K(x\_1,x\_2)-:
Rule: sign(\sum\_{i}^{n}{\alpha\_i y\_i K(\vec{x\_i},\vec{u})} + b)
常用核函数
1. 线性核函数
K(\vec{x\_1},\vec{x\_2}) = \vec{x\_1}^{T}\vec{x\_2}
这是-\vec{x\_1}^{T}\vec{x\_2}-本身,也算一个线性核函数,同时它也是下面介绍的多项式核函数的特例。
2. 多项式核函数
K(\vec{x\_1},\vec{x\_2}) = (\vec{x\_1}^{T}\vec{x\_2} + c)^{d}
这种核函数利用多项式展开可以了解它将把原向量映射到某个维度可数的空间内,维度数目与原向量的维度以及参数c、d有关。
3. 高斯核函数
K(\vec{x\_1},\vec{x\_2}) = exp(-\gamma ||\vec{x\_1} - \vec{x\_2}||^{d}) = e^{-\gamma ||\vec{x\_1} - \vec{x\_2}||^{d}}
高斯核函数可以利用泰勒展开,它可以把原向量映射到近乎无穷维空间。
判定核函数是否有效(高维空间是否存在)
一般情况下我们不需要自己发明核函数,常用的核函数已经够用,所以“关于多维Z空间是否存在或者核函数是否有效”的证明可以忽略不管。
这里依旧罗列判断核函数是否有效的两个条件:
- 核函数对输入是对称的,-K(\vec{x\_1}, \vec{x\_2}) = K(\vec{x\_2}, \vec{x\_1})-。
-\begin{bmatrix} K(\vec{x\_1},\vec{x\_1}) & K(\vec{x\_1},\vec{x\_2}) & \cdots & K(\vec{x\_1},\vec{x\_n}) \\\\ \vdots & \vdots & \ddots & \vdots \\\\ K(\vec{x\_n},\vec{x\_1}) & K(\vec{x\_n},\vec{x\_2}) & \cdots & K(\vec{x\_n},\vec{x\_n}) \\\\ \end{bmatrix} -矩阵是一个正半定矩阵。
使用Python展示SVM对线性不可分数据的处理过程
与前一篇文章中的例子比较,这里的代码主要增加了一个kernel函数表示-K(\vec{x\_1},\vec{x\_2})-:
# 核函数: 多项式核函数c=0,d=2
# 选择依据与测试数据有关,这样的映射应该可以把数据分隔开
# 则kernel应该返回的内积如下:
def kernel(x1, x2):
return np.dot(x1, x2)**2
其次,在生成H矩阵的时候不是直接使用-\vec{x\_1}^{T}\vec{x\_2}-,而是使用kernel函数,如下:
# 计算H矩阵,根据样本数目应是一个len(X)xlen(X)的矩阵
H = np.array(
[y[i] * y[j] * kernel(X[i], X[j]) for i in range(len(X)) for j in range(len(X))]
).reshape(len(X), len(X))
其他的流程几乎一样,除了绘图代码。
执行结果如下:
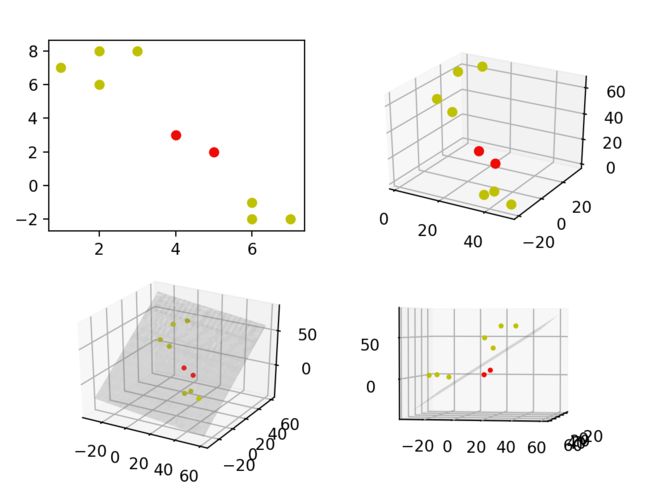
本文源码