背景
背景是这样的:前2天在网上搜技术类电子书,结果发现CSDN某博客更新了大量技术类PDF电子书(链接在这里程序员成长思路-电子书),考虑到他这个应该是为网盘导流,文件有可能是临时存储的,所以保险起见得下到自己本地来,常规下载如下图,感觉操作和跳转步骤太多,懒筋作祟,于是想怎么不写个爬虫把它全搞下来!
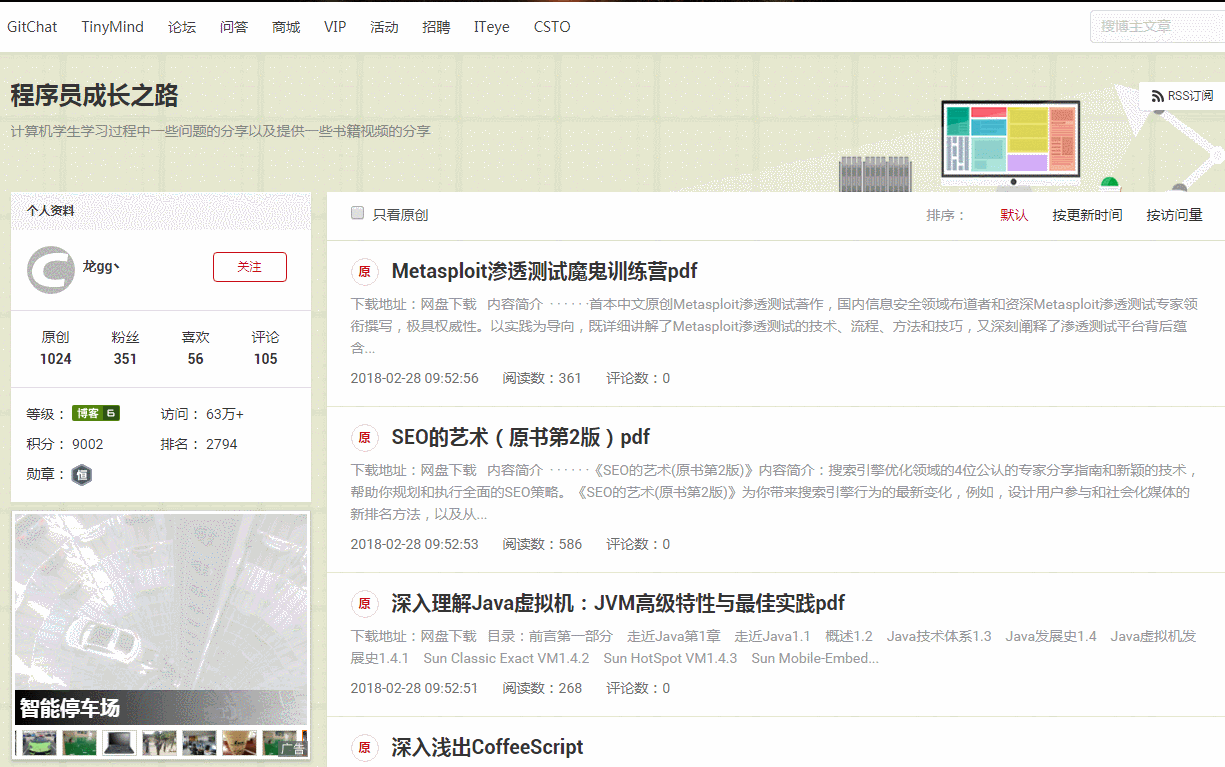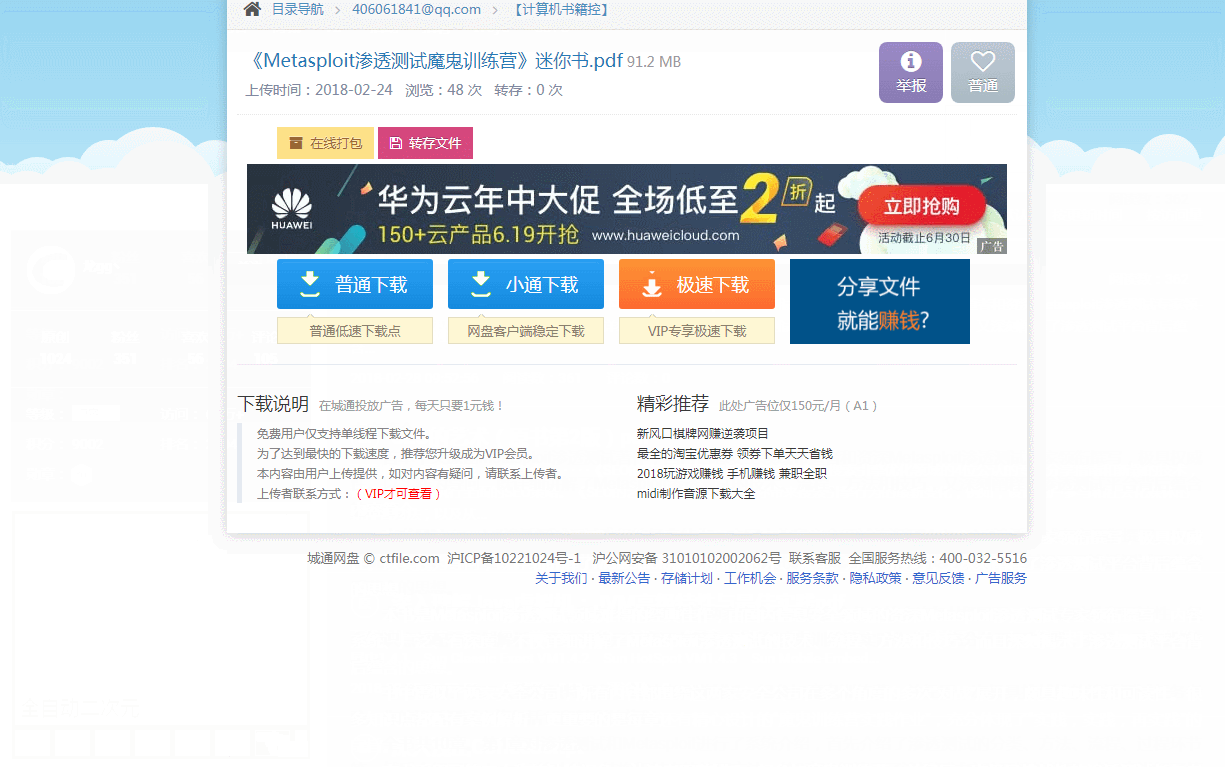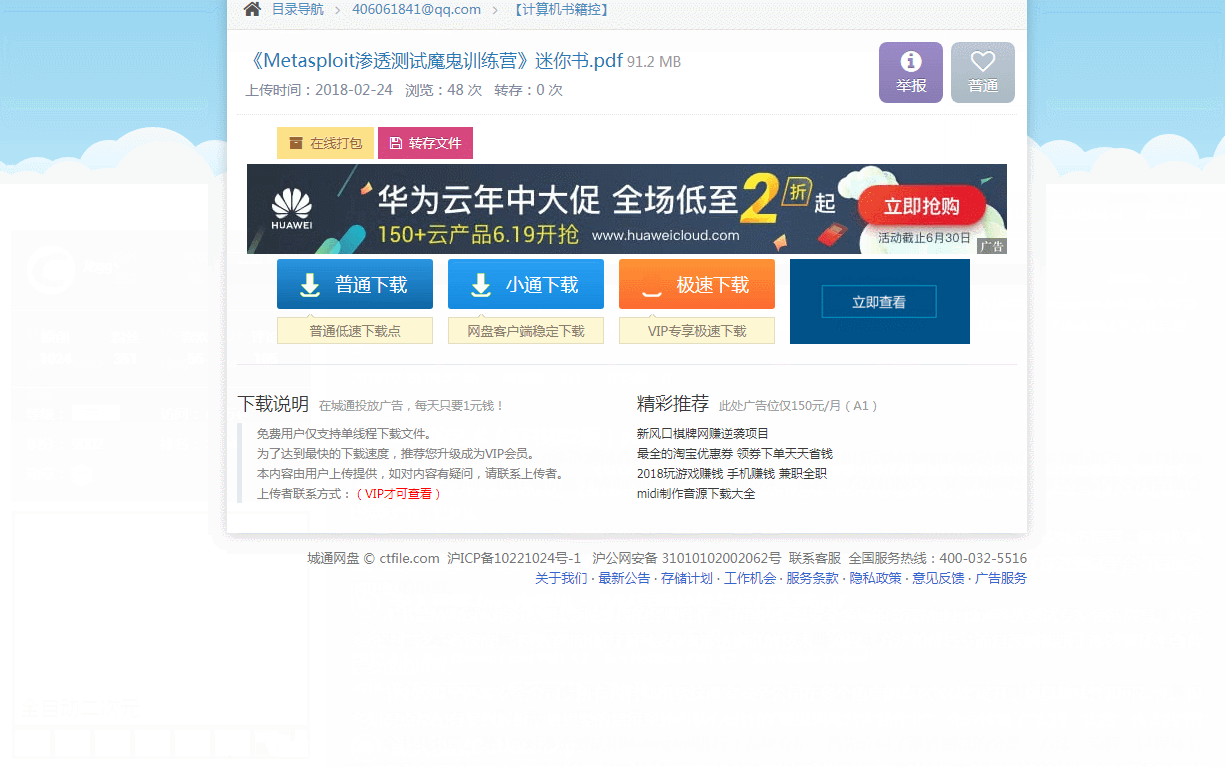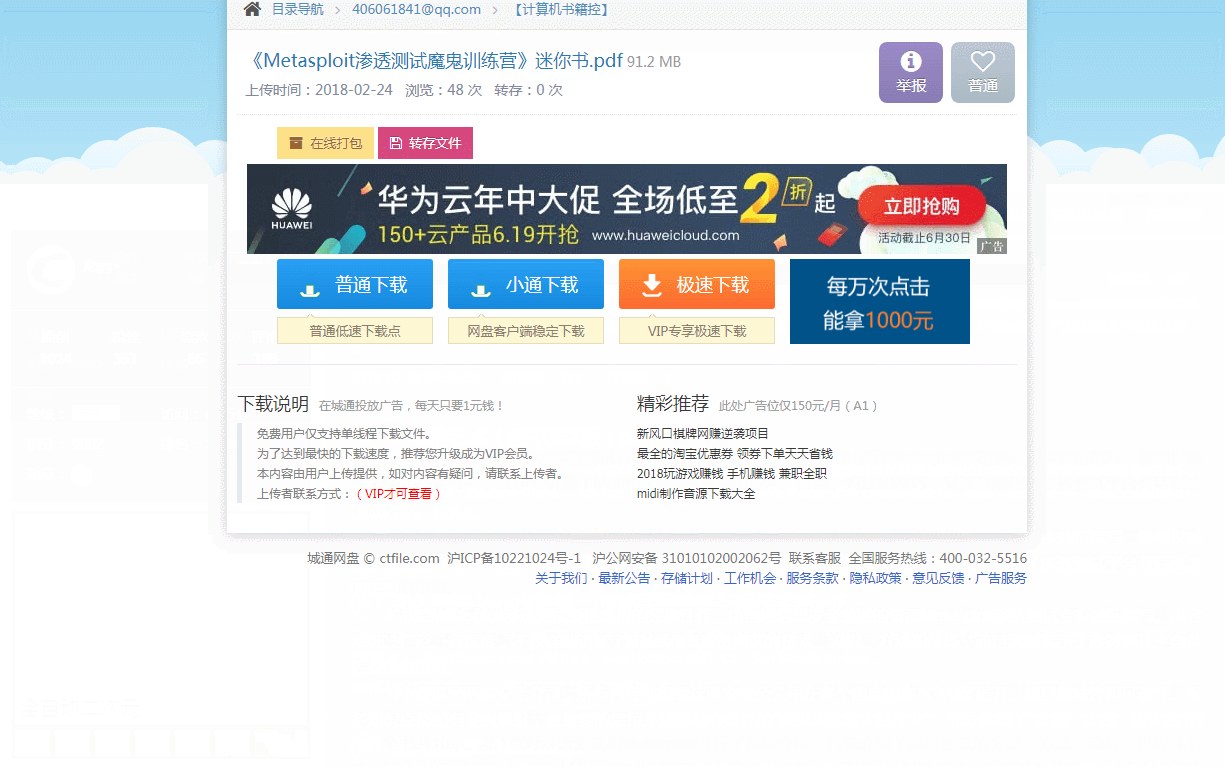
分析页面
在CSDN博客页面,查看跳转及网络请求,没有发现什么可利用的点,于是转到网盘下载页面,看下页面HTML结构如下图:
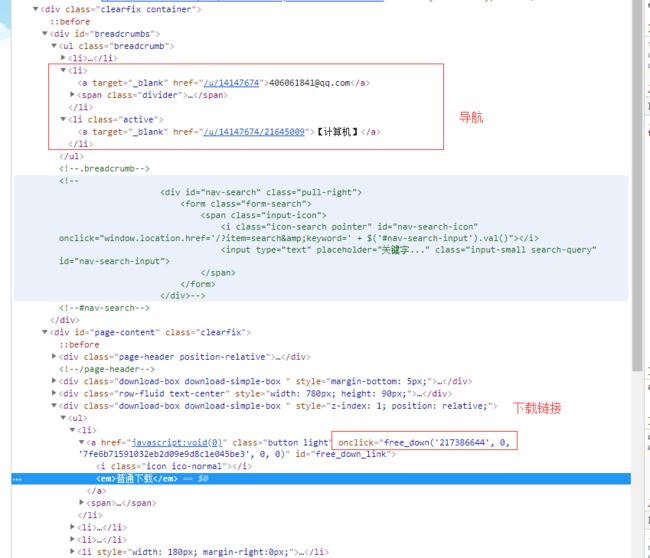
对于分析页面我就关注下面两个点:
- 下载链接的本身,发现是通过一个点击事件去处理下载逻辑的,应该是通过传入的参数生成了对应的文件下载链接以及权限验证等,搜了一下那个free_down()函数,在所有暴露的js里面都木有找到(js被混淆压缩处理了),所以破解free_down函数的方法只能暂时放弃了。
-
页面其他可利用的链接,发现有导航链接,期望可以通过导航链接能找到一个汇总的下面home页面,在尝试到第二个导航链接的时候,终于发现有用的东西了,这是用户在网盘上的上传文件汇总页面,如下图所示:
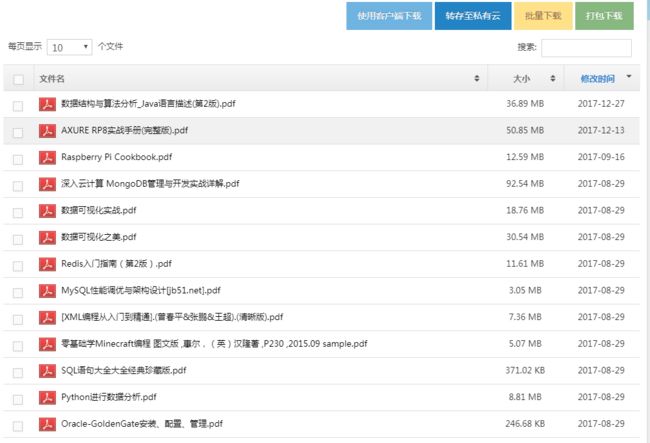
看上图,发现有批量下载和打包下载两个按钮,点进去发现都是要注册改网盘用户后才可以使用的,其实正常情况下注册后打包下载就结束了,可是今天是要将技术实现的,所以不想整这个注册,到这个页面后,我只需要拿到这些文件的下载链接就行。可是链接点进去还是回到前面的选择下载页面,看来还是得读到那个free_down()函数才行,下面给大家介绍一个简单的前端调试方法,使用chrome浏览器,按下F12进入开发者控制台,进入sources页签,找到这个页面,找到你要调试的位置,在位置对应的代码左侧的行号上点一下即可(打上debug标识的行会有一个蓝色的标志):
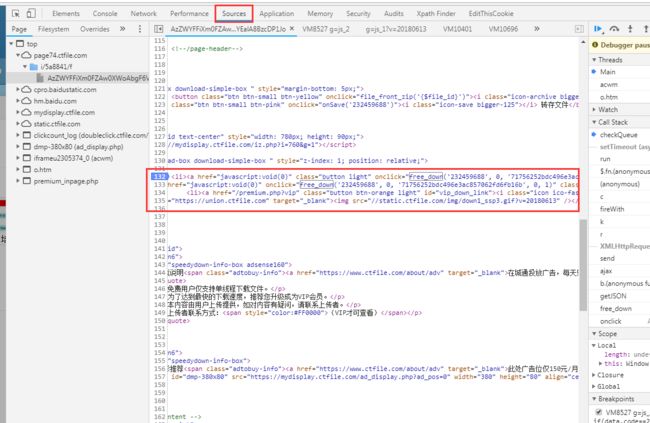
然后按F9一步步调试,然后就会跳到相关js中执行,调试发现那个js文件默认是blackboxed in debugger,难怪前端找不到,哈哈,这样就发现这个函数了,就这么简单,把那个函数提取出来:
function free_down(file_id, folder_id, file_chk, mb, app, verifycode) {
verifycode = typeof verifycode !== 'undefined' ? verifycode: "";
$.getJSON("/get_file_url.php?uid=" + userid + "&fid=" + file_id + "&folder_id=" + folder_id + "&fid=" + file_id + "&file_chk=" + file_chk + "&mb=" + mb + "&app=" + app + "&verifycode=" + verifycode + '&rd=' + Math.random(),
function(data) {
if (data.code == 503) {
if (mb) {
window.location = "/iajax_guest.php?item=file_act&action=verifycode&uid=" + userid + "&fid=" + file_id + "&folder_id=" + folder_id + "&fid=" + file_id + "&file_chk=" + file_chk + "&mb=" + mb + "&app=" + app;
} else {
$(ctmodal).load("/iajax_guest.php?item=file_act&action=verifycode&uid=" + userid + "&fid=" + file_id + "&folder_id=" + folder_id + "&fid=" + file_id + "&file_chk=" + file_chk + "&mb=" + mb + "&app=" + app).modal().draggable();
}
}
if (data.code == 200) {
if ($("#clickcount_log").size() > 0 && $("#clickcount_log").attr("src").length > 50) {
$("#clickcount_log").attr("src", data.confirm_url);
}
if (app) {
if (!mb) {
$(ctmodal).load("/iajax_guest.php?item=file_act&action=xt_downlink&xtlink=" + data.xt_link).modal().draggable();
} else {
window.location.href = "ctfile://inapp.ctfile.com/app.php?||xt||" + data.xt_link;
$("#xtlink_input").val(data.xt_link);
$("#xtlink_copy_alert").show();
}
} else {
if (!mb) {
setTimeout(function() {
free_vip_upgrade(data.file_size)
},
1000);
window.location.href = data.downurl + "&mtd=1";
} else {
window.location.href = data.downurl;
}
}
}
});
}
先读懂它:根据请求参数请求get_file_url接口,会返回一个json数据,我们只需要关注返回code=200的情况,其他都属于异常情况,在code=200的逻辑里面看到了最后就是按downurl跳转的,那么我们拿到json里面的downurl即可……下面再把参数理一下:
file_id 文件id,页面上能拿到, folder_id 文件夹id调试发现传0就可以了, app很好理解吧,是不是在网盘客户端发起的请求,我们用httpclient来请求肯定不是了,所以app=0(注:0=false,1=true),同理,mb表示mobile,是否移动端,很明显也是0,verifycode应该是登录信息,忽视它,最后说一下file_chk,这个应该是一个文件检查码,表面看可能是md5可是验证并不是,怀疑应该是按一定规则生成的,在选择下载页面就已经生成了,估计是页面渲染的时候就在js中生成了,这不太好调试,又来一个坑。。。。暂时只能再请求一次,再请求一次到下载页面拿到这个file_chk。
实现步骤:
根据上面的分析,实现步骤渐渐明晰了:
- 解析用户的上传文件汇总页面,拿到所有的电子书下载页url;
- 请求下载页url,拿到对应的file_chk;
- 根据参数组合最终的下载url;
- 请求url,将返回数据流写入磁盘文件系统;
思路有了,下面编码实现,使用HttpClinet来处理请求、Jsoup来解析页面、FastJson来解析json,先贴上对应Maven的dependency:
org.apache.httpcomponents
httpclient
4.5.2
org.apache.httpcomponents
httpmime
4.5.2
org.apache.httpcomponents
httpclient
com.alibaba
fastjson
1.2.4
org.jsoup
jsoup
1.10.3
实现第一个步骤:
解析用户的上传文件汇总页面(这里用了界面上的一个数据分页接口),拿到所有的电子书下载页url,并存入Map中。
private Map getDownloadPageUrls() throws Exception {
Map urlMap = new HashMap();
String urlFormat = "https://page74.ctfile.com/iajax_guest.php?item=file_act&action=file_list&task=file_list&folder_id=21645009&uid=" + UID + "&display_subfolders=1&t=1529909656&k=3de0d7f0ad5df1e6d6b71c4b43ce10d6&sEcho=%d&iColumns=4&sColumns=&iDisplayStart=%d&iDisplayLength=%d";
int page = 1;
int pageSize = 100;
int pageStart = 1;
int pageCount = pageSize;
while (true) {
String url = String.format(urlFormat, page, pageStart, pageSize);
HttpResponse response = new HttpRequest(url).doGet();
String responseBody = EntityUtils.toString(response.getEntity());
JSONObject data = JSONObject.parseObject(responseBody);
pageCount = data.getInteger("iTotalRecords");
JSONArray dataList = data.getJSONArray("aaData");
Document doc = null;
for (int i = 0; i < dataList.size(); i++) {
JSONArray item = dataList.getJSONArray(i);
doc = Jsoup.parse(item.get(0).toString());
Element tdId = doc.select("#file_ids").first();
String id = tdId.attr("value");
doc = Jsoup.parse(item.get(1).toString());
Element tdUrl = doc.select("a[href]").first();
String url1 = tdUrl.attr("href");
if (StringUtils.isNotEmpty(id) && StringUtils.isNotEmpty(url1)) {
url1 = MAIN_HOST + url1.replace("//", "/5a8841/");
urlMap.put(id, url1);
}
}
if (pageSize + pageStart > pageCount) {
break;
}
page++;
pageStart += pageSize;
}
System.out.println("have fetched download page url size :" + urlMap.size());
return urlMap;
}
实现第二个步骤:
请求下载页url,拿到对应的file_chk,这里请求的时候要加上header,不然会被当做非法请求。
private String getFileChk(String url) throws IOException {
Map headers = new HashMap();
headers.put("Host", new URL(url).getHost());
headers.put("Cookie", "PHPSESSID=eb2vqs2s7pgjkuuvqrq2aslov4; clicktopay=" + System.currentTimeMillis() + "; unique_id=5a8841; ua_checkmutilogin=OoDN6nCiRd;");
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36");
HttpResponse response = new HttpRequest(url).setHeaders(headers).doGet();
String responseBody = EntityUtils.toString(response.getEntity());
String chkStr = "";
Document doc = Jsoup.parse(responseBody);
Element link = doc.select("#free_down_link").first();
if (link != null) {
String text = link.attr("onclick");
if (StringUtils.isNotEmpty(text)) {
text = text.substring(text.indexOf("("), text.indexOf(")"));
String[] arr = text.split(",");
chkStr = arr[2];
chkStr = chkStr.replaceAll("'", "").trim();
}
}
return chkStr;
}
实现第三个步骤:
根据参数组合最终的下载url:
private List getDownloadUrls() throws Exception {
List urls = new ArrayList();
Map urlMap = getDownloadPageUrls();
int rndCode = new Random(1000).nextInt() + 100;
String urlFormat = "https://page74.ctfile.com/get_file_url.php?uid=" + UID + "&fid=%s&folder_id=0&file_chk=%s&mb=0&app=0&verifycode=&rd=" + rndCode;
for (Map.Entry entry : urlMap.entrySet()) {
String fid = entry.getKey();
String file_chk = getFileChk(entry.getValue());
if (StringUtils.isNotEmpty(file_chk)) {
String url = String.format(urlFormat, fid, file_chk);
HttpResponse response = new HttpRequest(url).doGet();
String responseBody = EntityUtils.toString(response.getEntity());
JSONObject data = JSONObject.parseObject(responseBody);
String downurl = data.getString("downurl");
if (StringUtils.isNotEmpty(downurl)) {
urls.add(downurl);
}
}
}
return urls;
}
实现第四个步骤:
请求url,并将返回的数据流写入磁盘文件系统,刚开始我是采用多线程的处理方式,因为毕竟下载一个文件要几分钟时间,可是跑起来发现,普通下载只给支持单线程,网盘服务端限制了,暂时改成单线程处理咯(花时间钻研下,应该可以破了它)
@Test
public void crawlAll1() throws Exception {
List urls = getDownloadUrls();
for (String url : urls) {
String name = getFileName(url);
try {
System.out.println("[Begin] task is begin to run with download file: " + name);
HttpRequest.doDownload(DATA_PATH, url);
System.out.println("[End] task have finished to run with download file: " + name);
} catch (Exception e) {
System.err.println("[Error] task meet error when process url: " + url);
e.printStackTrace();
}
}
}
最后还要贴一下doDownload()方法:
public static void doDownload(String path, String url) throws Exception {
HttpClient httpClient = getSSLHttpClient();
URL Url = new URL(url);
String paths = Url.getPath();
String fileName = "";
for (String param : paths.split("/")) {
if (param.toLowerCase().endsWith(".pdf")) {
fileName = URLDecoder.decode(param, "UTF-8");
break;
}
}
fileName = path + fileName;
File file = new File(fileName);
if(file.exists()) {
file.delete();
}
try {
//使用file来写入本地数据
file.createNewFile();
FileOutputStream outStream = new FileOutputStream(fileName);
//执行请求,获得响应
HttpResponse httpResponse = httpClient.execute(new HttpGet(url), new BasicHttpContext());
int code = httpResponse.getStatusLine().getStatusCode();
System.out.println("[DOWNLOADING STATUS] get response status [" + httpResponse.getStatusLine() + "] for file :" + file.getName());
if (code == 200) {
HttpEntity httpEntity = httpResponse.getEntity();
InputStream inStream = httpEntity.getContent();
while (true) {//这个循环读取网络数据,写入本地文件
byte[] bytes = new byte[1024 * 1024]; //1M
int k = inStream.read(bytes);
if (k >= 0) {
outStream.write(bytes, 0, k);
outStream.flush();
} else break;
}
inStream.close();
outStream.close();
}
} catch (IOException e){
e.printStackTrace();
}
}
跑起来,效果如下(没有多线程下载,就是慢了点点):
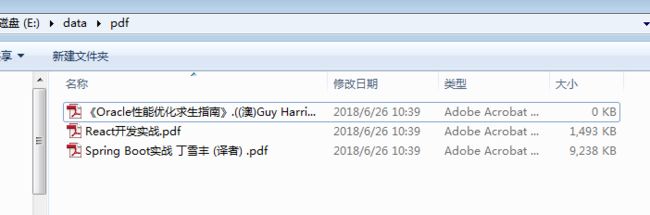

PS:完整代码(包含多线程下载的实现),已上传到github的demo项目下:https://github.com/AlanYangs/demo/tree/master/pdf-spider,欢迎大家start~
原文来自下方公众号,转载请联系作者,并务必保留出处。
想第一时间看到更多原创技术好文和资料,请关注公众号:测试开发栈
