绘制基础
安卓绘制框架
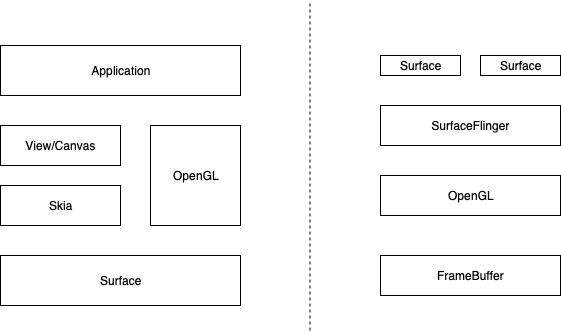
应用层
1.通过与WindowManagerService通信,获取一块surface。
2.通过View系统或OpenGL、Skia在这块surface上绘制。
3.与WindowManagerService通信,提交绘制产生的缓存。
服务层(WindowManagerService)
1.生成、释放surface
2.管理surface的层级
3.获取surface的数据,将surface的数据进行混合,生成新的一帧。
4.将新的一帧数据写入内核,使得显示器刷新数据
关键类:
1.Canvas:画布,里面有一个Bitmap,用于保存绘制过程中的缓存。此类提供了绘制的基本方法,包括作圆、线等。
2.Paint:画笔,提供绘制的基本参数,比如说颜色,画笔的粗细等。
3.Surface:可以获取画布并提交绘制结果。本质上是一个代理类。用于Application与WindowManager通信。
4.ViewRootImp:实现ViewParent,包含Surface和Choreographer。用于控制Activity的绘制。
- Choreographer绘制调度器。用于控制各个Surface的刷新步调,让所以Surface基本上同时开始刷新。一般16ms触发一次刷新。
- SurfaceFlinger:混合各个Surface的数据,形成新的一帧数据。
View的重绘流程
以最基本的View的invalidate为例
基本绘制流程

流程图中有小小错误,能找到吗?
基本流程可以分成两块:
一、触发刷新
子view调用invalidate,然后层层递进,调到ViewrootImp的ScheduleTraversals,在这个过程中不断确定重绘的区域,更新各个父控件的绘制标志。完成各个层级父控制的绘制标志的刷新之后,利用ViewrootImp中的Choreographer控制刷新的时机,触发刷新。
二、刷新过程
-
首先通过Surface的lockCanvas申请一块新的画布,获取一个Canvas。
值得注意的是,WindowManagerService会为每一块surface分配两块内存,
一块作为显示使用(读),一块作为绘制使用(写)。在完成绘制后,两块内存的作用互换。lockCanvas的作用,实际上时是给待绘制的内存上锁,并且获取待绘制内存的地址,把这块内存作为画布的缓存。在lockCanvas时,会将显示的内存的数据拷贝到待绘制的内存中,同时传入一个区域(dirty),作为重绘的区域。每次重绘实际只需要绘制需要修改的区域(dirty区域),其它区域保持不变,这样,就大大加快了绘制效率
 绘制内存切换.png
绘制内存切换.png -
获取画布之后,就需要层层调用View的draw方法,在这块画布上在做画。
每一个View都有一块缓存mDrawCache。View的绘制过程,首先要通过绘制标志,判断View的内容是否发生变化,有发生变化,则调用ondraw方法,重新获取mDrawCache。最后将mDrawCache的重绘区域绘制到画布中。
ViewGroup包含自己本身的绘制和子View的绘制。自己本身的绘制和View一样,子View的绘制需要层层调用子View的绘制方法。
 draw过程.png
draw过程.png 完成绘制后,调用unlockCanvasAndPost接口。将绘制内容提交给WindowManagerService。
接口unlockCanvasAndPost的实质是将绘制的内存解锁,并且通知WindowManagerService将两块内存的作用互换,这样,SurfaceFlinger就会将最新绘制后得到的内存进行混合显示。
硬件加速
为什么使用硬件加速
CPU和GPU架构
CPU : Central Processing Unit , 中央处理器,是计算机设备核心器件,用于执行程序代码。
GPU : Graphic Processing Unit , 图形处理器,主要用于处理图形运算,通常所说“显卡”的核心部件就是GPU。
下面是CPU和GPU的结构对比图。其中:
黄色的Control为控制器,用于协调控制整个CPU的运行,包括取出指令、控制其他模块的运行等;
-
绿色的ALU(Arithmetic Logic Unit)是算术逻辑单元,用于进行数学、逻辑运算;
橙色的Cache和DRAM分别为缓存和RAM,用于存储信息。
 cpu和gpu架构图.png
cpu和gpu架构图.png 从结构图可以看出,CPU的控制器较为复杂,而ALU数量较少。因此CPU擅长各种复杂的逻辑运算,但不擅长数学尤其是浮点运算。
- 和CPU不同的是,GPU就是为实现大量数学运算设计的。从结构图中可以看到,GPU的控制器比较简单,但包含了大量ALU。GPU中的ALU使用了并行设计,且具有较多浮点运算单元。
硬件加速的主要原理,就是通过底层软件代码,将CPU不擅长的图形计算转换成GPU专用指令,由GPU完成。
硬件加速的开启
Android 系统的 UI 从 绘制 到 显示在屏幕上 是分两个步骤的
第一步:在Android 应用程序这一侧进行的。(将 UI 构建到一个图形缓冲区 Buffer 中,交给SurfaceFlinger )
第二步:在SurfaceFlinger进程这一侧进行的。(获取Buffer 并合成以及显示到屏幕中。)
其中,第二步在 SurfaceFlinger 的操作一直是以硬件加速方式完成的,所以我们说的硬件加速一般指的是在 应用程序 图形通过GPU加速渲染 到 Buffer 的过程。
在Android中,可以四给不同层次上开启硬件加速:
- 应用:
- Activity
- Window
getWindow().setFlags(WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED, WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED); - View
view.setLayerType(View.LAYER_TYPE_SOFTWARE, null);
在这四个层次中,应用和Activity是可以选择的,Window只能打开,View只能关闭。
硬件加速的流程分析
模式模型
构建阶段
所谓构建就是递归遍历所有视图,将需要的操作缓存下来,之后再交给单独的Render线程利用OpenGL渲染。在Android硬件加速框架中,View视图被抽象成RenderNode节点。

View中的绘制都会被抽象成一个个DrawOp(DisplayListOp),比如View中drawLine,构建中就会被抽象成一个DrawLintOp,drawBitmap操作会被抽象成DrawBitmapOp,每个子View的绘制被抽象成DrawRenderNodeOp,每个DrawOp有对应的OpenGL绘制命令,同时内部也握着绘图所需要的数据。

如此以来,每个View不仅仅握有自己DrawOp List,同时还拿着子View的绘制入口,如此递归,便能够统计到所有的绘制Op,很多分析都称为Display List,源码中也是这么来命名类的,不过这里其实更像是一个树,而不仅仅是List,示意如下:

构建完成后,就可以将这个绘图Op树交给Render线程进行绘制,这里是同软件绘制很不同的地方,软件绘制时,View一般都在主线程中完成绘制,而硬件加速,除非特殊要求,一般都是在单独线程中完成绘制,如此以来就分担了主线程很多压力,提高了UI线程的响应速度。
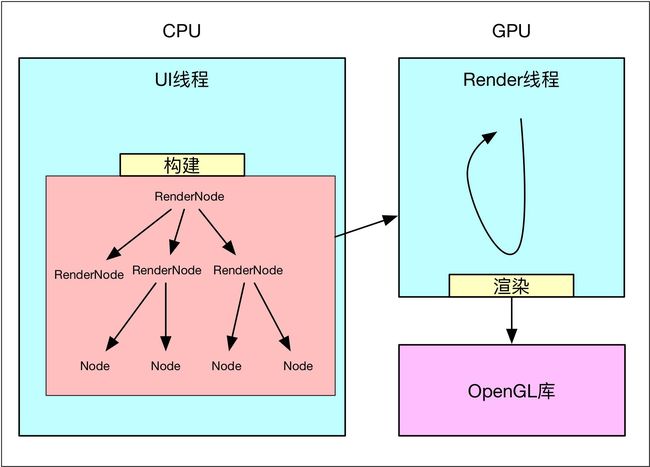
构建过程源码分析
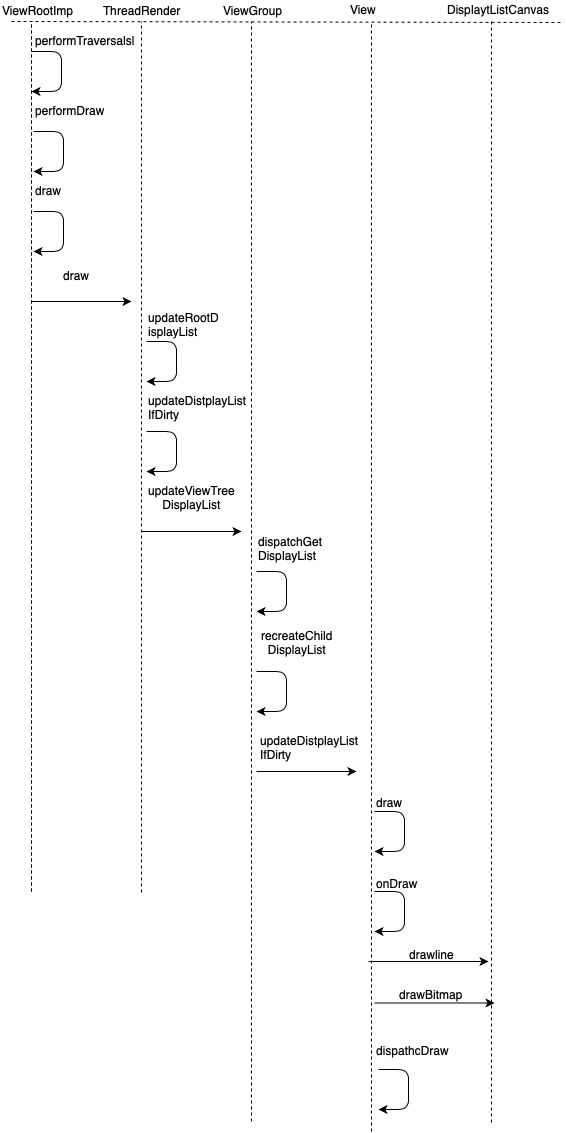
从流程图可以看出,HardwareRenderer是整个硬件加速绘制的入口。整个绘制的过程通过不断dispatchGetDisplayList或者dispathDraw遍历View,刷新displayList。
从名字能看出,ThreadedRenderer应该跟一个Render线程息息相关,不过ThreadedRenderer是在UI线程中创建的,那么与UI线程也必定相关,其主要作用:
1、在UI线程中完成DrawOp集构建
2、负责跟渲染线程通信
可见ThreadRenderer的作用是很重要的,简单看一下实现:
ThreadedRenderer(Context context, boolean translucent) {
...
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
ProcessInitializer.sInstance.init(context, mNativeProxy);
loadSystemProperties();
}
- RootNode用来标识整个DrawOp树的根节点,有个这个根节点就可以访问所有的绘制Op.
- RenderProxy对象,这个对象就是用来跟渲染线程进行通信的句柄
再看一下RenderProxy的源码
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())
, mContext(nullptr) {
SETUP_TASK(createContext);
args->translucent = translucent;
args->rootRenderNode = rootRenderNode;
args->thread = &mRenderThread;
args->contextFactory = contextFactory;
mContext = (CanvasContext*) postAndWait(task);
mDrawFrameTask.setContext(&mRenderThread, mContext);
}
- RenderThread是一个单例线程,也就是说,每个进程最多只有一个硬件渲染线程,这样就不会存在多线程并发访问冲突问题,到这里其实环境硬件渲染环境已经搭建好好了。
ThreadRender的绘制入口
@Override
void draw(View view, AttachInfo attachInfo, HardwareDrawCallbacks callbacks) {
attachInfo.mIgnoreDirtyState = true;
final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer;
choreographer.mFrameInfo.markDrawStart();
updateRootDisplayList(view, callbacks);
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);
...
}
- updateRootDisplayList,构建RootDisplayList,其实就是构建View的DrawOp树,updateRootDisplayList会进而调用根View的updateDisplayListIfDirty,让其递归子View的updateDisplayListIfDirty,从而完成DrawOp树的创建
- 通知RenderThread线程绘制
构建树的流程
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
updateViewTreeDisplayList(view);
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
final int saveCount = canvas.save();
canvas.translate(mInsetLeft, mInsetTop);
callbacks.onHardwarePreDraw(canvas);
canvas.insertReorderBarrier();
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
callbacks.onHardwarePostDraw(canvas);
canvas.restoreToCount(saveCount);
mRootNodeNeedsUpdate = false;
} finally {
mRootNode.end(canvas);
}
}
}
- 利用View的RenderNode获取一个DisplayListCanvas
- 利用DisplayListCanvas构建并缓存所有的DrawOp
- 将DisplayListCanvas缓存的DrawOp填充到RenderNode
- 将根View的缓存DrawOp设置到RootRenderNode中,完成构建
DisplayList的更新过程
// Don't need to recreate the display list, just need to tell our
// children to restore/recreate theirs
if (renderNode.isValid()
&& !mRecreateDisplayList) {
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
dispatchGetDisplayList();
return renderNode; // no work needed
}
// If we got here, we're recreating it. Mark it as such to ensure that
// we copy in child display lists into ours in drawChild()
mRecreateDisplayList = true;
int width = mRight - mLeft;
int height = mBottom - mTop;
int layerType = getLayerType();
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
computeScroll();
canvas.translate(-mScrollX, -mScrollY);
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
// Fast path for layouts with no backgrounds
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
dispatchDraw(canvas);
drawAutofilledHighlight(canvas);
if (mOverlay != null && !mOverlay.isEmpty()) {
mOverlay.getOverlayView().draw(canvas);
}
if (debugDraw()) {
debugDrawFocus(canvas);
}
} else {
draw(canvas);
}
}
} finally {
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
- 如果本View不需要更新RendorNode,则调用dispathcGetDisplayList,让其子view更新RendorNode。最终会导致步骤2。
- 如果本View需要更新RendorNode,则调用draw(Canvas)方法。
继续跟踪draw(Canvas)方法
if (!dirtyOpaque) {
drawBackground(canvas);
}
// skip step 2 & 5 if possible (common case)
final int viewFlags = mViewFlags;
boolean horizontalEdges = (viewFlags & FADING_EDGE_HORIZONTAL) != 0;
boolean verticalEdges = (viewFlags & FADING_EDGE_VERTICAL) != 0;
if (!verticalEdges && !horizontalEdges) {
// Step 3, draw the content
if (!dirtyOpaque) onDraw(canvas);
// Step 4, draw the children
dispatchDraw(canvas);
drawAutofilledHighlight(canvas);
// Overlay is part of the content and draws beneath Foreground
if (mOverlay != null && !mOverlay.isEmpty()) {
mOverlay.getOverlayView().dispatchDraw(canvas);
}
// Step 6, draw decorations (foreground, scrollbars)
onDrawForeground(canvas);
// Step 7, draw the default focus highlight
drawDefaultFocusHighlight(canvas);
我们知道每个view的DrawRenderNodeOp缓存主要包括displayListOps和其子View的DrawRenderNodeOp
- drawBackground、onDraw 、onDrawForeground、drawDefaultFocusHighlight是更新自身相关的displayListOps
-
dispatchDraw向下触发便利,更新子View相关的DrawRenderNodeOp。
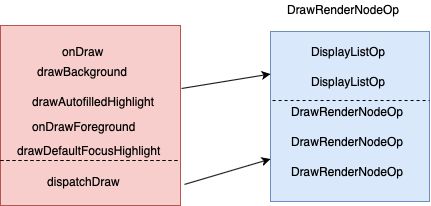 drawOps更新.png
drawOps更新.png
dispatchDraw最终会走到draw(Canvas canvas, ViewGroup parent, long drawingTime) ,看一下里面的代码
....
if (drawingWithRenderNode) {
// Delay getting the display list until animation-driven alpha values are
// set up and possibly passed on to the view
renderNode = updateDisplayListIfDirty();
if (!renderNode.isValid()) {
// Uncommon, but possible. If a view is removed from the hierarchy during the call
// to getDisplayList(), the display list will be marked invalid and we should not
// try to use it again.
renderNode = null;
drawingWithRenderNode = false;
}
}
if (!drawingWithDrawingCache) {
if (drawingWithRenderNode) {
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
((DisplayListCanvas) canvas).drawRenderNode(renderNode);
} else {
// Fast path for layouts with no backgrounds
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
dispatchDraw(canvas);
} else {
draw(canvas);
}
}
}
....
- 子view通过updateDisplayListIfDirty刷新自己的RendNode。如果子View本身,以及子View的子控件没有变化,RenderNode不会发生实质的变化。
- 最后通过DisplayListCanvas的drawRenderNode将绘制缓存保存到父View 中
DisplayListCanvas类分析,以drawLine为例
void DisplayListCanvas::drawLines(const float* points, int count, const SkPaint& paint) {
points = refBuffer(points, count);
addDrawOp(new (alloc()) DrawLinesOp(points, count, refPaint(&paint)));
}
RenderThread渲染过程
DrawOp树构建完毕后,UI线程利用RenderProxy向RenderThread线程发送一个DrawFrameTask任务请求,RenderThread被唤醒,开始渲染。
- 首先进行DrawOp的合并
- 接着绘制特殊的Layer
- 最后绘制其余所有的DrawOpList
- 调用swapBuffers将前面已经绘制好的图形缓冲区提交给Surface Flinger合成和显示。
开启硬件加速的优缺点
优点
- 硬件加速使用双线程工作,主线程只负责构建绘制树,渲染线程负责渲染。主线程基本上不会因为绘制超时而卡顿。
- GPU分担了CPU的渲染任务,CPU有多余的时间做其他重要的事情,这将使得手机整体表现将更加流畅。
- GPU擅长做渲染工作,硬件加速允许应用执行繁重的渲染任务。如果没有GPU或者不采用硬件加速,播放视频将非常卡顿
缺点 - 硬件加速属于双缓冲机制,使用显存进行页面渲染(使用较少的物理内存),导致更频繁的显存操作,可能引起以下现象:
花屏、闪屏 - 硬件加速的准备工作较长,可能在应用刚启动时,存在掉帧现象。