折800缓存服务的构建
1. 背景
zhe800公司内大量使用redis,且用途多样:缓存、队列、数据库,都有功能。同时公司内对redis的使用比较随意,每个应用按自己的需求要求运维部署redis-server,导致对redis的使用很混乱,运维部门都无法精确得知redis-server的部署情况。经过长时间的调查、搜集资料才整理出公司内redis的使用情况,目前部署数百多个redis-server实例、版本分为:2.8.9、2.8.11、2.8.17、2.8.19、2.8.23 多种。
2. 需求的演变
鉴于公司redis使用、管理混乱的情况,公司要求改善对redis的使用和管理,由成都“基础架构部”负责此项改进。此时产生了第一阶段需求:
1、通过一个统一管理系统管理公司内所有的redis进程
2、可以通过这个管理系统监控redis的运行状态
3、redis资源通过管理系统来分配
针对第一阶段的需求,我们基础架构部和用户、运维部、技术委员会进行了多次讨论,认为目前redis使用的问题:
没有实现跨机房高可用,这点很重要,公司内所有应用要求必须跨机房高可用。
没有考虑横向扩展问题。
一部分队列、持久化等功能不适合使用redis,应该使用更“专业”的队列系统和数据库解决。
此时对第一阶段需求进行了修改,产生了第二阶段需求:
1、redis仅作为缓存使用。
2、实现横向扩展。
3、实现跨机房高可用,双机房至少要实现“温备”。
4、由一个后台系统管理、分配、监控redis资源。
其中第3个需求:实现跨机房高可用最为困难,因为缓存的典型场景:缓冲数据库查询,如果主机房失效后,切换到备机房的缓存服务,此时备机房缓存没有数据(是”冷“的),会导致对数据库(MySQL)的查询量爆增;因此要求备机房的缓存必须至少有主机房的部分数据,在主机房失效的情况下才能防止数据库查询量爆增,而且在缓存的持续使用下,备机房缓存会很快达到主机房的状态。
因此跨机房数据同步是必须的。
3. 选型
在最终需求的指导下,已经明确我们基础架构部需要打造一套缓存服务系统,包含redis-server和管理、监控系统。
此时我们有两种方案可选择:
1. 基于代理的横向扩展方案
以codis为代表的基于代理的集群方案,通过在redis-client和redis-server之间增加一个代理层,通过代理层sharding链接到正确的redis-server进行操作。
2. 基于redis官方集群的方案
redis从3.0版开始提供了很受期待的集群功能,按照CAP理论,redis cluster属于保证AP,放弃C,仅能提供最终一致性。按照redis cluster的协议,client需要在本地sharding,选择正确的redis结点,然后进行操作,否则会返回MOVE错误。
调研结论是:采用redis官方集群方案
有以下原因促使我们选择redis cluster方案:
1、基于代理的方案会导致性能下降,对于一个缓存服务来说性能很重要。
2、redis cluster方案较简单,不需要部署额外的进程,其本身就能实现高可用了,如果是基于代理的方案,代理本身也需要高可用,这增加了复杂度。
3、redis cluster是官方支持的自带功能,比起第三方开发的代理进程,可能更稳定可靠。
4、redis cluster能实现读扩展、读写分离功能;如果使用代理,那么读写扩展时必须同时考虑redis-server和代理程序。
redis cluster仍然不能实现跨机房容灾,跨机房高可用的功能最后决定由基础架构部自行实现
4. redis cluster简介
其基本思想是将数据放置于槽(slots)中,slot有0x3fff(16384)个。为了实现数据分片,这些槽分布在多个redis master结点中,为了实现高可用,每个master结点拥有零到多个slave结点,这些slave同步保存master的数据,一旦master crash以后,会选举他的slave结点成为新的master。

仅master结点可写入,然后数据会异步同步到slave,slave可读不可写。
因此理想情况下:结点永不crash、只读写master结点,redis cluster可保证强一致。 但因为现实使用中,结点可能crash,且可读slave结点,因此redis cluster仅能保证最终一致性。
redis cluster通过谣言传播同步结点的状态,每一个结点都保存了所有结点的状态信息,其中最重要的是:结点的ip+端口、每个节点包含的slots。
client 集群模式流程:
1、从任意一个集群的结点获取所有结点的状态(使用CLUSTER NODES命令),同时获知了每一个slot所在的结点。结点有两个角色:master/slave。
2、在get/set/hget/hset等命令时,对key进行计算:crc16(key) & 0x3fff,所得的结果就是slot编号。
3、通过slot编号获取结点的ip+port,然后发送此结点。
4、此时如果返回-ASK ip:port错误,表明slot临时发生了变化,此时应往ASK指定的结点先发送ASKING命令,再发送实际的命令。
5、此时如果返回-MOVED slot-number ip:port错误,表明集群发生了变化(扩容、缩减、槽迁移过),则先将命令发送到MOVED错误指明的结点后,重新获取集群结点状态,以同步最新的结点状态。

5. 管理系统的设计与实现
zhe800基于redis cluster的缓存服务被命令为z(he800-r)edis,包含一个管理系统对所有缓存集群进行管理,以及双机房数据同步机制,保证主备两个机房之间部分数据同步,实现双机房容灾。
对于zedis,我们有几个指导原则:
1、简单:复杂的方案容易出错,且成本高,因此在简单和复杂之中选择简单的方案。
2、用户透明:不要要求用户了解大量的细节才能使用。
3、可用:可正常使用,可从错误中恢复。

5.1 管理系统的功能设计
缓存集群的操作:
容量扩容/读写扩容:增加1个到多个分片,同时扩展了读写能力。
高可用/读扩容:仅增加slave结点数,增强高可用性,同时扩展了读能力。
1、分配:按应用的需求分配一个全新的redis cluster,如果配置了跨机房容灾选项,还会按需求在备机房启动一个灾备集群。
2、下线:将一个运行中的redis cluster删除,并进行清理。
3、扩容:
4、缩减:扩容的逆操作,支持读写缩减和读缩减。
监控:
1、物理机资源监控:监控物理机当前的资源,为缓存集群的操作提供依据。
2、集群监控:对每个节点到集群本身进行监控,提供给运维查看。
3、报警:对接公司报警系统,遇到结点crash、集群不可用等情况及时发出报警
缓存集群的操作需要以物理机资源数据为依据,这部分数据通过zabbix获取。同时集群的每个节点需要使用cgroup进行资源隔离,这些操作都由管理后台自动进行。
对物理机的操作:启动redis-server进程、创建执行文件夹、生成redis.conf文件等操作通过salt进行,因为公司内每台服务器都安装了salt-minion,因此可直接利用。
5.2 事务支持
对redis cluster的各种操作都是通过redis client向redis-server发送命令实现,但是这些操作必须是原子操作,长时间的操作必须可中途放弃并会滚到初始状态,否则对redis cluster的操作风险会比较高,运维人员可能不敢使用管理系统。
事务系统采取模仿数据库的一种实现方式:记录日志。数据库日志分为:undo、redo、undo/redo三种形式。
我们采取undo日志的形式,对于管理系统四大操作:
分配
下线
扩容
缩减
都通过事务系统执行。
模仿数据库,事务管理器提供三个原语:
1、begin: 开始一个事务,并返回一个事务id(tid)
2、abort-rollback: 中途放弃,会滚到begin时候的状态
3、commit: 提交事务,标记事务已经完成。
四大操作每一个步骤都会在操作成功后,记录undo日志到文件系统中,因此还需要确保每个“步骤”是原子操作,如果遇到abort或者错误时,逆向执行undo日志中命令就能恢复到初始状态了。如果rollback仍然失败,则说明遇到了管理系统无法处理的故障(如机器断电、网络中断等)此时需要暂停会滚,通知运维人员恢复故障,再进行回滚。

6. 高可用的实现
6.1 redis cluster的高可用
redis很早就可以通过master-slave机制实现双机热备,到了cluster时代,仍然保留了master-slave机制。
在cluster模式中,每个master结点保存了一部分slots,同时每个master结点可设置0~多个slave结点,master的数据会异步同步到slave结点(redis的特点:所有IO操作皆异步),这样一个master-slave的组合可称之为一个partition;一个partition是高可用的:
slave结点crash,对集群本身无影响,对partition无影响;slave结点重新连接上master后会检查自己与master的数据差别,如果差距太大,会先进行一次全量同步,然后开始增量同步。
master结点crash,对集群本身无影响,对partition有影响;集群会选举一个slave作为新的master,因为slave结点几乎有master结点的所有数据,因此数据仅有小概率丢失。
partition整体crash,集群会整体不可用,因为集群认为slots不连续了,保存在这个partition中的slots无法访问。如果没开启持久化,会导致这部分数据永久丢失。
可见,redis cluster做到了一定的高可用,我们使用jedis测试结果来看,在一个1主1备的redis cluster中,随机kill一个结点不会导致任何错误,但kill一个master结点和它所有的slave结点就会导致集群不可用的错误,此时无法get/set数据。
6.2 对于高可用的思考
对于redis cluster高可用的研究和实验发现,其应对单机房高可用是可以胜任的,已有的客户端:jedis新版本也能很好的处理高可用问题。
但对于跨机房高可用/容灾,仍然没有发现现成的方案可供使用,对此有以下方案被提出:
1、客户端双写:客户端需要连接到主、备两个集群,同步写主、异步写备;平时读主集群的数据,主集群不可用后马上切换为同步写备、读备。
2、集群间数据同步:开启持久化,然后同步redis的数据库文件。
3、服务端双写:redis-server将set/hset等写命令再写一份到备集群。
最终我们选择了第三个方案:服务端双写。原因为:
按照用户透明原则,如果要求客户端双写,客户端需要做的事太多,而服务端双写方案客户端仅需处理主备集群切换就可以了。
集群间数据同步方案,要求数据先写到文件中,在同步到灾备集群,这其实是不必要的,因为如果做到双机房容灾,持久化都是可以关闭的,因为partition整体crash的集群大幅度下降了(按平方下降,如果单个partition crash的几率为p,主备parttion同时crash的几率仅有p^2,且p随着slave结点的数量指数级的变小),退一步说:因为本身为缓存服务,可接受少量数据丢失。
服务端双写足够简单,仅需要将客户单对redis-server的写入命令复制一份发送到灾备集群即可。
服务端双写并不需要完全双写,仅保证灾备集群拥有主集群的部分数据即可,因为对于缓存服务来说,只要发生灾备时,灾备集群不“冷”就可以接受了;同时这也节省了机房间光纤带宽。
6.3 跨机房高可用
跨机房高可用的基本思想为:在主备两个两个机房各启动一个redis cluster,主机房集群在写入数据的时候,同时写入一分到备机房。
要达到以上设计目的,必须对官方redis进行修改,我们选择了版本3.2.0为基础进行修改。 redis的一个重要设计思想是所有IO操作皆异步非阻塞进行,为此redis封装了ae一个事件处理库封装了各个操作系统提供的事件处理模型:
OS X/Darwin/BSD:kqueue
Linux:epoll
Sun OS:evport
Others:select
在3大操作系统中并不支持Windows的IO Complete Port,原因是IOCP是真异步模型,在收到事件通知时,数据已经接收到/发送完毕,而不像epoll,kqueue等模型,在收到事件通知时,还需要再调用read/write,通知仅仅是告诉用户态可读/可写了,而远不同于IOCP,通知是通知用户态读/写已经完成了。由此可见IOCP现在比较难融入redis现有的IO层中。
我们先开始研究redis的代码,可得知它的IO层设计:

redis执行一个命令的时序:

最终我们决定在processInputBuffer中,解析redis协议时,将写操作按配置的百分比过滤后,复制一份发送到备机房;此时有新的考虑:
备机房的接收者也是集群,如果需要发送给集群,那么势必会增加对redis-server代码的修改程度,因为还必须处理目标集群的高可用、sharding问题,风险增加。我们希望对redis-server的修改尽可能的小。
如果机房间光纤中断,会丢失一部分数据;虽然作为缓存集群,数据可以丢失一小部分,但能保证数据不丢失尽量不丢。
只能写入另一个redis cluster中,不灵活。
因此我们增加了一个名为zedis-gateway的代理程序,redis-server中复制出来的写操作先发送到zedis-gateway,zedis-gateway负责对这些写操作进行处理,发送到备份集群。增加zedis-gateway的好处:
zedis-gateway可灵活处理接收到的写操作,比如:写入备份集群、写入MySQL数据库中、等等。
zedis-gateway负责处理较复杂的,写入备份集群的failover、sharding问题,简化了对redis-server的修改。
如果机房间光纤中断,zedis-gateway可将写操作暂时写入文件;等待通信恢复后在从文件中发送暂时保存的写操作;数据可以不丢失。
首先,我们为redis增加了两个配置项:
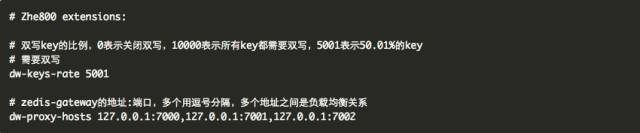
同时zedis-gateway也需要高可用,我们简单实现:
每个redis-server可配置多个zedis-gateway地址,从中随机选择一个连接发送写命令。
如果某个zedis-gateway地址连接不上,或连接错误,则再随机选一个,直到能连上一个正确的或者一个也不能连上。
如果没有一个zedis-gateway地址连接成功,则写入错误日志;但不影响其他操作。
最后将官方版redis-server修改为:

双机房容灾zedis集群结构为:
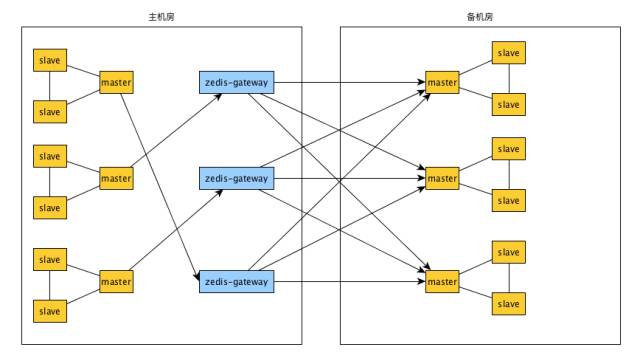
实现结果:
我们实现了主备机房间集群数据0~100%同步,但为了节省机房间光纤带宽,一般不允许开启100%同步。
性能损失:在100%双写的配置下,性能损失<10%。
动态调整:所有关于双写的配置都可以在运行中随时调整。
可维护:zedis-gateway可以随时更新版本,而不会影响双写。
7. 问题与展望
目前的zedis还存在一些问题,需要我们持续已经,以达到完善。
1、redis client中,只有jedis对集群支持最好,其他语言版本,如ruby、node.js、golang版本的客户端还需要进行一定改造才能支持redis cluster。
2、zedis-gateway目前还是单进程、单线程模型,如果未来它成为瓶颈,我们还需要增加进程数;后续根据需求也许需要将它改造为类似nginx的多进程模型。
3、修改版的redis还需要优化。
4、目前只能从主到备双写数据,如果从主切换到备,再从备切换到主,会丢失一部分数据;因为目前定位为缓存集群,因此可接受这个损失,如果今后需要升级作为内存数据库使用,我们就还需要处理这个问题。
5、只有部分命令支持双写,剩余的还在添加中。