最近研究OKhttp 发现Okhttp内部使用Okio这个开源库来进行数据的读写,一时好奇就拿来研究,发现里面有很多可以提取的干货知识点,现在从源码解析的角度分享给大家。
一.首先看一下使用入口,举个栗子
public void writeFile() throws Exception {
File file = new File("./text.txt");
BufferedSink sink = Okio.buffer(Okio.sink(file));
sink.writeUtf8("Hello, java.io file!");
sink.close();
}
public void readFile() throws Exception {
BufferedSource source = Okio.buffer(Okio.source(file));
source.readUtf8();
source.close();
}
大家可以看到OKio的使用非常简单,基本两步就实现了IO的写入和读取。下面我们逐一进行细致的分析,每一步分析都会伴随着一些知识点的引入和作者的小技巧的发现。
二.先介绍几个类
Segment : 在OKio中是映射作为一个内存缓冲段使用的,SIZE = 8192SegmentPool :在OKio中负责生成内存缓冲段,并在内部维护了一个链表用来回收这些内存段以供程序下次使用。
干货来了
从SegmentPool这个类中我们可以学到如何高效维护链式内存段,链式内存段的分发与回收,减少无效内存使用。以及能够看到作者为整个框架减少GC的Java内存维护技巧。
/**
* A collection of unused segments, necessary to avoid GC churn and zero-fill.
* This pool is a thread-safe static singleton.
*/
final class SegmentPool {
/** The maximum number of bytes to pool. */
static final long MAX_SIZE = 64 * 1024; // 64 KiB.
/** Singly-linked list of segments. */
static Segment next;
/** Total bytes in this pool. */
static long byteCount;
private SegmentPool() {}
//获得一个内存段
static Segment take() {
synchronized (SegmentPool.class) { //独占锁保护多线程使用
if (next != null) { //取出链表中一个节点,缓存池中保存内存数减少
Segment result = next;
next = result.next;
result.next = null;
byteCount -= Segment.SIZE;
return result;
}
}
//如果当前没有申请过内存则直接new一个内存段
return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.
}
static void recycle(Segment segment) {
if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();
if (segment.shared) return; // This segment cannot be recycled.
synchronized (SegmentPool.class) {
if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.
//回收一个节点,加入链表池中
byteCount += Segment.SIZE;
segment.next = next;
segment.pos = segment.limit = 0;
next = segment;
}
}
}```
不要问我为啥拷贝源码,因为干货满满的。。。作者使用了链式存储的方式,维护了框架需要的内存,在内存段废弃的的时候使用链表保存起来以便下次使用,这种空间换取时间的方式不仅减少了申请内存的时间,也减少了系统本身的GC。可以说在对内存使用上做了极致优化。
Sink:文件写入接口。
public interface Sink extends Closeable, Flushable {
/** Removes {@code byteCount} bytes from {@code source} and appends them to this. */
void write(Buffer source, long byteCount) throws IOException;
/** Pushes all buffered bytes to their final destination. */
@Override void flush() throws IOException;
/** Returns the timeout for this sink. */
Timeout timeout();
/**
- Pushes all buffered bytes to their final destination and releases the
- resources held by this sink. It is an error to write a closed sink. It is
- safe to close a sink more than once.
*/
@Override void close() throws IOException;
}```
Source:数据源接口。
public interface Source extends Closeable {
/**
* Removes at least 1, and up to {@code byteCount} bytes from this and appends
* them to {@code sink}. Returns the number of bytes read, or -1 if this
* source is exhausted.
*/
long read(Buffer sink, long byteCount) throws IOException;
/** Returns the timeout for this source. */
Timeout timeout();
/**
* Closes this source and releases the resources held by this source. It is an
* error to read a closed source. It is safe to close a source more than once.
*/
@Override void close() throws IOException;
}
BufferedSink:写入接口扩展接口。
BufferedSource:读取接口的扩展接口。
Buffer: BufferedSink,BufferedSource接口的实现类,用于将数据写入缓冲区和从缓冲区里读取数据。(不过这个是内部使用的,外部操作另有其人)
隆重介绍:
RealBufferedSink:将缓存区的数据写入IO中。
RealBufferedSource:将缓冲区的数据读取出来。
继承关系如下
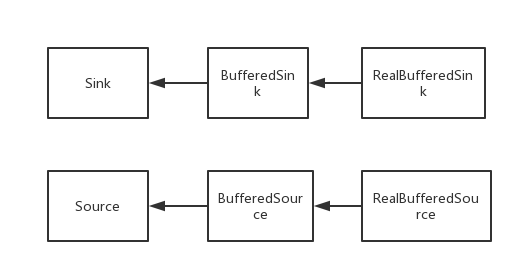
这两个类的内部都有一个Buffer 和一个 Sink/Source 对象用于实际的IO操作,框架基本流程就是
RealBufferedSink:程序中->链式缓冲区->IO
RealBufferedSource:IO->链式缓冲区->程序中
当然这两个类只是实现类的冰山一角,不过比较有代表性,就拿来分析了,其他的同理。咱们主要是学知识。。。!
下面从入口开始分析
Ohio.sink
/** Returns a sink that writes to {@code out}. */
public static Sink sink(OutputStream out) {
return sink(out, new Timeout());
}
private static Sink sink(final OutputStream out, final Timeout timeout) {
if (out == null) throw new IllegalArgumentException("out == null");
if (timeout == null) throw new IllegalArgumentException("timeout == null");
return new Sink() {
@Override public void write(Buffer source, long byteCount) throws IOException {
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0) {
timeout.throwIfReached(); //读取的时候判断是否超时
Segment head = source.head; //牵出缓存链表头部
int toCopy = (int) Math.min(byteCount, head.limit - head.pos); //判断链表节点数据长度
out.write(head.data, head.pos, toCopy); //写进实体IO中
head.pos += toCopy; //已经读取过数据的指针位移
byteCount -= toCopy; //数据总数指针位移
source.size -= toCopy; //缓存中数据改变
if (head.pos == head.limit) { //如果本节点数据完全读取则,删除本链表并删除这个节点
source.head = head.pop();
SegmentPool.recycle(head);
}
}
}
@Override public void flush() throws IOException {
out.flush();
}
@Override public void close() throws IOException {
out.close();
}
@Override public Timeout timeout() {
return timeout;
}
@Override public String toString() {
return "sink(" + out + ")";
}
};
}
可以看到Sink方法返回了一个对IO流的实体操作类,操作类直接在方法中实现。Buffer source 返回一个内存链表,byteCount 返回的是缓存数据大小。
在实际操作类中,write方法循环链表从中获取数据,写入流中,并回收这些内存块。因为数据已经存在内存中,数据块仅仅是指针被改变了,所以写入速度非常快。
下面我们看下谁调用这个write方法。
先看下我们是如何使用okio进行文件写入的
BufferedSink sink = Okio.buffer(Okio.sink(file)); sink.writeUtf8("Hello, java.io file!");
从之前的例子中我们可以看到Okio.buffer()这个方法注入了一个sink的接口,它到底去了哪里,又是怎么被调用的?下面会逐步解析这个代码段
/**
* Returns a new sink that buffers writes to {@code sink}. The returned sink
* will batch writes to {@code sink}. Use this wherever you write to a sink to
* get an ergonomic and efficient access to data.
*/
public static BufferedSink buffer(Sink sink) {
return new RealBufferedSink(sink);
}
我们看到buffer()这个方法注入了sink实体操作,返回了一个外部操作的RealBufferedSink类,由此可见真正进行写入操作融合的正是RealBufferedSink。
final class RealBufferedSink implements BufferedSink {
public final Buffer buffer = new Buffer();
public final Sink sink;
boolean closed;
RealBufferedSink(Sink sink) {
if (sink == null) throw new NullPointerException("sink == null");
this.sink = sink;
}
//实体操作类
@Override public BufferedSink writeUtf8(String string) throws IOException {
if (closed) throw new IllegalStateException("closed");
//将数据存入内部缓冲区
buffer.writeUtf8(string);
//将数据放入实体操作类中
return emitCompleteSegments();
}
@Override public BufferedSink emitCompleteSegments() throws IOException {
if (closed) throw new IllegalStateException("closed");
//计算缓冲区中所有数据
long byteCount = buffer.completeSegmentByteCount();
//将注入的数据实体操作类,进行操作,就是前面OKio sink方法生成的对象
if (byteCount > 0) sink.write(buffer, byteCount);
return this;
}
可以看到这个sink正是我们前面注入的sink对象,它执行了真正的写入操作。
这里面比较有亮点的是,我们可以看出不论是OKio的sink的实现还是ReadBufferedSink的实现都继承了Sink接口,遵循了设计模式中的依赖倒置原则,然后RealBufferedSink又使用装饰者模式将Buffer与Sink实体操作类结合构成了这一系列的操作,设计非常巧妙。
三.Buffer缓冲区
Buffer在OKio这个框架中处于核心位置,可以说这个类这是整个框架的精髓体现。
入口在这里,将一个字符串存入了缓冲区
buffer.writeUtf8(string);
我们下来分析下Buffer的结构
public final class Buffer implements BufferedSource, BufferedSink, Cloneable {
Buffer继承了BufferedSource和BufferedSink接口并对他们进行实现,同时为外部提供了读写接口对缓冲区操作
我们就分析writeUtf8这个方法吧,其他的方法也是同理。
@Override public Buffer writeUtf8(String string) {
return writeUtf8(string, 0, string.length());
}
@Override public Buffer writeUtf8(String string, int beginIndex, int endIndex) {
if (string == null) throw new IllegalArgumentException("string == null");
if (beginIndex < 0) throw new IllegalAccessError("beginIndex < 0: " + beginIndex);
if (endIndex < beginIndex) {
throw new IllegalArgumentException("endIndex < beginIndex: " + endIndex + " < " + beginIndex);
}
if (endIndex > string.length()) {
throw new IllegalArgumentException(
"endIndex > string.length: " + endIndex + " > " + string.length());
}
// Transcode a UTF-16 Java String to UTF-8 bytes.
for (int i = beginIndex; i < endIndex;) {
int c = string.charAt(i);
if (c < 0x80) {
Segment tail = writableSegment(1);
byte[] data = tail.data;
int segmentOffset = tail.limit - i;
int runLimit = Math.min(endIndex, Segment.SIZE - segmentOffset);
// Emit a 7-bit character with 1 byte.
data[segmentOffset + i++] = (byte) c; // 0xxxxxxx
// Fast-path contiguous runs of ASCII characters. This is ugly, but yields a ~4x performance
// improvement over independent calls to writeByte().
while (i < runLimit) {
c = string.charAt(i);
if (c >= 0x80) break;
data[segmentOffset + i++] = (byte) c; // 0xxxxxxx
}
int runSize = i + segmentOffset - tail.limit; // Equivalent to i - (previous i).
tail.limit += runSize;
size += runSize;
} else if (c < 0x800) {
// Emit a 11-bit character with 2 bytes.
writeByte(c >> 6 | 0xc0); // 110xxxxx
writeByte(c & 0x3f | 0x80); // 10xxxxxx
i++;
} else if (c < 0xd800 || c > 0xdfff) {
// Emit a 16-bit character with 3 bytes.
writeByte(c >> 12 | 0xe0); // 1110xxxx
writeByte(c >> 6 & 0x3f | 0x80); // 10xxxxxx
writeByte(c & 0x3f | 0x80); // 10xxxxxx
i++;
} else {
// c is a surrogate. Make sure it is a high surrogate & that its successor is a low
// surrogate. If not, the UTF-16 is invalid, in which case we emit a replacement character.
int low = i + 1 < endIndex ? string.charAt(i + 1) : 0;
if (c > 0xdbff || low < 0xdc00 || low > 0xdfff) {
writeByte('?');
i++;
continue;
}
// UTF-16 high surrogate: 110110xxxxxxxxxx (10 bits)
// UTF-16 low surrogate: 110111yyyyyyyyyy (10 bits)
// Unicode code point: 00010000000000000000 + xxxxxxxxxxyyyyyyyyyy (21 bits)
int codePoint = 0x010000 + ((c & ~0xd800) << 10 | low & ~0xdc00);
// Emit a 21-bit character with 4 bytes.
writeByte(codePoint >> 18 | 0xf0); // 11110xxx
writeByte(codePoint >> 12 & 0x3f | 0x80); // 10xxxxxx
writeByte(codePoint >> 6 & 0x3f | 0x80); // 10xxyyyy
writeByte(codePoint & 0x3f | 0x80); // 10yyyyyy
i += 2;
}
}
return this;
}
从源码中可以看到 writeUtf8 将字符串分解逐一保存到内存中,开辟内存的方法是
Segment tail = writableSegment(1);
/**
* Returns a tail segment that we can write at least {@code minimumCapacity}
* bytes to, creating it if necessary.
*/
Segment writableSegment(int minimumCapacity) {
if (minimumCapacity < 1 || minimumCapacity > Segment.SIZE) throw new IllegalArgumentException();
if (head == null) {
head = SegmentPool.take(); // Acquire a first segment.
return head.next = head.prev = head;
}
Segment tail = head.prev;//获取最后一个节点,如果最后一个节点空间不够,则再添加一个空节点
if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {
tail = tail.push(SegmentPool.take()); // Append a new empty segment to fill up.
}
return tail;
}
亮点再次出现了,原来在Buffer中保存缓冲数据的方法依然是链表保存法!
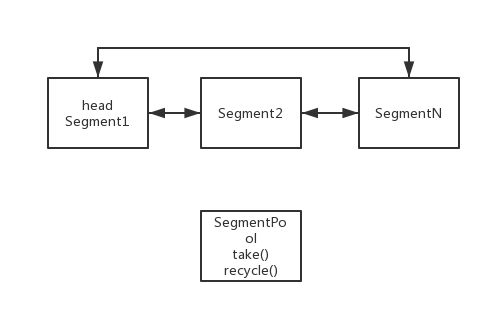
在Buffer中内存管理节点如下,需要缓冲数据节点时,先从SegmentPool中获取Segment节点,且自身形成链式内存保存缓冲数据,写入流的时候再从头节点中获取数据写入数据流中,最后SegmentPool回收使用后的缓冲节点(前面有介绍SegmentPool也是链式维护内存),以供下次使用。从这里可以看出,Okio使用一个大的双向链表池维护了框架所需要的内存空间(较少GC调用),而Buffer区中保存的数据同样使用链表结构,对数据进行的顺序读取和写入,读写数据就仅仅是改变了内存的指向,速度非常快(这样的数据结构兼具了读的连续性和写的可插入性)。这两点非常值得我们以后编程时借鉴。
四.超时机制
框架读取socket时使用了异步超时机制,下面详细分析下这种实现(是否能给我们以后编程带来启示)
public static Sink sink(Socket socket) throws IOException {
if (socket == null) throw new IllegalArgumentException("socket == null");
AsyncTimeout timeout = timeout(socket);
Sink sink = sink(socket.getOutputStream(), timeout);
return timeout.sink(sink);
}
开始解析timeout.sink
public final Sink sink(final Sink sink) {
return new Sink() {
@Override public void write(Buffer source, long byteCount) throws IOException {
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0L) {
// Count how many bytes to write. This loop guarantees we split on a segment boundary.
long toWrite = 0L;
for (Segment s = source.head; toWrite < TIMEOUT_WRITE_SIZE; s = s.next) {
int segmentSize = source.head.limit - source.head.pos;
toWrite += segmentSize;
if (toWrite >= byteCount) {
toWrite = byteCount;
break;
}
}
// Emit one write. Only this section is subject to the timeout.
boolean throwOnTimeout = false;
enter();
try {
sink.write(source, toWrite);
byteCount -= toWrite;
throwOnTimeout = true;
} catch (IOException e) {
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
}
@Override public void flush() throws IOException {
boolean throwOnTimeout = false;
enter();
try {
sink.flush();
throwOnTimeout = true;
} catch (IOException e) {
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
@Override public void close() throws IOException {
boolean throwOnTimeout = false;
enter();
try {
sink.close();
throwOnTimeout = true;
} catch (IOException e) {
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
@Override public Timeout timeout() {
return AsyncTimeout.this;
}
@Override public String toString() {
return "AsyncTimeout.sink(" + sink + ")";
}
};
}
同样使用了装饰者模式为所有的IO操作添加了异步超时 enter();让我们进入这个方法里面看一下
public final void enter() {
if (inQueue) throw new IllegalStateException("Unbalanced enter/exit");
long timeoutNanos = timeoutNanos();
boolean hasDeadline = hasDeadline();
if (timeoutNanos == 0 && !hasDeadline) {
return; // No timeout and no deadline? Don't bother with the queue.
}
inQueue = true;
scheduleTimeout(this, timeoutNanos, hasDeadline);
}
private static synchronized void scheduleTimeout(
AsyncTimeout node, long timeoutNanos, boolean hasDeadline) {
// Start the watchdog thread and create the head node when the first timeout is scheduled.
if (head == null) {
head = new AsyncTimeout();
new Watchdog().start();
}
long now = System.nanoTime();
if (timeoutNanos != 0 && hasDeadline) {
// Compute the earliest event; either timeout or deadline. Because nanoTime can wrap around,
// Math.min() is undefined for absolute values, but meaningful for relative ones.
node.timeoutAt = now + Math.min(timeoutNanos, node.deadlineNanoTime() - now);
} else if (timeoutNanos != 0) {
node.timeoutAt = now + timeoutNanos;
} else if (hasDeadline) {
node.timeoutAt = node.deadlineNanoTime();
} else {
throw new AssertionError();
}
// Insert the node in sorted order.
long remainingNanos = node.remainingNanos(now);
for (AsyncTimeout prev = head; true; prev = prev.next) {
if (prev.next == null || remainingNanos < prev.next.remainingNanos(now)) {
node.next = prev.next;
prev.next = node;
if (prev == head) {
AsyncTimeout.class.notify(); // Wake up the watchdog when inserting at the front.
}
break;
}
}
}
new Watchdog().start();
在内部启动了一个看门狗线程监听超时机制,AsyncTimeout这个类维护着一个任务超时队列,每标志一次他都会插入一个新的任务标志到超时链表中,剩余时间越少的排在越前面。
private static final class Watchdog extends Thread {
public Watchdog() {
super("Okio Watchdog");
setDaemon(true);
}
public void run() {
while (true) {
try {
AsyncTimeout timedOut;
synchronized (AsyncTimeout.class) {
timedOut = awaitTimeout();
// Didn't find a node to interrupt. Try again.
if (timedOut == null) continue;
// The queue is completely empty. Let this thread exit and let another watchdog thread
// get created on the next call to scheduleTimeout().
if (timedOut == head) {
head = null;
return;
}
}
// Close the timed out node.
timedOut.timedOut();
} catch (InterruptedException ignored) {
}
}
}
}
可以看到这个线程是个守护线程,不断循环查找快要超时的节点并调用节点的超时方法
awaitTimeout()这个方法是真正阻塞线程计算超时的方法
static AsyncTimeout awaitTimeout() throws InterruptedException {
// Get the next eligible node.
AsyncTimeout node = head.next;
// The queue is empty. Wait until either something is enqueued or the idle timeout elapses.
if (node == null) {
long startNanos = System.nanoTime();
AsyncTimeout.class.wait(IDLE_TIMEOUT_MILLIS);
return head.next == null && (System.nanoTime() - startNanos) >= IDLE_TIMEOUT_NANOS
? head // The idle timeout elapsed.
: null; // The situation has changed.
}
long waitNanos = node.remainingNanos(System.nanoTime());
// The head of the queue hasn't timed out yet. Await that.
if (waitNanos > 0) {
// Waiting is made complicated by the fact that we work in nanoseconds,
// but the API wants (millis, nanos) in two arguments.
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
AsyncTimeout.class.wait(waitMillis, (int) waitNanos);
return null;
}
// The head of the queue has timed out. Remove it.
head.next = node.next;
node.next = null;
return node;
}
这个方法计算节点的超时时间并阻塞线程,等到节点超时后移除节点。并通知前方节点超时,最终 timeout.sink 的exit()方法会根据节点是否存在 && IO是否操作完成来判断是否抛出异常。从这里我们可以学到一个,使用装饰者模式添加超时监听的方法。将原本的操作上封装一层,然后启动超时监听队列,去判断是否超时并更新界面。这种排序链式超时请求监听的方式,可以在编程中借鉴。
五.总结
整体可以看出,Okio的整体设计思想是以空间来换取时间,无论是在内存方面还是CPU使用的密集度上面都做了极致的优化,这些在我们以后编程过程中可以借鉴,比如它的链式内存管理池。在一个是设计上,使用装饰者加组合模式的应用,使整个代码逻辑看上去非常简洁和明了,而且扩展性很强,框架不仅仅只提供 RealBufferedSink 这样的接口,还提供了许多不同的任务接口,来提供不同的IO服务。第三就是超时机制的应用,对于大量对象的超时管理一般都是比较复杂的,它同样使用了排队链表进行管理,以回调的方式通知主体操作类。这样的技术同样能够为我们以后的编程提供帮助。