跟踪源码
spark-shell -> spark-submit -> spark-class
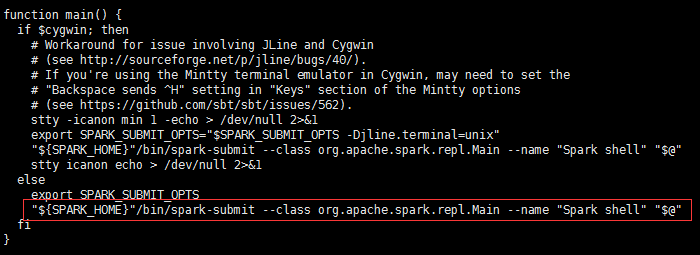

SparkSubmit -> repl.Main -> ILoop ( SparkILoop ).process -> loadFiles ( initializeSpark ( createSparkSession ) ) -> printWelcome
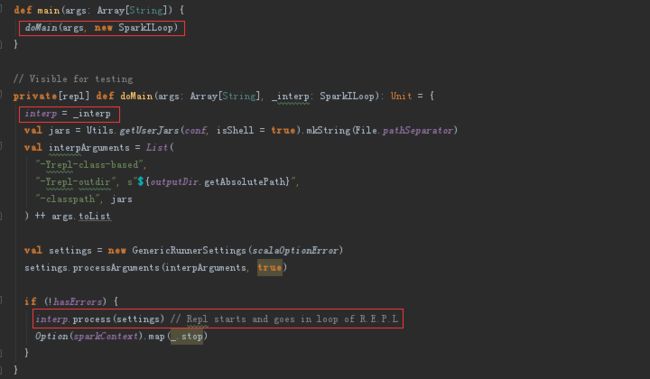


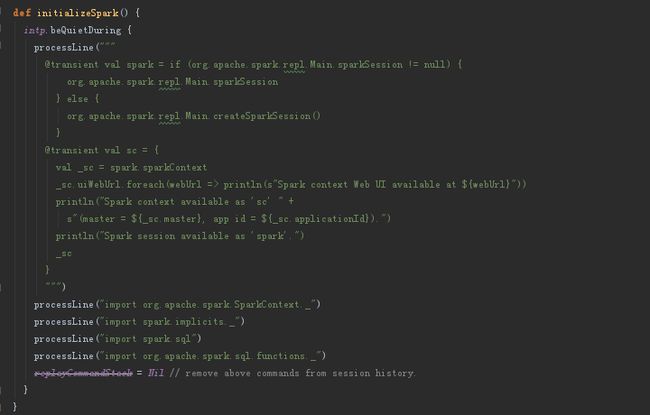
Spark设计理念与基本架构
Hadoop MRv1

组成部分
1.运行环境:JobTracker 和 TaskTracker
2.编程模型:MapReduce
3.数据处理引擎:Map Task 和 Reduce Task
缺点
1.JobTracker 既负责 资源管理 又负责 任务调度,容易成为瓶颈。
2.单 Master,容易down。
3.TaskTracker 采用 slot 等量划分本节点上的资源量( CPU、内存 )。slot 分为 Map slot 和 Reduce slot , MapTask 只能用 Map slot,ReduceTask 只能用 Reduce slot。有时会 MapTask 较多时,而 Reduce Task 还没有被调度,这时 Reduce slot 会被闲置。
Hadoop MRv2

改进
1.JobTracker被拆分成了通用的资源调度平台(ResourceManager RM)和负责各个计算框架的任务调度模块(ApplicationMaster AM)。
2.MRv2 中核心不再是 MapReduce,而是Yarn,MapReduce 框架时可插拔的,可以用 Spark、Storm 替代。
缺点
对HDFS的频繁操作(包括计算结果持久化、数据备份以及 shuffle )导致磁盘 I/O 成为系统性能的瓶颈。只适合离线的数据处理,不具备实时处理的能力。
Spark
基本概念
RDD:弹性分布式数据集
Task:具体执行的任务。分为 ShuffleMapTask 和 ResultTask两种,两者分别对应与 Hadoop 中的 Map 和 Reduce。
Job:用户提交的作业。
Stage:Job分成的阶段。根据依赖划分 Stage 。
Partition:数据分区。一个RDD数据可以被划分成多个 Partition。
NarrowDependency:窄依赖,即子 RDD 依赖于 RDD 中固定的 Partition。分为OneToOneDependency 和 RangeDependency 两种。
ShuffleDependency:shuffle依赖,宽依赖。子 RDD 对父 RDD 中的所有 Partition 都有依赖。
DAG:有向无环图。反映各 RDD 之间的依赖关系。
核心功能
SparkContext
Driver Application 的执行与输出都是通过 SparkContext 来完成的。
①内置的 DAGScheduler 负责创建 Job,将 DAG 中的 RDD 划分到不同的 Stage,提交 Stage 等功能。
②内置的 TaskScheduler 负责资源的申请、任务的提交以及请求集群对任务的调度等工作。
存储体系
优先考虑使用各个节点的内存作为存储。Spark 还提供了以内存为中心的高容错的分布式文件系统 Tachyon 供用户进行选择。Tachyon 能够为 Spark 提供可靠的内存级的文件共享服务。
计算引擎
由 SparkContext 中的 DAGScheduler、RDD以及具体节点上的 Executor 负责执行的 Map 和 Reduce 任务组成。DAGScheduler 和 RDD 虽然位于 SparkContext 内部,但是在任务正式提交与执行之前会将 Job 中的 RDD 组成DAG,决定了执行阶段任务的数量、迭代计算、shuffle 等过程。
部署模式
SparkContext 的 TaskScheduler 组件中提供了对 Standalone 部署模式的实现和 Yarn、Mesos 等分布式资源管理系统的支持。除此之外,还提供了 Local 模式便于开发和调试。
编程模型
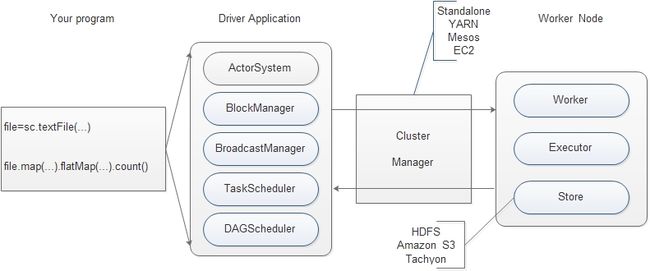
1.使用 SparkContext 提供的API 编写 Driver application程序。
2.使用 SparkContext 提交用户编写的 Driver application程序。具体:
①使用 BlockManager 和 BroadcastManager 将任务的 Hadoop 配置进行广播。
② DAGSchduler 将任务转换为 RDD 并组织成 DAG,DAG还将被划分为不同的Stage。
③ TaskSchduler 通过
ActorSystem
将任务提交给集群管理器(Cluster Manager)。
3.集群管理器(Cluster Manager)给任务分配资源,即将具体任务分配到 Worker上,Worker 创建 Executor 来处理任务的运行。Standalone、YARN、Mesos、EC2 等都可以作为 Spark 的集群管理器。
RDD计算模型
每个分区的数据只会在一个Task中计算。
基本架构
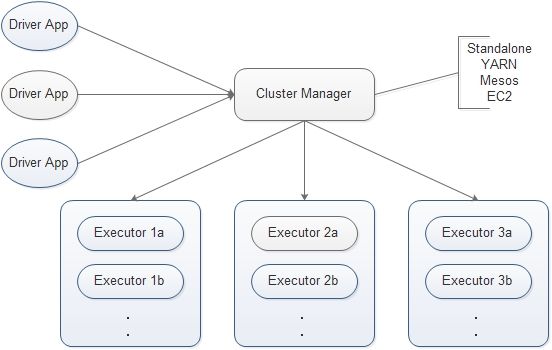
1.Cluster Manager
Spark 的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个 Worker 上的内存、CPU 等资源分配给应用程序(Driver application),但是并不负责对 Executor 的资源分配。Standalone、YARN、Mesos、EC2 等都可以作为 Spark 的集群管理器。
2.Worker
Spark的工作节点。其获得由集群资源(Cluster Manager)分配的资源,负责创建 Executor,将资源和任务进一步分配给 Executor,同步资源信息给 Cluster Manager。
3.Executor
执行计算任务的单元(
线程 or 进程?
),主要负责任务的执行以及与 Worker、Driver App的信息同步。
4.Driver App
客户端应用程序。用于将任务程序转换为 RDD 和 DAG,并与 Cluster Manager 进行通信与调度。