1.数据类型
StringField
不做分词,用来精准匹配和排序
TextField
做分词,对存储非结构的问题做索引很有用
Numberic Field
IntField,FloatField,LongField,DoubleField
lucene把数字当做一个内部term,然后索引成一个字典树(trie)的结构。
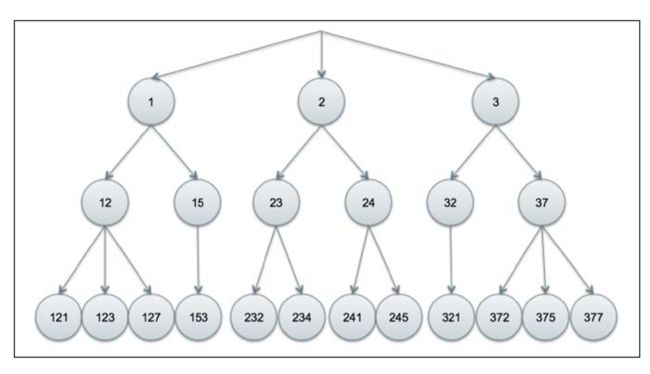
顶部的1表示1XX,第二层的12表示12X,因此如果一个人要检索230-239的结果,直接返回23下的所有节点
可以通过precisionStep来调节分割的长度(如1234,按照十进制1的长度来分,分为1,12,123,1234,4层,层数多,消耗空间,但是检索快;按照2的长度来分应该是,12,1234,两层),更小的precisionStep会产生更多的层,会消耗更多的磁盘空间,但是会提升范围查询性能。这个值只能通过创建自义定FieldType来修改,lucene考虑了磁盘和性能二者因素,默认为4
数字可以被排序、范围查询和精准查询。值得注意的是,如果你想对一个数字字段排序,那么应该使用单值(single-valued)字段(precisionStep设为Integer.MAX_VALUE),这比使用同类项要快很多
DocValue
docvalue是某个字段与docid的映射,如果需要对该字段进行扫描,那么适合使用docvalue,这样不会把无关的字段加载到内存中,从而提高速度
需要更多的资料
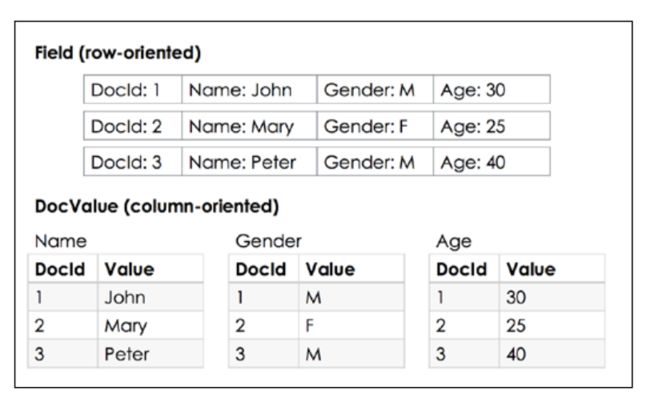
docvalue的类型
1.BinaryDocValues byte[]
2.NumbericDocValues single-valued numeric type value
3.SortedDocValues
4.SortedNumbericDocValues
5.SortedSetDocValues
事务提交和索引版本
ACID
Atomicity:all or nothing
Consistency:变更必须是有效的且符合约定,lucene无效的数据会不可见
Isolation:事务之间相互隔离
Durability:持久化
lucene使用两段式提交,prepareCommit方法提前做好准备工作(变更flush到磁盘),然后调用commit提交变更或者调用rollback回滚事务
lucene可能有多次index commit,每个commit都可以看做是某个时间点的快照,默认的,lucene会使用IndexDeletionPolicy在一次成功的提交后删除之前的commit。一共有这么几种policy:
KeepOnlyLastCommitDeletionPolicy:默认策略,在一次成功的提交后,删除之前的提交,保证index的文件夹紧密,只有一次rollback机会,rollback最新的提交
NoDeletionPolicy:保留所有的提交,直到调用delete方法。这个策略在需要多个回滚点以及要做基于之前某个提交检索时很有用。一个可能的场景是当数据源和index不同步,需要用一个回滚来校正数据的时候
SnapshotDeletionPolicy:快照删除策略。在一个commit之后立即生成一个快照。做了快照的commit在快照发布后才能删除。快照保存在内存中,使用场景:给index做热备份,后台进程可以把index的数据文件(快照?)拷到备份的地方。
PersistentSnapshotDeletionPolicy:把快照持久化到index相同的目录下,使用场景:在经历系统故障的时候,快照依然存在,热备份数据可以立马获取
IndexCommit和Snapshot的区别是什么?
commit可以回滚,快照用来备份
线程重用字段和doc对象
lucene性能一个好的实践是重用字段和doc对象,这个减少了在导入大量数据是创建新对象的成本,也减少了触发gc的机会
当重用doc对象时,我们必须要牢记,我们在设新值的时候,必须确保已经清楚了所有的字段的值。对于重用字段, 我们只需要重写它就可以了
示例如下:
Analyzer analyzer = new StandardAnalyzer();
Directory directory = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); IndexWriter indexWriter = new IndexWriter(directory, config);
Document doc = new Document();
StringField stringField = new StringField("name", "", Field.Store.YES);
String[] names = {"John", "Mary", "Peter"};
for (String name : names) {
stringField.setStringValue(name);
doc.removeField("name");
doc.add(stringField);
indexWriter.addDocument(doc);
}
indexWriter.commit();
IndexReader reader = DirectoryReader.open(directory);
for (int i = 0; i < 3; i++) {
doc = reader.document(i);
System.out.println("DocId: " + i + ", name: " + doc.getField("name").stringValue());
}
结果如下:
DocId: 0, name: John
DocId: 1, name: Mary
DocId: 2, name: Peter
探讨字段加权基准(field norms)
norm(加权基准)是计算词相关性分数的一部分。当我们检索的时候,对匹配的每个结果进行分数计算,基于分数对检索结果进行排序,这个分数就是我们说的相关性分数
每个被建索引的域(Field)都计算norm。这是索引时计算(基于TF-IDF 相关性)和lengthNorm(计算因子,更短的域或者doc会有更高的分数)的一个产物。更高的分数意味着更好的相关性和更高的排序位置。
lucene允许2种类型的加权调整,索引时设置加权(setBoost)和查询时设置加权(setBoost)。索引时对每个indexed field进行加权设置,他可以通过文档的某些域的加权提升某个文档的分数。查询时对每个查询子句进行加权设置,这样所有跟查询子句匹配的文档会跟它相乘。
在某一个filter比所有事情都优先的场景下,他很有用(??)
加权高度压缩(有损)后存储,单字节格式,这是为了节约存储和内存消耗。所以没有那么精准,但是对于差别很大的2个文档,相关性的差别是很明显的
对于某些特定域,如单值域,norm并不能带来好处,可以通过自定义fieldtype来省略norm。不过除非内存是个问题,通常都可以不用管它
//以下内容补充自lucene 2 in action
索引期间,文档中域的所有加权都被合并成一个单一的浮点数。除了域,文档也有自己的加权值,lucene会基于域的语汇单元数量自动计算出这些加权值,这些加权被合并到一处,编码成一个字节,作为域或者文档的一部分存储起来。搜索期间,被搜索的域的加权被加载到内存中并被还原成一个浮点数,用于相关性计算。通过setNorm(lucene 4中的setBoost?)可以改加权值。
norm经常遇到的一个问题是高内存使用,可以通过Filed.Index的NO_NORMS设置和Field.setOmitNorms(true)设置。
另外如果索引建到一半,设置略过norm,不会生效,需要重新build
//补充结束
Analyzer analyzer = new StandardAnalyzer(); Directory directory = new RAMDirectory(); IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); Document doc = new Document(); TextField textField = new TextField("name", "", Field.Store.YES); float boost = 1f; String[] names = {"John R Smith", "Mary Smith", "Peter Smith"}; for (String name : names) { boost *= 1.1; textField.setStringValue(name); textField.setBoost(boost); doc.removeField("name"); doc.add(textField); indexWriter.addDocument(doc); } indexWriter.commit(); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); Query query = new TermQuery(new Term("name", "smith")); TopDocs topDocs = indexSearcher.search(query, 100); System.out.println("Searching 'smith'"); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { doc = indexReader.document(scoreDoc.doc); System.out.println(doc.getField("name").stringValue()); }
结果
Searching 'smith'
Peter Smith
Mary Smith
John R Smith
但如果取消设置boost,顺序会变为 Mary, Peter和John,因为都匹配simith,那么短的分数更高