什么是XML解析?
所谓XML解析,就是读取以及操作XML文档中的数据。对于Java来说,主要有三种模式:DOM、SAX和StAX。
PS:由于三种解析模式的代码都比较固定且不难理解,我将直接结合实际例子进行介绍。一般来说只需套用格式即可,如有疑惑可以自行查阅API文档。
DOM解析
DOM的全称为Document Object Model,即文档对象模型。DOM是官方XML解析标准,Java、JavaScript等多种开发语言都支持DOM。
DOM解析的思想是:将整个XML文档加载内存中,形成文档对象,因此所有对XML文档中数据的操作都转化为对内存中的文档对象的操作。
这里强调一下,DOM、SAX和StAX都只是解析方式,也就是思想,具体的代码实现是JAXP——一套由Sun公司提供的XML解析API。主要有四个包:javax.xml.parsers(存放DOM和SAX相关解析类)、javax.xml.stream(存放StAX相关解析类 )、org.w3c.dom(存放DOM解析数据节点类)、org.xml.sax(存放SAX解析相关工具类)。
并且在企业实际开发中,为了简化XML文档的生成和解析,通常不使用约束。上面这两点是需要注意的。
这里还是用到之前介绍XML约束时的XML文档:
三体
刘慈欣
23.8
龙族
江南
19.6
DOM解析中,第一步是构建解器析工厂和解析器,再将XML文档加载到内存中(XML文档可以在Java工程中创建也可以复制粘贴到工程中),代码为:
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
这里介绍一下什么是Node节点。对于XML文档来说,所有数据都是Node节点,包括元素节点、属性节点、文本节点、注释节点、CDATA节点等:

此外,一个换行符也是一个节点,这点一定要记住。因此,XML文档被加载到内存中成为文档对象后,就可以获取所有Node节点的集合,从而 将对数据的操作转换为对节点的操作:
NodeList nodeList = document.getElementsByTagName("name");//调用getElementsByTagName()方法获取包含所有名为name的元素的节点集合
for(int i = 0;i < nodeList.getLength();i++){//遍历节点集合
Node node = nodeList.item(i);//进行类型转换
}
Node实际上一个接口,它包含许多子接口:

因此一般来说,对于具体的节点例如元素节点,应将Node型强制转为Element型,再调用相应的方法对数据进行操作:
@Test
public void demo1() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
NodeList nodeList = document.getElementsByTagName("name");
for(int i = 0;i < nodeList.getLength();i++){
Element elem = (Element) nodeList.item(i);
System.out.println(elem.getNodeName());//getNodeName()返回节点的名称
System.out.println(elem.getNodeType());//getNodeType()返回节点的类型
System.out.println(elem.getNodeValue());//getNodeValue()返回节点的值,元素节点的返回值为null
System.out.println(elem.getTextContent());//getTextContent()返回元素的文本内容
System.out.println("-------------");
}
}
用JUnit进行单体测试:

打开关于
Node的声明可以发现:

这段代码的意思是,节点类型是用short型数据表示的,而元素节点的类型为1。因此,demo1()的运行结果是正确的。
另外,getElementById()也是一种查找并获取指定元素的方法,但要求元素必须含有ID属性,也就是说只能用于解析带有约束的XML文档。
上面介绍的getElementsByTagName()只能做到全局查找,并不能精确到某一个元素或节点,如果查找一个具体的节点,就要通过相对节点位置进行
查找,主要有五种方法:getChildNodes()(以序列的形式返回该节点的的所有子节点)、getFirstChild()(返回该节点的第一个子节点)、getParentNode()(返回该节点的父节点)、getNextSibling()(返回该节点的下一个兄弟节点)、getPreviosSibling()(返回该节点的上一个兄弟节点)。
如果要查找三体这本书的价格,方法有很多种。可以先找到文本内容为三体的的name元素,然后找到父节点book,接着通过book的子节点序列找到price节点,price的文本内容即为三体的价格。
需要注意的是,book的子节点依次为name元素、换行符、author元素、换行符、price元素和换行符,而三体只是name元素的子节点、刘慈欣只是author元素的子节点、23.8只是price元素的子节点,它们并不是book元素的子节点,因此不能直接通过book的子节点序列找到具体价格:
@Test
public void demo2() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
NodeList nodeList = document.getElementsByTagName("name");
for(int i = 0;i < nodeList.getLength();i++){
Element elem = (Element) nodeList.item(i);
String bookName = elem.getTextContent();
if(bookName.equals("三体")){
Element elemParent = (Element) elem.getParentNode();
String bookPrice = elemParent.getChildNodes().item(5).getTextContent();//第5个子节点的下标为5
System.out.println(bookPrice);
}
}
}
用JUnit进行单体测试:
结果是正确的。
另外,也可以同样先找到文本内容为三体的的name元素,然后继续查找name节点的兄弟节点。修改一下代码:
if(bookName.equals("三体")){
String bookPrice = elem.getNextSibling().getNextSibling().getNextSibling().getNextSibling().getTextContent();//name节点往下数第4个兄弟节点为price节点
System.out.println(bookPrice);
}
用JUnit进行单体测试:
而如果要对XML文档中的数据进行增加、修改或者删除,由于要涉及到XML文档的回写,代码则会复杂一些:
@Test
public void demo3() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
TransformerFactory transformerFactory = TransformerFactory.newInstance();//构建转换器工厂
Transformer transformer = transformerFactory.newTransformer();//构建转换器
DOMSource domSource = new DOMSource(document);//用加载到内存中的文档对象构建文档源
StreamResult streamResult = new StreamResult(new File("books1.xml"));//用回写完成的XML文档构建结果流,这里新建一个XML文档
Element root = document.getDocumentElement();//找到原XML文档的根元素
Element newBook = document.createElement("book");//新建book元素
root.appendChild(newBook);//将book元素添加为根元素的子元素
Element newName = document.createElement("name");//新建name元素
newName.setTextContent("爵迹");//为name元素设置文本内容
Element newAuthor = document.createElement("author");//新建author元素
newAuthor.setTextContent("郭敬明");//为author元素设置文本内容
Element newPrice = document.createElement("price");//新建price元素
newPrice.setTextContent("30.2");//为price元素设置文本内容
newBook.appendChild(newName);//将name元素添加为book元素的子元素
newBook.appendChild(newAuthor);//将author元素添加为book元素的子元素
newBook.appendChild(newPrice);//将price元素添加为book元素的子元素
newBook.setAttribute("id", "03");//为book元素设置id属性
transformer.transform(domSource, streamResult);//用转换器进行回写
}
生成的books1.xml文档同样位于Java工程中,打开后将文档格式化表示:

表明增加元素的操作是正确的。
修改数据的操作比较简单,只要找到对应的元素节点对文本内容进行修改即可,这里就不再演示。
删除数据的操作比较特别,若想删除某个元素,只能通过父节点来删除子节点:
@Test
public void demo4() throws Exception{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document document = builder.parse("books.xml");
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource domSource = new DOMSource(document);
StreamResult streamResult = new StreamResult(new File("books1.xml"));
NodeList nodelist = document.getElementsByTagName("name");
for (int i = 0; i < nodelist.getLength(); i++) {
Element bookName = (Element) nodelist.item(i);
if (bookName.getTextContent().equals("龙族")) {//通过name元素找到《龙族》这本书
Element book = (Element) bookName.getParentNode();//找到name节点的父节点book
book.getParentNode().removeChild(book);//通过book的父节点删除book节点
}
}
transformer.transform(domSource, streamResult);
}
用JUnit进行单体测试,格式化books1.xml文档后查看:

表明删除元素的操作是正确的。
SAX解析
SAX的全称为Simple API for XML,这种解析方式来自XML社区。当XML文档非常大时,如果将所有数据都加载到内存中,这样会极大地占据内存空间,导致解析效率极低。因此,XML解析的程序员们设计了SAX解析模式。SAX解析的思想也很简单:一边解析 ,一边处理,一边释放内存资源,不允许在内存中保留大规模的XML数据,当然这样也使得XML文档的数据无法被修改(修改包括增加、修改和删除数据)。
用SAX模式解析XML,第一步同样是构建解析器工厂和解析器:
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = saxParserFactory.newSAXParser();
SAX和DOM两种解析模式另外一个区别就是,SAX是基于事件驱动进行解析,因此两者的解析原理也不一样:
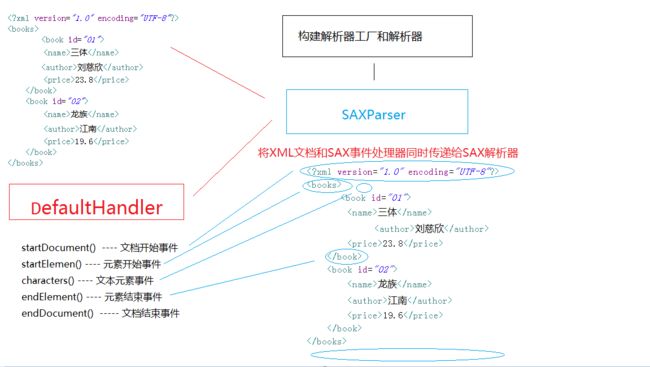
因此,解析XML文档时具体的代码为:
@Test
public void demo1() throws Exception{
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = saxParserFactory.newSAXParser();
DefaultHandler myHandler = new DefaultHandler();
saxParser.parse("books.xml", myHandler);//将XML文档和SAX事件处理器传递给解析器
}
用JUnit进行单体测试会发现控制台没有任何输出,实际上XML文档已经被解析成功了,怎么证明呢?这时需要对代码进行一些修改,不妨创建一个MyHandler类,让它继承DefaultHandler类,接着重写DefaultHandler类中的方法,当处理器处理一个元素开始事件时输出这个元素的名称以及包含的属性的值,当处理器处理一个元素结束事件时同样输出这个元素的名称等,那么就会一目了然了:
public class SAXtest{
@Test
public void demo1() throws Exception{
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = saxParserFactory.newSAXParser();
MyHandler myHandler = new MyHandler();
saxParser.parse("books.xml", myHandler);
}
}
class MyHandler extends DefaultHandler{//定义MyHandler类
public void startDocument(){
System.out.println("start document...");
}
public void startElement(String uri, String localName, String qName, Attributes attributes){
System.out.println("start element..." + qName);//输出元素的名称
if(attributes.getLength() != 0){//若元素包含属性则遍历属性序列
for(int i = 0;i < attributes.getLength();i++){
String attrName = attributes.getQName(i);//获取属性的名称
System.out.println("属性" + attrName + "的值为" + attributes.getValue(attrName));//输出属性的值
}
}
}
public void characters(char[] ch, int start, int length){
String content = new String(ch, start, length);//获取文本内容
System.out.println("character..." + content);//输出文本内容
}
public void endElement(String uri, String localName, String qName){
System.out.println("end element..." + qName);//输出元素的名称
}
public void endDocument(){
System.out.println("end document...");
}
}


这里的换行符也是一个文本元素。
SAX解析由于功能单一,因此很少使用这种模式解析XML文档。