mysql高级之表分区
下列说明为个人见解,欢迎交流指正。
1、表分区简介
1.1 问题概述
问题引出:假设一个商城订单系统,每年一个总表为order_year_2018,最近三个月有一个分表order_mouth_3。用户按年份选择订单就到年表中查询,按最近三个月选择订单就到最近三个月的分表中查询,问如何设计年表。
为保持读写稳定,有两种设计方案:
年表不包含近三个月的表,这样出现的问题是查询本年订单时,需要跨两张表查询,如果后面还要连表查询其它商品等信息再排序可能会更复杂。
年表包含近三个月的表数据,相当于冗余三个月的数据来提高查询效率,这样的问题是订单数据发生变化时,要同时更新年表和月表,比较麻烦。
问题解决方案:表分区。
1.2 mysql对数据的存储
mysql数据库中的数据是以文件的形式存在磁盘上的,默认放在/mysql/var下面(可以通过my.cnf中的datadir来查看), 对存储引擎为myisam来说,一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引。
如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
表分区是mysql被Oracle收购后推出的一个新特性。
1.3 mysql的表分区
1.3.1 表分区
1、分区表是什么
通俗地讲表分区是将一大表,根据条件分割成若干个小表。mysql5.1开始支持数据表分区。
如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区。当然也可根据其他的条件分区。
2、分区表的原理
分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
在分区表上的操作按照下面的操作逻辑进行:
select查询:当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据。
insert操作:当写入一条记录时,分区层打开并锁住所有的底层表,然后确定哪个分区接受这条记录,再将记录写入对应的底层表。
delete操作:当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作。
update操作:当更新一条数据时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据应该放在哪个分区,然后对底层表进行写入操作,并对原数据所在的底层表进行删除操作
虽然每个操作都会打开并锁住所有的底层表,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,如:innodb,则会在分区层释放对应的表锁,这个加锁和解锁过程与普通Innodb上的查询类似。
1.3.2 表分区的优劣势
1、优势
为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。
分区的一些优点包括:
- 与单个磁盘或文件系统分区相比,可以存储更多的数据。
- 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。
通常和分区有关的其他优点包括下面列出的这些。MySQL分区中的这些功能目前还没有实现,但是在我们的优先级列表中,具有高的优先级;我们希望在5.1的生产版本中,能包括这些功能。
- 一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
- 涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这种查询的一个简单例子如 “SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;”。通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
- 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
2、劣势
限制暂且归位劣势。
- 一个表最多只能有1024个分区(mysql5.6之后支持8192个分区)。
- 在mysql5.1中分区表达式必须是整数,或者是返回整数的表达式,在5.5之后,某些场景可以直接使用字符串列和日期类型列来进行分区(使用varchar字符串类型列时,一般还是字符串的日期作为分区)。
- 如果分区字段中有主键或者唯一索引列,那么所有主键列和唯一索引列都必须包含进来,如果表中有主键或唯一索引,那么分区键必须是主键或唯一索引。
- 分区表中无法使用外键约束。
- mysql数据库支持的分区类型为水平分区,并不支持垂直分区,因此,mysql数据库的分区中索引是局部分区索引,一个分区中既存放了数据又存放了索引,而全局分区是指的数据库放在各个分区中,但是所有的数据的索引放在另外一个对象中
- 目前mysql不支持空间类型和临时表类型进行分区。不支持全文索引。
1.3.3 表分区的类型
- RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
- LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
- HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
- KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
1、RANGE分区(常用)
基于属于一个给定连续区间的列值,把多行分配给分区。这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。以下是实例。
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null,
store_id int not null
) partition by range (store_id) (
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21),
partition p3 values less than maxvalue
);
按照这种分区方案,在商店1到5工作的雇员相对应的所有行被保存在分区P0中,商店6到10的雇员保存在P1中,依次类推。注意,每个分区都是按顺序进行定义,从最低到最高。这是PARTITION BY RANGE 语法的要求;在这点上,它类似于C或Java中的“switch ... case”语句。
2、LIST分区
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr”是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。
注释:在MySQL 5.1中,当使用LIST分区时,有可能只能匹配整数列表。
假定有20个音像店,分布在4个有经销权的地区,如下所示:
====================================
地区 商店ID 号
------------------------------------
北区 3, 5, 6, 9, 17
东区 1, 2, 10, 11, 19, 20
西区 4, 12, 13, 14, 18
中心区 7, 8, 15, 16
====================================
要按照属于同一个地区商店的行保存在同一个分区中的方式来分割表,可以使用下面的“CREATE TABLE”语句:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null,
store_id int not null
) partition by list(store_id)
partition pNorth values in (3,5,6,9,17),
partition pEast values in (1,2,10,11,19,20),
partition pWest values in (4,12,13,14,18),
partition pCentral values in (7,8,15,16)
);
这使得在表中增加或删除指定地区的雇员记录变得容易起来。例如,假定西区的所有音像店都卖给了其他公司。那么与在西区音像店工作雇员相关的所有记录(行)可以使用查询“ALTER TABLE employees DROP PARTITION pWest;”来进行删除,它与具有同样作用的DELETE (删除)查询“DELETE query DELETE FROM employees WHERE store_id IN (4,12,13,14,18);”比起来,要有效得多。
要重点注意的是,LIST分区没有类似如“VALUES LESS THAN MAXVALUE”这样的包含其他值在内的定义。将要匹配的任何值都必须在值列表中找到。
LIST分区除了能和RANGE分区结合起来生成一个复合的子分区,与HASH和KEY分区结合起来生成复合的子分区也是可能的。
3、HASH分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL 整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null,
store_id int not null
) partition by hash(store_id)
partitions 4;
如果没有包括一个“PARTITIONS num”子句,那么分区的数量将默认为1。
4、KSY分区
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
create table tk (
col1 int not null,
col2 char(5),
col3 date
) partition by linear key (col1)
partitions 3;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
1.4 表分区的相关操作
1.4.1 建立表分区
create table employees (
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null,
store_id int not null
) partition by range (store_id) (
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21),
partition p3 values less than maxvalue
);
1.4.2 增加表分区
PARTITION p1 VALUES LESS THAN (MAXVALUE) 这句要去掉,才可以增加分区。
ALTER TABLE sale_data ADD PARTITION (PARTITION s20100402 VALUES LESS THAN (20100403));
1.4.3 删除表分区
ALTER TABLE sale_data DROP PARTITION s20100406 ;
1.4.4 正常使用
insert into sale_data values('2010-04-01','11',11.11);
insert into sale_data values('2010-04-02','22',22.22);
1.4.5 查看分区
SELECT PARTITION_NAME,TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'sale_data';
以上转自:表分区详解
2、表分区实践
2.1 创建表
分别创建分区表和不分区表
# 不分区表
CREATE TABLE no_part_tab(c1 int default NULL, c2 varchar(30) default NULL, c3 date not null) default charset utf8;
# 分区表
CREATE TABLE part_tab
(c1 int default NULL, c2 varchar(30) default NULL, c3 date not null)
default charset utf8
PARTITION BY RANGE(year(c3))
(PARTITION p0 VALUES LESS THAN (1995),
PARTITION p1 VALUES LESS THAN (1996) ,
PARTITION p2 VALUES LESS THAN (1997) ,
PARTITION p3 VALUES LESS THAN (1998) ,
PARTITION p4 VALUES LESS THAN (1999) ,
PARTITION p5 VALUES LESS THAN (2000) ,
PARTITION p6 VALUES LESS THAN (2001) ,
PARTITION p7 VALUES LESS THAN (2002) ,
PARTITION p8 VALUES LESS THAN (2003) ,
PARTITION p9 VALUES LESS THAN (2004) ,
PARTITION p10 VALUES LESS THAN (2010),
PARTITION p11 VALUES LESS THAN (MAXVALUE) );
2.2 插入数据
插入相同数据(利用存储过程)
1、创建存储过程
DELIMITER &&
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end &&
DELIMITER ;
这里说明下,因为mysql默认‘;’号为语句结束符,存储过程也是利用分号作为语句结束符,为避免冲突错误产生,先重定义mysql语句结束符为‘&&’,后恢复‘;’。
2、调用存储过程
call load_part_tab();
3、复制表数据
insert into no_part_tab select * from part_tab;
2.3 查看表分区信息
2.3.1 查看创建分区表语句
show create table `part_tab`;
# 结果
CREATE TABLE `part_tab` (
`c1` int(11) DEFAULT NULL,
`c2` varchar(30) DEFAULT NULL,
`c3` date NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (year(c3))
(PARTITION p0 VALUES LESS THAN (1995) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1996) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (1997) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (1998) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (1999) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (2000) ENGINE = InnoDB,
PARTITION p6 VALUES LESS THAN (2001) ENGINE = InnoDB,
PARTITION p7 VALUES LESS THAN (2002) ENGINE = InnoDB,
PARTITION p8 VALUES LESS THAN (2003) ENGINE = InnoDB,
PARTITION p9 VALUES LESS THAN (2004) ENGINE = InnoDB,
PARTITION p10 VALUES LESS THAN (2010) ENGINE = InnoDB,
PARTITION p11 VALUES LESS THAN MAXVALUE ENGINE = InnoDB)
2.3.2 查看表是不是分区表
show table status like '%part_tab%';
Name no_part_tab part_tab
Engine InnoDB InnoDB
Version 10 10
Row_format Dynamic Dynamic
Rows 199500 199500
Avg_row_length 55 79
Data_length 11026432 15925248
Max_data_length 0 0
Index_length 0 0
Data_free 4194304 41943040
Auto_increment NULL NULL
Create_time 2018-02-28 05:43:16 2018-02-28 05:43:53
Update_time 2018-02-28 06:54:07 2018-02-28 06:47:47
Check_time NULL NULL
Collation utf8_general_ci utf8_general_ci
Checksum NULL NULL
Create_options partitioned
Comment
注:为保持对比效果,手动竖向排列布局。
Create_options一栏指示是否分区。
2.3.3 表分区详细信息
查看information_schema.partitions表。
SELECT * FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'part_tab'
信息有点多,略去,下面挑几个关键字段。

2.3.3 表分区使用信息
explain partitions select * from `part_tab`;

2.4 性能对比
2.4.1 耗时对比
插入数据比较耗时,只插入了10w条数据,耗时30min。
由于数据量比较小,字段少,然后耗时一样:(0.07 sec)。
select * from `part_tab`;
select * from `no_part_tab`;
2.4.2 扫描次数对比
explain select * from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
explain select * from no_part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
结果如下如所示:
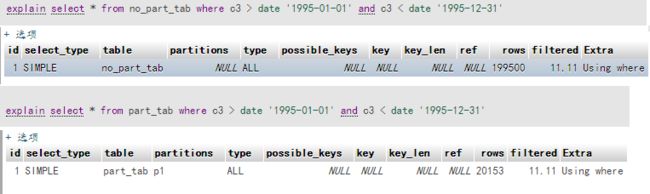
如上:普通表扫描了 8000000次, 分区表扫描了798458次。
分区表扫描比例是普通表的:20153/199500 = 10.10%。
3、分区适用场景
3.1 常见使用场景
- 当数据量很大(过T)时,肯定不能把数据再如到内存中,这样查询一个或一定范围的item是很耗时。另外一般这情况下,历史数据或不常访问的数据占很大部分,最新或热点数据占的比例不是很大。这时可以根据有些条件进行表分区。
- 分区表的更易管理,比如删除过去某一时间的历史数据,直接执行truncate,或者狠点drop整个分区,这比detele删除效率更高
- 当数据量很大,或者将来很大的,但单块磁盘的容量不够,或者想提升IO效率的时候,可以把没分区中的子分区挂载到不同的磁盘上。
- 使用分区表可避免某些特殊的瓶颈,例如Innodb的单个索引的互斥访问..
- 单个分区表的备份很恢复会更有效率,在某些场景下
总结:可伸缩性,可管理性,提高数据库查询效率。
3.2 业务场景举例
项目中需要动态新建、删除分区。如新闻表,按照时间维度中的月份对其分区,为了防止新闻表过大,只保留最近6个月的分区,同时预建后面3个月的分区,这个删除、预建分区的过程就是分区表的动态管理。
以上参阅:Mysql数据库表分区深入详解
4、暂举一些一些坑
由于目前公司业务出现这个瓶颈,表分区是一个解决方案,但是还没应用到实际中,下面列举一些搜集的坑。
MySQL5.6 表分区数量太多引发的血案。
key 分区时,分区表中数量不均
下面这个对于理解分区的劣势还是很重要的,主要第三点。
分区键必须是唯一键
太高级,作为借鉴。
一个MySQL 5.7 分区表性能下降的案例分析