MapReduce概述
源自于Google的MapReduce论文,论文发表于2004年12月。
Hadoop MapReduce是Google MapReduce的克隆版。
MapReduce优点:海量数据离线处理&易开发&易运行。
MapReduce缺点:实时流式计算。
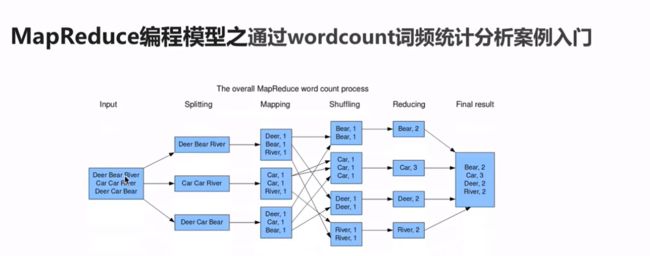
wordcount:统计文件中每个单词出现的次数
需求:求wordcount
1)文件内容大小:shell
2)文件内容很大:比如TB、GB,那么如何解决大数据量的统计分析呐?
工作中很多场景的开发都是wc的基础上进行改造的。
以上需求,都需要借用分布式计算框架来解决了:MapReduce
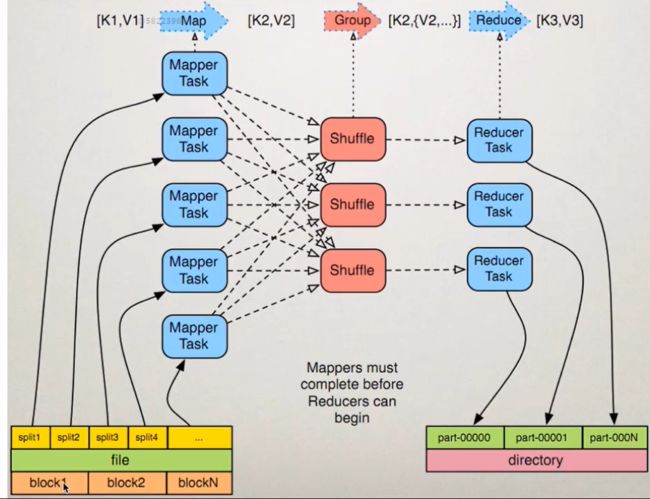
MapReduce编程模型
1、准备map处理的输入数据
2、Mapper处理
3、 Shuffle
4、 Reduce处理
5、 结果输出
MapReduce架构

Split
InputFormat
OutputFormat
Combiner
Partitioner

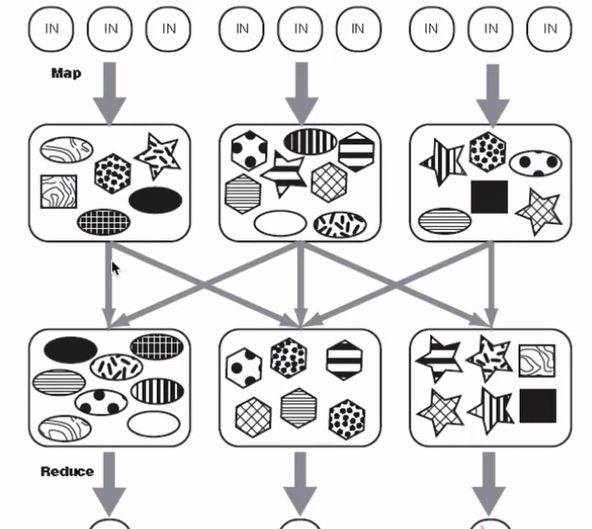
MapReduce编程
使用java 来开发wordcount案例
使用IDEA+MAVEN开发wordcount案例:
1)开发
2)编译
3)jar包上传到服务器
4)运行
hadoop jar /home/hadoop/lib/你开发的jar名字.jar 主程序class名称 参数1 参数2
例如: hadoop jar /usr/hadoop/hadoop-2.6.0-cdh5.7.0/lib/bigdata-1.1.1.jar com.sc.mapreduce.WordCountApp hdfs://10.6.24.143:8020/xxx/test.txt hdfs://10.6.24.143:8020/xxx/output/wc
常见错误
相同的代码和脚本,再次执行会包错:
WARN security.UserGroupInformation: PriviledgedActionException as:root (auth:SIMPLE) cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://10.6.24.143:8020/xxx/output/wc already exists
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://10.6.24.143:8020/xxx/output/wc already exists
原因:在MapReduce中,输出文件是不能事先存在的,要想避免这个问题,有两种方式:
第一种方式:就需要我们手工通过
shell的方式将输出文件删除。
hadoop fs -rm -r /xxx/output/wc
第二种方式:通过java api的方式(推荐)
//删除存在的输出目录
Path outputPath=new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);//递归删除
}
MapReduce编程之Combiner

虽然combiner有优点,但并非所有场景都适合:
求和,计数场景:适合
求平均数场景:不适合
MapReduce编程之Partitioner
1)Partitioner决定MapTask输出的数据交由哪个ReduceTask处理。
2)默认实现:分发的key的hash值对Reduce Task个数取模
案例如下:
我们执行程序看到有几个reduce就会生成几个输出文件

JobHistory
作用:
记录已经运行完的MapReduce信息到指定的HDFS目录下。
默认是不开启的。
如何启动呐?
第一步完成
yarn-site.xml的配置
mapred-site.xml的配置
<--执行完毕作业的日志存放目录-->
<--执行中的作业日志存放目录-->
第二步重启yarn服务
./stop-yarn.sh
./start-yarn.sh
第三步启动jobHistory服务
./mr-jobhistory-daemon.sh start historyserver
如果向停止jobHistory服务命令
./mr-jobhistory-daemon.sh stop historyserver