最近遇到一个使用hbck -repair修复HBase元数据遇到的坑,被坑得不清,周末都没休息好,时间全花在给hbck填坑了。今天抽时间在测试环境重现了这个bug,总算把整个流程搞明白了,记录下来,分享给技术的朋友们。
详细的排查过程如下:
一、问题出现
最近备集群春节后缩容下架大量的机器,由于缓存问题导致集群不稳定(这个问题后面会专门写文章来分析),因此在22号凌晨的时候对备份集群做了重启,重启后集群正常。但是第二天,备集群管理的同事反馈说接口成功率比较低,日志反馈是有region没上线引起,95c85b3886f19a0637a3b8b7749755e1 not deployed on any region server
负责的同事使用如下hbase shell命令进行上线操作:
assign '95c85b3886f19a0637a3b8b7749755e1'
但是无法上线成功,于是联系我上来一起跟进。
二、开始排查
1、首先查看master的日志,看看有什么报错信息
具体信息如下日志所示:
master.HMaster: Client=hbaseadmin//ip_address1 assign tablename1_201707,745,1553316101646.95c85b3886f19a0637a3b8b7749755e1.
master.AssignmentManager: Force region state offline {95c85b3886f19a0637a3b8b7749755e1 state=OFFLINE, ts=1553400041143,server=null}
master.AssignmentManager: Assigning tablename1_201707,745,1553316101646.95c85b3886f19a0637a3b8b7749755e1. to 9.7.155.40,60020,1553187654611
2019-03-24 12:00:41,146 INFO [FifoRpcScheduler.handler1-thread-80] master.RegionStates: Transition {95c85b3886f19a0637a3b8b7749755e1 state=OFFLINE, ts=1553400041144, server=null} to {95c85b3886f19a06
37a3b8b7749755e1 state=PENDING_OPEN, ts=1553400041146, server=9ip_address2,60020,1553187654611}
.......此处省略1000个字
zookeeper.ZKAssign: master:60000-0x162d87d74bf0b8a, quorum=cft-history-db-ss-hbase-zk-4:2181,cft-history-db-ss-hbase-zk-3:2181,cft-history-db-ss
-hbase-zk-2:2181,cft-history-db-ss-hbase-zk-1:2181,cft-history-db-ss-hbase-zk-5:2181, baseZNode=/hbase_cft_history_db_ss Creating (or updating) unassigned node 95c85b3886f19a0637a3b8b7749755e1 with OFFLINE state
从上面的日志中可以看出,这个region尝试在9ip_address2这台regionserver上进行上线操作,但是不成功,后面这个region又尝试在多台机器上尝试上线,均失败了。从这些日志中无法快速定位出region无法上线的原因。
2、查看regionserver的日志找到region不能上线的直接原因
继续查看9ip_address2这台regionserver的日志,发现了region不能上线的原因,具体日志如下:
ERROR [RS_OPEN_REGION-ip_address4:60020-6] regionserver.HRegion: Could not initialize all stores for the region=tablename1_201707,745,1553316101646.95c85b3886f19a0637a3b8b7749755e1.
ERROR [RS_OPEN_REGION-ip_address4:60020-6] handler.OpenRegionHandler: Failed open of region=tablename1_201707,745,1553316101646.95c85b3886f19a0637a3b8b7749755e1., starting to roll back the global memstore size.
java.io.IOException: java.io.IOException: java.io.FileNotFoundException: File does not exist: /hbase/data/default/tablename1_201707/7c89f0da4b54a4cc168fe2284e276bb3/i/0a0bed4104a24af280c69e6b67b9501c_SeqId_2_
从上面日志可以看出,95c85b3886f19a0637a3b8b7749755e1上线的时候会去读取7c89f0da4b54a4cc168fe2284e276bb3下面的0a0bed4104a24af280c69e6b67b9501c_SeqId_2_这个hfile文件,而这个文件不存在,导致失败。
在HBase中,一般是region有做分裂后,又还没来得及做major_compact,导致子region中存在指向链接文件,这样才会去读取另外一个region的信息,使用hdfs命令直接查看该region下面的HFile文件,证实猜想是正确的,如下文件列表所示:
/hbase/data/default/tablename1_201707/95c85b3886f19a0637a3b8b7749755e1/i/0a0bed4104a24af280c69e6b67b9501c_SeqId_2_
/hbase/data/default/tablename1_201707/95c85b3886f19a0637a3b8b7749755e1/i/0a0bed4104a24af280c69e6b67b9501c_SeqId_2_.7c89f0da4b54a4cc168fe2284e276bb3
这个就是链接文件了
备注:为了控制篇幅,这里只显示两个相关的文件,并把文件的权限、属组和属主都去掉了,另外把IP和表名相关信息也替换掉了。
但是这又着实很奇怪,region分裂后,子region的链接文件的命名规则如下:
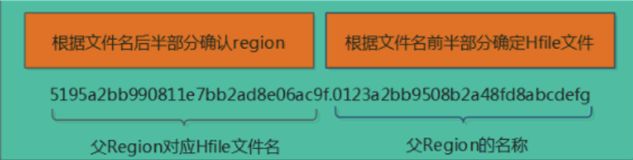
但是,仔细看上面的HFile的链接文件和文件就会发现,链接文件的前半部分的父region的文件名和本Region的文件名一模一样。这太奇怪了,正常是不可能文件名一模一样的。
3、跟踪父region的变动情况
于是,继续通过查看master日志跟踪7c89f0da4b54a4cc168fe2284e276bb3这个父region的相关分裂日志,如下:
Handled SPLIT event; parent=tablename1_201707,745,1498621284887.7c89f0da4b54a4cc168fe2284e276bb3., daughter a=tablename1_201707,745,1552927092514.ad1d42c37c6f13d9bccc9944fd8740ea., daughter b=tablename1_201707,745498567#2017-07-2710:00:17#1991763146,1552927092514.c35511f97dccac11ea9de6aebf467cb4., on 9.7.157.9,60020,1534514346802
从日志中可以看出,7c89f0da4b54a4cc168fe2284e276bb3通过split操作分裂为了ad1d42c37c6f13d9bccc9944fd8740ea和c35511f97dccac11ea9de6aebf467cb4两个region,根本就没有95c85b3886f19a0637a3b8b7749755e1什么事。继续查看日志,发现如下异常日志:
master.HMaster: Client=hbaseadmin//ip_address3 offline tablename1_201707,745,1498621284887.7c89f0da4b54a4cc168fe2284e276bb3.
#本来是下线状态的母region又被下线了一次
master.CatalogJanitor: Daughter region does not exist: ad1d42c37c6f13d9bccc9944fd8740ea, parent is: 7c89f0da4b54a4cc168fe2284e276bb3
#子region不知道被清理掉了
regionserver.HRegionFileSystem: Trying to open a region that do not exists on disk: hdfs://hbase-ns-cft-history-db-ss/hbase/data/default/tablename1_201707/c35511f97dccac11ea9de6aebf467cb4
master.CatalogJanitor: Daughter region does not exist: c35511f97dccac11ea9de6aebf467cb4, parent is: 7c89f0da4b54a4cc168fe2284e276bb3
#另一个子region也不知道被清理掉了
master.CatalogJanitor: Deleting region tablename1_201707,745,1498621284887.7c89f0da4b54a4cc168fe2284e276bb3. because daughter splits no longer hold references
Region directory (hdfs://cluster1/hbase/data/default/tablename1_201707/7c89f0da4b54a4cc168fe2284e276bb3) was empty, just deleting and returning!
catalog.MetaEditor: Deleted tablename1_201707,745,1498621284887.7c89f0da4b54a4cc168fe2284e276bb3.
#master检查到母region上没有任何的链接文件后,直接清理掉了。
备注:这里日志去掉了时间和部分信息,只保留了核心的日志!
从上面日志看出7c89f0da4b54a4cc168fe2284e276bb3被来自ip_address3的IP强行下线,并且master发现这个region的两个子region的文件也不见了。master发现母region没有了引用链接后,也被清理掉了。因此前面95c85b3886f19a0637a3b8b7749755e1去读取链接中指向的母region的HFile文件不存在,导致region上线异常。
三、排查和解决问题
此时,有点一头雾水,但是有个关键的点是c89f0da4b54a4cc168fe2284e276bb3是直接被ip_address3这个IP的客户端下线的,一定是有什么操作触发了异常的操作。于是找管理备集群的同事确认,集群管理的同事反馈没有执行任何下线的操作,只是执行了hbck -repair操作,-repair 打开所有的修复选项,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps。初步怀疑是hbck执行repair的时候做了“坏事”。
想快速修复线上问题,想首先确认一下95c85b3886f19a0637a3b8b7749755e1这个region是什么时候创建的,搜索了master的日志,发现没有任何的记录。继续观察95c85b3886f19a0637a3b8b7749755e1这个region中的文件,由于链接文件和region中的HFile文件名称相同,并且HFile文件创建的时候还是2017年的,想到一个快速上线region的思路。
本来Region的链接文件就是去读取这个文件,这个文件在自己的region下面,那就不需要通过链接文件去读取了。因此解决办法就是讲链接文件移走,在上线即可,操作如下:
hadoop fs -mv link_filename backupdir
assign 'regionname'
操作完成后,接口成功率就上去了:
至此,问题得到解决,但是还是有三个地方有疑惑:
1、95c85b3886f19a0637a3b8b7749755e1是什么时候创建的?(初步怀疑是hbck搞的鬼,待验证)
2、95c85b3886f19a0637a3b8b7749755e1上的HFile文件是怎么来的?(初步猜想是hbck从其他三个region拷贝过来的)
3、为什么hbck会去下线正常的子region?
这些如果能找到hbck -repair的日志也能确定具体hbck干了什么“坏事”,可惜集群管理的同事使用的是命令>号直接覆盖掉了日志,导致无法确定具体的原因。因此只能通过测试环境来重现该问题。
四、测试重现,找到罪魁祸首
通过之前的排查,发现几个表都是数据量比较大,分裂后,还没做完major_compact,使用hbck -repair操作会触发类型的问题。因此在测试环境构造对应环境,我的测试环境有两个region,如下截图所示:
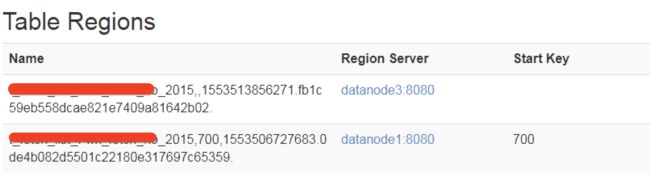
重现步骤如下:
1、对第一个region进行split操作,操作命令如下:
split 'fb1c59eb558dcae821e7409a81642b02'
2、分裂成功并且子region上线成功,日志如下:
SPLIT event; parent=table_name2_2015,,1553513856271.fb1c59eb558dcae821e7409a81642b02., daughter a=table_name2_2015,,1553514657067.54c8d09ca7d5fa3ee549cebf118045f5.daughter b=table_name2_2015,34992944,1553514657067.b32e72a1179edb587c9768621f54bb2e., on datanode3,60020,1552573473932
从上面的日志可以看出fb1c59eb558dcae821e7409a81642b02成功分裂为了54c8d09ca7d5fa3ee549cebf118045f5和b32e72a1179edb587c9768621f54bb2e这两个region,并且在datanode3,60020,1552573473932这个regionserver上上线成功饿了。
3、趁还没做major_compact的时候发起hbck -repair的操作,命令如下:
hbck -repair >>repair.log 2>&1
4、查看master的日志,看看异常情况,发现确实是hbck把三个region都下线了,日志如下所示:
Client=hbaseadmin//ip_addr5 offline table_name2_2015,,1553514657067.54c8d09ca7d5fa3ee549cebf118045f5.
Transition {54c8d09ca7d5fa3ee549cebf118045f5 state=OPEN, ts=1553514722000,server=datanode3,60020,1553514716244} to {54c8d09ca7d5fa3ee549cebf118045f5 state=OFFLINE, ts=1553514763802, server=datanode3,60020,1553514716244}
Client=hbaseadmin//ip_addr5 offline table_name2_2015,,1553513856271.fb1c59eb558dcae821e7409a81642b02.
Transition {fb1c59eb558dcae821e7409a81642b02 state=SPLIT, ts=1553514721575, server=null} to {fb1c59eb558dcae821e7409a81642b02 state=OFFLINE, ts=1553514763815, server=null}
Client=hbaseadmin//ip_addr5 offline table_name2_2015,34992944,1553514657067.b32e72a1179edb587c9768621f54bb2e.
Transition {b32e72a1179edb587c9768621f54bb2e state=OPEN,ts=1553514722034,server=datanode3,60020,1553514716244} to {b32e72a1179edb587c9768621f54bb2e state=OFFLINE, ts=1553514764826, server=datanode3,60020,1553514716244}
备注:这里对日志做了下优化,去掉了时间和部分内容,只保留核心内容
5、此时页面上也由原来的3个region变成了孤零零的1个region,如下图所示:

6、再分析hbck -repair的日志,终于发现hbck干的“坏事”了,具体日志如下:
ERROR: (region table_name2_2015,,1553514657067.54c8d09ca7d5fa3ee549cebf118045f5.) Multiple regions have the same startkey:
ERROR: (region table_name2_2015,,1553513856271.fb1c59eb558dcae821e7409a81642b02.) Multiple regions have the same startkey:
ERROR: (regions table_name2_2015,,1553513856271.fb1c59eb558dcae821e7409a81642b02. and table_name2_2015,34992944,1553514657067.b32e72a1179edb587c9768621f54bb2e.) There is an overlap in the region chain.
#执行merge region的操作,景三个region合并成一个region
util.HBaseFsck: == [hbasefsck-pool1-t26] Merging regions into one region: { meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5, deployed =>replicaId => 0 },{meta=>null,hdfs=>hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02, deployed => , replicaId => 0 },{ meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e, deployed => , replicaId => 0 }
#下线三个region
[hbasefsck-pool1-t26] Offlining region: { meta => null, hdfs =>hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5, deployed => , replicaId => 0 }
util.HBaseFsck: [hbasefsck-pool1-t26] Offlining region: { meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02, deployed => , replicaId => 0 }
util.HBaseFsck: [hbasefsck-pool1-t26] Offlining region: { meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e, deployed => , replicaId => 0 }
#创建了一个新region
Created new empty container region: {ENCODED => ed8942007ba8404039022851cc77db6a, NAME => 'table_name2_2015,,1553514764826.ed8942007ba8404039022851cc77db6a.', STARTKEY => '', ENDKEY => '700'} to contain regions: { meta => null, hdfs =>hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5, deployed => , replicaId => 0 },{ meta => null, hdfs =>hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02, deployed => , replicaId => 0 },{ meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e, deployed => , replicaId => 0 }
[hbasefsck-pool1-t26] Merging { meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5, deployed => , replicaId => 0 } into hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a
#将三个region的HFile文件move到新的region目录下
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5/.tmp into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/.tmp
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5/i into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/i
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5/recovered.edits into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/recovered.edits
util.HBaseFsck: Sidelining files from hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5/.tmp into containing region hdfs://slave:9000/hbase/.hbck/hbase-1553514761533/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5/.tmp
util.HBaseFsck: Removing old region dir: hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5
util.HBaseFsck: [hbasefsck-pool1-t26] Sidelined region dir hdfs://slave:9000/hbase/data/default/table_name2_2015/54c8d09ca7d5fa3ee549cebf118045f5 into hdfs://slave:9000/hbase/.hbck/hbase-1553514761533
util.HBaseFsck: [hbasefsck-pool1-t26] Merging { meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02, deployed => , replicaId => 0 } into hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02/.splits into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/.splits
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02/.tmp into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/.tmp
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02/i into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/i
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02/recovered.edits into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/recovered.edits
util.HBaseFsck: Removing old region dir: hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02
util.HBaseFsck: [hbasefsck-pool1-t26] Sidelined region dir hdfs://slave:9000/hbase/data/default/table_name2_2015/fb1c59eb558dcae821e7409a81642b02 into hdfs://slave:9000/hbase/.hbck/hbase-1553514761533
util.HBaseFsck: [hbasefsck-pool1-t26] Merging { meta => null, hdfs => hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e, deployed => , replicaId => 0 } into hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e/.tmp into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/.tmp
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e/i into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/i
util.HBaseFsck: [hbasefsck-pool1-t26] Moving files from hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e/recovered.edits into containing region hdfs://slave:9000/hbase/data/default/table_name2_2015/ed8942007ba8404039022851cc77db6a/recovered.edits
util.HBaseFsck: Removing old region dir: hdfs://slave:9000/hbase/data/default/table_name2_2015/b32e72a1179edb587c9768621f54bb2e
INFO [main] util.HBaseFsck: Loading HBase regioninfo from HDFS...
至此,我们有已经知道了hbck -repair干的坏事和我们之前猜测的差不多,主要问题是hbck在修复的时候对已经split的region但是还没有来得及做大合并的region判断有问题,会将三个region(1个母region和2个子region)进行下线,新创建一个region,并把三个region涉及到的所有文件都移动到新的region中,不会导致数据的丢失,但是会导致region无法上线,影响业务。
五、代码分析
稍后再补充
备注:hbase 0.98 和 hbase 1.26都有此问题