在HttpKVAPI中kvstore的集群增加一个节点请求处理如下:
case r.Method == "POST":
url, err := ioutil.ReadAll(r.Body)
if err != nil {
log.Printf("Failed to read on POST (%v)\n", err)
http.Error(w, "Failed on POST", http.StatusBadRequest)
return
}
nodeId, err := strconv.ParseUint(key[1:], 0, 64)
if err != nil {
log.Printf("Failed to convert ID for conf change (%v)\n", err)
http.Error(w, "Failed on POST", http.StatusBadRequest)
return
}
cc := raftpb.ConfChange{
Type: raftpb.ConfChangeAddNode,
NodeID: nodeId,
Context: url,
}
h.confChangeC <- cc
// As above, optimistic that raft will apply the conf change
w.WriteHeader(http.StatusNoContent)
处理逻辑是向confChangeC通道写入增加节点消息,下面看下raftNode的routine中对该通道事件的处理:
//集群变更事件
case cc, ok := <-rc.confChangeC:
if !ok {
rc.confChangeC = nil
} else {
confChangeCount += 1
cc.ID = confChangeCount
rc.node.ProposeConfChange(context.TODO(), cc)
}
}
调用了node的ProposeConfChange方法:
func (n *node) ProposeConfChange(ctx context.Context, cc pb.ConfChange) error {
data, err := cc.Marshal()
if err != nil {
return err
}
return n.Step(ctx, pb.Message{Type: pb.MsgProp, Entries: []pb.Entry{{Type: pb.EntryConfChange, Data: data}}})
}
调用了node的Step方法,然后调用step方法,触发MsgProp事件:
func (n *node) step(ctx context.Context, m pb.Message) error {
ch := n.recvc
if m.Type == pb.MsgProp {
//当是追加配置请求时ch为n.propc
ch = n.propc
}
select {
//当是追加配置请求时会向ch(即n.propc)通道写入数据(消息类型和数据)
case ch <- m:
return nil
case <-ctx.Done():
return ctx.Err()
case <-n.done:
return ErrStopped
}
}
由此可见对于集群变更的处理是将集群变更信息写入n.propc通道,下面看下leader角色的node对于该通道数据的处理,在raft的stepLeader方法中:
case pb.MsgProp:
//配置追加请求
if len(m.Entries) == 0 {
r.logger.Panicf("%x stepped empty MsgProp", r.id)
}
if _, ok := r.prs[r.id]; !ok {
// If we are not currently a member of the range (i.e. this node
// was removed from the configuration while serving as leader),
// drop any new proposals.
return
}
if r.leadTransferee != None {
r.logger.Debugf("%x [term %d] transfer leadership to %x is in progress; dropping proposal", r.id, r.Term, r.leadTransferee)
return
}
for i, e := range m.Entries {
if e.Type == pb.EntryConfChange {
if r.pendingConf {
r.logger.Infof("propose conf %s ignored since pending unapplied configuration", e.String())
m.Entries[i] = pb.Entry{Type: pb.EntryNormal}
}
r.pendingConf = true
}
}
r.appendEntry(m.Entries...)
r.bcastAppend()
return
有以上代码可知是将该集群变更作为日志追加到本地r.appendEntry(m.Entries...),然后向其他follower发送附加日志rpc:r.bcastAppend()。
当该集群变更日志复制到过半数server后,raftNode提交日志的处理逻辑如下:
case raftpb.EntryConfChange:
var cc raftpb.ConfChange
cc.Unmarshal(ents[i].Data)
rc.confState = *rc.node.ApplyConfChange(cc)
switch cc.Type {
case raftpb.ConfChangeAddNode:
if len(cc.Context) > 0 {
rc.transport.AddPeer(types.ID(cc.NodeID), []string{string(cc.Context)})
}
case raftpb.ConfChangeRemoveNode:
if cc.NodeID == uint64(rc.id) {
log.Println("I've been removed from the cluster! Shutting down.")
return false
}
rc.transport.RemovePeer(types.ID(cc.NodeID))
}
}
对于添加一个节点的处理,首先是更新集群变更的状态信息,如下:
func (n *node) ApplyConfChange(cc pb.ConfChange) *pb.ConfState {
var cs pb.ConfState
select {
case n.confc <- cc:
case <-n.done:
}
select {
case cs = <-n.confstatec:
case <-n.done:
}
return &cs
}
会向n.confc通道写入集群变更消息,下面看node的处理:
case cc := <-n.confc:
if cc.NodeID == None {
r.resetPendingConf()
select {
case n.confstatec <- pb.ConfState{Nodes: r.nodes()}:
case <-n.done:
}
break
}
switch cc.Type {
case pb.ConfChangeAddNode:
r.addNode(cc.NodeID)
case pb.ConfChangeRemoveNode:
// block incoming proposal when local node is
// removed
if cc.NodeID == r.id {
propc = nil
}
r.removeNode(cc.NodeID)
case pb.ConfChangeUpdateNode:
r.resetPendingConf()
default:
panic("unexpected conf type")
}
select {
case n.confstatec <- pb.ConfState{Nodes: r.nodes()}:
case <-n.done:
}
r.addNode的代码如下:
func (r *raft) addNode(id uint64) {
r.pendingConf = false
if _, ok := r.prs[id]; ok {
// Ignore any redundant addNode calls (which can happen because the
// initial bootstrapping entries are applied twice).
return
}
r.setProgress(id, 0, r.raftLog.lastIndex()+1)
}
就是设置下该peer的发送日志进度信息。再回到raftNode中对于可提交的集群变更日志的处理,在更新完集群信息后执行了rc.transport.AddPeer(types.ID(cc.NodeID), []string{string(cc.Context)}),即把该节点加入到当前集群,建立与该节点的通信,这块代码之前分析过了不再赘述。当该日志在其他follower也提交时,其他follower也会同样处理把这个新节点加入集群。
因此,只有集群变更日志在当前server被提交完成后,当前server才建立与新节点的通信,才知道集群的最新规模,在复制集群变更日志的过程中他们依然不知道集群的最新规模。但对于新节点来说,在启动式会知道老集群的节点信息,因此新节点启动后就知道了集群的最新规模。
总结如下,在ectd的raft实现中,处理集群变更的方案是:每次变更只能添加或删除一个节点,不能一次变更多个节点,因为每次变更一个节点能保证不会有多个leader同时产生,下面以下图为例分析下原因。
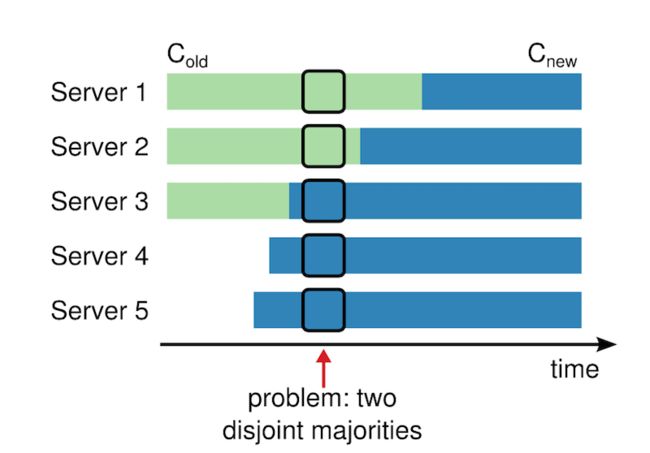
最初节点个数为3,即server1、server2、server3,最初leader为server3,如果有2个节点要加入到集群,那么在原来的3个节点收到集群变更请求前认为集群中有3个节点,确切的说是集群变更日志提交前,假如server3作为leader,把集群变更日志发送到了server4、server5,这样可以提交该集群变更日志了,因此server3、server4、server5的集群变更日志提交后他们知道当前集群有5个节点了。而server1和server2还没收到集群变更日志或者收到了集群变更日志但没有提交,那么server1和server2认为集群中还是有3个节点。假设此时server3因为网络原因重新发起选举,server1也同时发起选举,server1在收到server2的投票赞成响应而成为leader,而server3可以通过server4和server5也可以成为leader,这时出现了两个leader,是不安全且不允许的。
但如果每次只添加或减少1个节点,假设最初有3个节点,有1个节点要加入。最初leader为server1,在server1的集群变更日志提交前,server1、server2、server3认为集群中有3个节点,只有server4认为集群中有4个节点,如果leader在server1、server2、server3中产生,那么必然需要2个server,而server4只能收到server1、server2、server3中1个server的响应,是无法成为leader的,因为server4认为集群中有4个节点,需要3个节点同意才能成为leader。如果在server1是leader时该集群变更日志提交了,那么集群中至少有2个server有该集群变更日志了,假如server1和server2都有该集群变更日志了,server3和server4还没有,那么server3和server4不可能被选为leader,因为他们的日志不够新。对于server4来说需要3个server同时同意才能成为leader,而server1和server2的日志比他新,不会同意他成为leader。对于server3来说,在集群变更日志提交前他认为集群中只有3个server,因此只会把投票请求发送给server1和server2,而server1和server2因为日志比他新不会同意;如果server3的集群变更日志也提交了,那么他人为集群中有4个节点,这时与server4一样,需要3个server同时同意才能成为leader,如果server1通过server2成为leader了,那么server1和server2都不会参与投票了。
因此每次一个节点的加入不管在集群变更日志提交前、提交过程中还是提交后都不会出现两个leader的情况。
提交前是因为原来的节点不知道这个新的节点,不会发送投票给他,也不会处理新节点的投票请求;
提交后是因为大家都知道集群的最新规模了,不会产生两个大多数的投票;
提交过程中是因为没有这条集群变更日志的server由于日志不够新也不能成为leader,比如最初集群规模是2n+1,现在有1个新节点加入,如果集群变更日志复制到了过半数server,因为之前的leader是老的集群的,因此过半数是n+1,假如这个n+1个server中产生了一个leader,那么对于新的节点来说,因为集群变更日志还没有应用到状态机所以只有这个新节点认为集群中有2n+2个server,因此需要n+2个server同意投票他才能成为leader,但这是不可能的,因为已经有n+1个节点已经投过票了,而对于老集群中的剩下的没有投票的n个节点中,他们任何一个server都需要n+1个server同意才能成为leader,而他们因为还没有把集群变更日志真正提交即应用到状态机,还不知道新节点的存在,也就不能收到n+1个server投票,最多只能收到n个节点的投票,因此也不能成为leader,保证了只能有一个leader被选出来。