原文链接:http://blackblog.tech/2018/02/23/Eight-Neural-Network/
只作个人学习总结与收藏,侵删
本文介绍四种常见的神经网络,分别是CNN,RNN,DBN,GAN。
神经网络的分类:
前馈神经网络:
这是实际应用中最常见的神经网络类型。第一层是输入,最后一层是输出。如果有多个隐藏层,我们称之为“深度”神经网络。他们计算出一系列改变样本相似性的变换。各层神经元的活动是前一层活动的非线性函数。
循环网络:
循环网络在他们的连接图中定向了循环,这意味着你可以按照箭头回到你开始的地方。他们可以有复杂的动态,使其很难训练。他们更具有生物真实性。
循环网络的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
对称连接网络:
对称连接网络有点像循环网络,但是单元之间的连接是对称的(它们在两个方向上权重相同)。比起循环网络,对称连接网络更容易分析。这个网络中有更多的限制,因为它们遵守能量函数定律。没有隐藏单元的对称连接网络被称为“Hopfield 网络”。有隐藏单元的对称连接的网络被称为玻尔兹曼机。
感知机
这是一个M-P神经元

一个神经元有n个输入,每一个输入对应一个权值w,神经元内会对输入与权重做乘法后求和,求和的结果与偏置做差,最终将结果放入激活函数中,由激活函数给出最后的输出,输出往往是二进制的,0 状态代表抑制,1 状态代表激活。threshold(阈值),f是激活函数。

感知机的输出
感知机可以分为单层感知机,多层感知机。
我们这里主要讨论的是单层感知机。
而感知机由两层神经网络组成,输入层接收外界输入信号后传递给输出层,输出层是 M-P神经元,
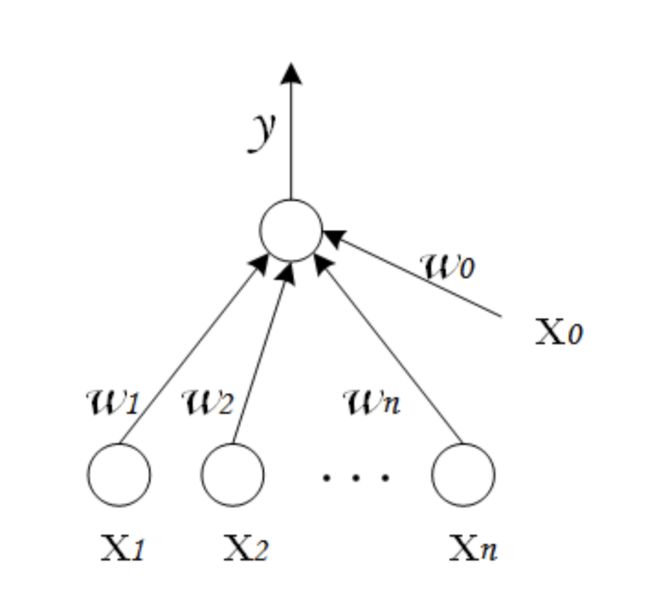
可以把感知机看作是 n 维实例空间中的超平面决策面,对于超平面一侧的样本,感知器输出 1,对于另一侧的实例输出 0,这个决策超平面方程是 w⋅x=0。 那些可以被某一个超平面分割的正反样例集合称为线性可分(linearly separable)样例集合,它们就可以使用图中的感知机表示。
与、或、非问题都是线性可分的问题,使用一个有两输入的感知机能容易地表示,而异或并不是一个线性可分的问题,所以使用单层感知机是不行的,这时候就要使用多层感知机来解决疑惑问题了。
如果我们要训练一个感知机,应该怎么办呢?
我们会从随机的权值开始,反复地应用这个感知机到每个训练样例,只要它误分类样例就修改感知机的权值。重复这个过程,直到感知机正确分类所有的样例。每一步根据感知机训练法则来修改权值,也就是修改与输入 xi 对应的权 wi,法则如下:
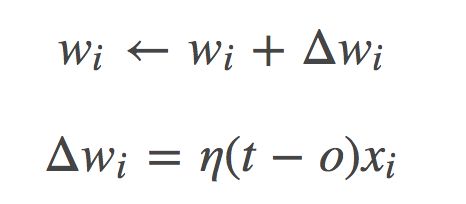
这里 t 是当前训练样例的目标输出,o 是感知机的输出,η 是一个正的常数称为学习速率(learning rate)。学习速率的作用是缓和每一步调整权的程度,它通常被设为一个小的数值(例如 0.1),而且有时会使其随着权调整次数的增加而衰减。
多层感知机,或者说是多层神经网络无非就是在输入层与输出层之间加了多个隐藏层而已,后续的CNN,DBN等神经网络只不过是将重新设计了每一层的类型。感知机可以说是神经网络的基础,后续更为复杂的神经网络都离不开最简单的感知机的模型,
卷积神经网络 CNN
卷积神经网络的结构基于一个假设,即输入数据是图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
常规神经网络在面对大尺寸图像时参数过多,效率低下且会导致网络过拟合。
引自https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit
神经元的三维排列。卷积神经网络针对输入全部是图像的情况,将结构调整得更加合理,获得了不小的优势。与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度(这里的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数)。举个例子,CIFAR-10中的图像是作为卷积神经网络的输入,该数据体的维度是32x32x3(宽度,高度和深度)。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。对于用来分类CIFAR-10中的图像的卷积网络,其最后的输出层的维度是1x1x10,因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。下面是例子:
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。卷积神经网络主要由三种类型的层构成:卷积层,汇聚(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。
网络结构例子:这仅仅是个概述,下面会更详解的介绍细节。一个用于CIFAR-10图像数据分类的卷积神经网络的结构可以是[输入层-卷积层-ReLU层-汇聚层-全连接层]。细节如下:
1.输入[32x32x3]存有图像的原始像素值,本例中图像宽高均为32,有3个颜色通道。
2.卷积层中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用12个滤波器(也叫作核),得到的输出数据体的维度就是[32x32x12]。
3.ReLU层将会逐个元素地进行激活函数操作,比如使用以0为阈值的
作为激活函数。该层对数据尺寸没有改变,还是[32x32x12]。
4.汇聚层在在空间维度(宽度和高度)上进行降采样(downsampling)操作,数据尺寸变为[16x16x12]。
5.全连接层将会计算分类评分,数据尺寸变为[1x1x10],其中10个数字对应的就是CIFAR-10中10个类别的分类评分值。正如其名,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
由此看来,卷积神经网络一层一层地将图像从原始像素值变换成最终的分类评分值。其中有的层含有参数,有的没有。具体说来,卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数(神经元的突触权值和偏差)。而ReLU层和汇聚层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
cs231n关于CNN的介绍(翻译):https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
卷积神经网络由三部分构成。第一部分是输入层。第二部分由n个卷积层和池化层的组合组成。第三部分由一个全连结的多层感知机分类器构成。
这里举AlexNet为例:

·输入:224×224大小的图片,3通道
·第一层卷积:11×11大小的卷积核96个,每个GPU上48个。
·第一层max-pooling:2×2的核。
·第二层卷积:5×5卷积核256个,每个GPU上128个。
·第二层max-pooling:2×2的核。
·第三层卷积:与上一层是全连接,3*3的卷积核384个。分到两个GPU上个192个。
·第四层卷积:3×3的卷积核384个,两个GPU各192个。该层与上一层连接没有经过pooling层。
·第五层卷积:3×3的卷积核256个,两个GPU上个128个。
·第五层max-pooling:2×2的核。
·第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。
·第二层全连接:4096维
·Softmax层:输出为1000,输出的每一维都是图片属于该类别的概率。
卷积神经网络在模式识别领域有着重要应用,当然这里只是对卷积神经网络做了最简单的讲解,卷积神经网络中仍然有很多知识,比如局部感受野,权值共享,多卷积核等内容,后续有机会再进行讲解。
循环神经网络(递归神经网络) RNN
传统的神经网络对于很多问题难以处理,比如你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN能够对任何长度的序列数据进行处理。
这是一个简单的RNN的结构,可以看到隐藏层自己是可以跟自己进行连接的。
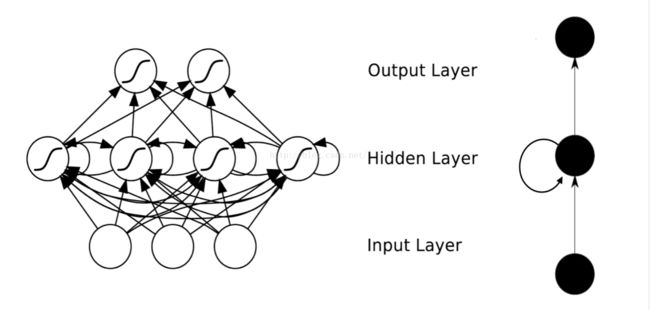
那么RNN为什么隐藏层能够看到上一刻的隐藏层的输出呢,其实我们把这个网络展开来开就很清晰了。
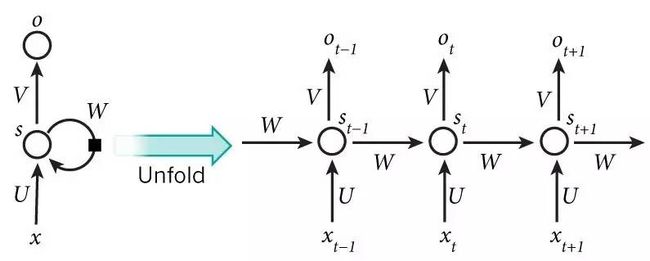
这个网络在t时刻接收到输入Xt之后,隐藏层的值是St,输出值是Ot,关键一点是,的值不仅仅取决于Xt,还取决于St-1。
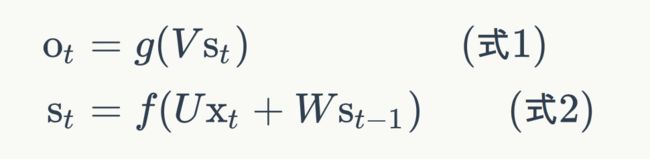
式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值St-1作为这一次的输入的权重矩阵,f是激活函数。
从上面的公式我们可以看出,循环层和全连接层的区别就是循环层多了一个权重矩阵 W。
如果反复把式2带入到式1,我们将得到:
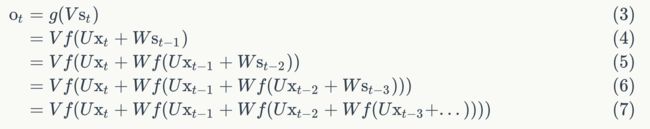
从上面可以看出,循环神经网络的输出值,是受前面历次输入值Xt、Xt-1、Xt-2、X-3、X-4...影响的,这就是为什么循环神经网络可以往前看任意多个输入值的原因。
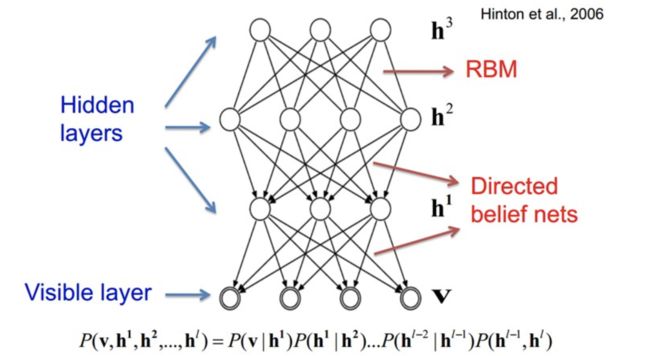
深度信念网络 DBN
在讲DBN之前,我们需要对DBN的基本组成单位有一定的了解,那就是RBM,受限玻尔兹曼机。
首先什么是玻尔兹曼机?
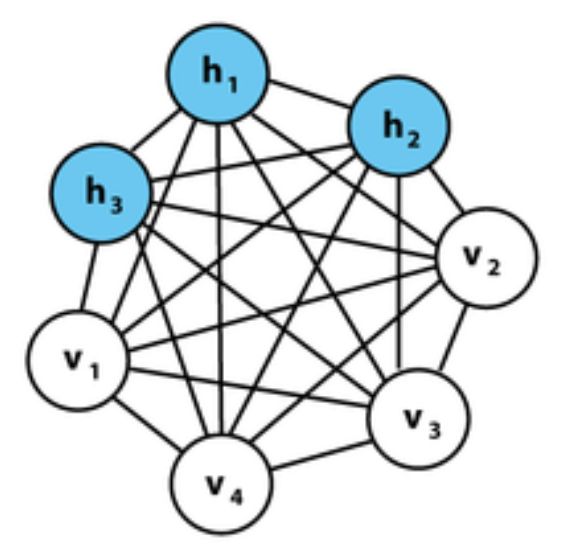
如图所示为一个玻尔兹曼机,其蓝色节点为隐层,白色节点为输入层。
玻尔兹曼机和递归神经网络相比,区别体现在以下几点:
1、递归神经网络本质是学习一个函数,因此有输入和输出层的概念,而玻尔兹曼机的用处在于学习一组数据的“内在表示”,因此其没有输出层的概念。
2、递归神经网络各节点链接为有向环,而玻尔兹曼机各节点连接成无向完全图。
而受限玻尔兹曼机是什么呢?
最简单的来说就是加入了限制,这个限制就是将完全图变成了二分图。即由一个显层和一个隐层构成,显层与隐层的神经元之间为双向全连接。

h表示隐藏层,v表示显层
在RBM中,任意两个相连的神经元之间有一个权值w表示其连接强度,每个神经元自身有一个偏置系数b(对显层神经元)和c(对隐层神经元)来表示其自身权重。
具体的公式推导在这里就不展示了
DBN是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅而已评估了后者,也就是P(Label|Observation)。
DBN由多个限制玻尔兹曼机(Restricted Boltzmann Machines)层组成,一个典型的神经网络类型如图所示。这些网络被“限制”为一个可视层和一个隐层,层间存在连接,但层内的单元间不存在连接。隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。
生成对抗网络 GAN
生成对抗网络其实在之前的帖子中做过讲解,这里在说明一下。
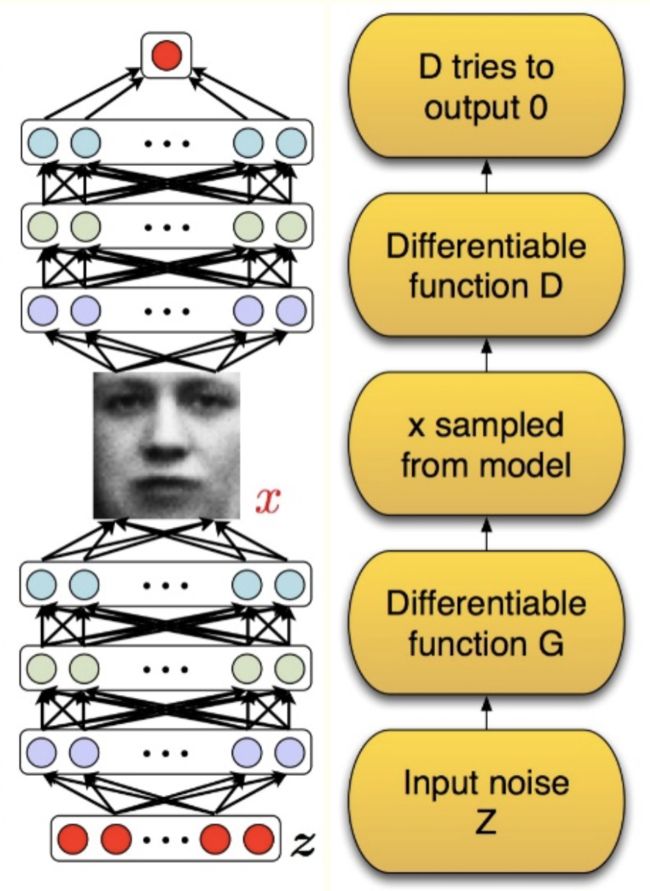
生成对抗网络的目标在于生成,我们传统的网络结构往往都是判别模型,即判断一个样本的真实性。而生成模型能够根据所提供的样本生成类似的新样本,注意这些样本是由计算机学习而来的。
GAN一般由两个网络组成,生成模型网络,判别模型网络。
生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。
举个例子:生成网络 G 好比假币制造团伙,专门制造假币,判别网络 D 好比警察,专门检测使用的货币是真币还是假币,G 的目标是想方设法生成和真币一样的货币,使得 D 判别不出来,D 的目标是想方设法检测出来 G 生成的假币。
传统的判别网络:

传统的判别网络
生成对抗网络:
生成对抗网络
在训练的过程中固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡),此时生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%。
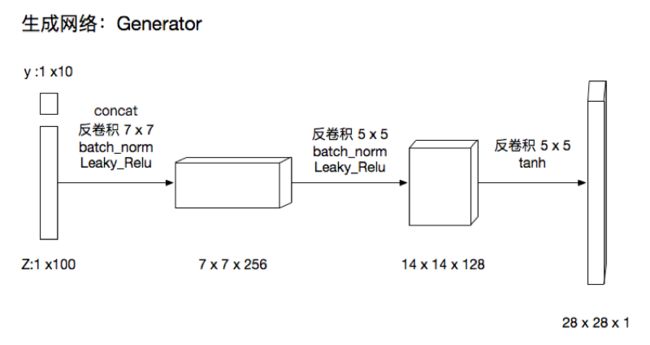
下面展示一个cDCGAN的例子(前面帖子中写过的)
生成网络
生成网络
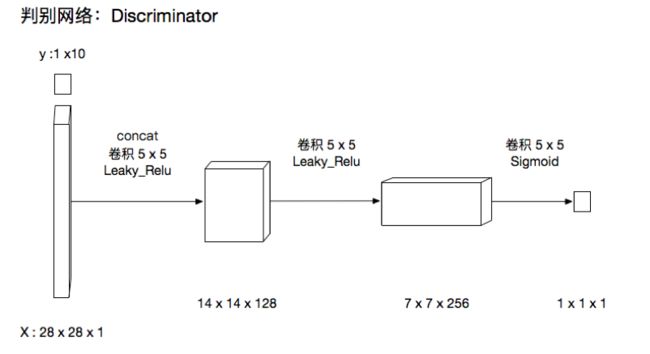
判别网络
判别网络
最终结果,使用MNIST作为初始样本,通过学习后生成的数字,可以看到学习的效果还是不错的。

生成网络