记得在前一段时间由于需要并且是第一次接触爬虫,没有成功获取到数据,了解爬虫一段时间之后,再次爬取拉钩网职位信息,本此采用单线程爬虫,之后会发布scrapy写法。
- 获取的主要字段:
- 职位名称
- 公司名称
- 城市
- 公司规模
- 公司类型
- 月薪
- 行业领域
- firstType
- secondType
- 工作经历
- 学历
首先,输入python工程师进行搜索,选择城市之后发现url并未发生改变,通过抓包工具抓到了返回的json数据,这个时候我们就要考虑怎么去构造URL,下边是抓包截图

明白了数据的加载方式,接下来就要分析它所携带的参数和请求方式
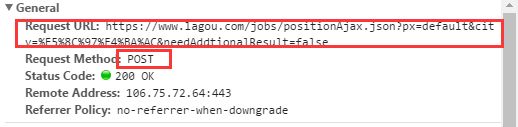
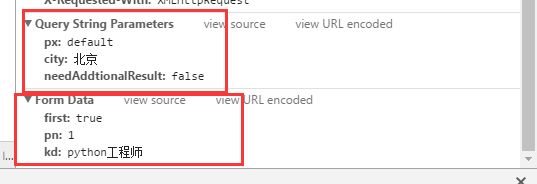
从上图我们可以了解到URL及其携带的参数,那么接下来的工作就好办了,我们只要传递相对应的参数就可以拿到返回的json串,具体构造方式看之后的分析,因为还牵扯到页码的分析
搞明白了数据的加载的方式以及怎么构造URL,接下来就好考虑不同的职位、城市以及对应的分页问题
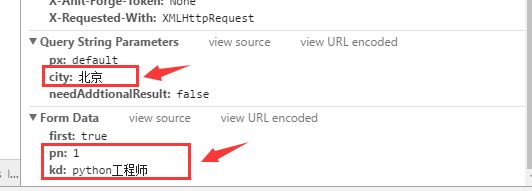

在相同地点点击下一页之后只有pn发生了改变,所以很显然,pn控制分页问题,接下来我们尝试一下更换地点,与上图进行对比看一下哪些参数变化了
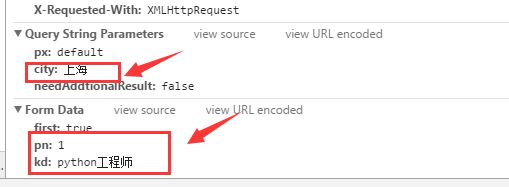
从上图可以看出更改地点之后city发生了变化,所以city控制城市,那么很显然kd控制职位切换
整明白了每个参数的含义,接下来我们就要考虑怎么找到到一个城市关于这个职位划分的总页数,从下图我们可以看到一个职位在不同城市的总页数是不同的


通过上边的一些介绍,接下来开始讲解每一部分的URL每一部分的参数的获取和构造完整的URL。
首先,职位和城市我们就没必要从网页上拿,可以自己存一个列表,然后遍历,那么就重点说一下总页数的获取

soup = BeautifulSoup(response.text, 'lxml')
pages = soup.find('span', {'class': 'span totalNum'}).get_text()
上边说明了总页数的位置及获取方法,接着说一下 职位+城市+页码的变化整个的构造方法(城市主要是拉钩网13个常用城市,先列两个关于python的职位)
#获取相关职位总页数
def get_total_page():
kd = ['python工程师','python数据分析']
city = ['北京','上海','深圳','广州','杭州','成都','南京','武汉','西安','厦门','长沙','苏州','天津']
urls_kd = ['https://www.lagou.com/jobs/list_{}?px=default&city='.format(one) for one in kd]
for urls in urls_kd:
urls_city = [urls+one for one in city]
for url in urls_city:
response = requests.get(url, headers=headers, cookies=cookies)
location = url.split('&')[-1].split('=')[1]
key = url.split('/')[-1].split('?')[0].split('_')[1]
soup = BeautifulSoup(response.text, 'lxml')
pages = soup.find('span', {'class': 'span totalNum'}).get_text()
print '职业:{}获取城市{}'.format(key,location)
create_url(pages,location,key)
#构造URL
def create_url(pages,city,kd):
for i in range(1,int(pages)+1):
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(city)
get_data(url,i,kd)
#获取详细数据写入csv文件
def get_data(url,i,kd):
print '第{}页数据'.format(i)
formdata = {
'first': 'true',
'pn': i,
'kd': kd
}
#注意这里是post请求
response = requests.post(url,headers=headers,cookies=cookies,data=formdata)
以上为核心代码,剩余的就是解析json数据和写文件了,就不一一列出来了
结果


总结
1遇到的问题
之前访问该网站一直ip被封,后来就想着用代理ip,其实没必要这么麻烦,只需要访问的时候加上cookie就可以了,至少我现在访问这些职位和城市没出现ip被封的情况。
写入csv文件出现多一行空行的问题——解决办法
Python中的csv的writer,打开文件的时候,要小心,
要通过binary模式去打开,即带b的,比如wb,ab+等
而不能通过文本模式,即不带b的方式,w,w+,a+等,否则,会导致使用writerow写内容到csv中时,产生对于的CR,导致多余的空行。2 感悟
对一个网页的爬取的关键点在于怎么去找到这些数据的准确位置,而这个前提是了解URL构造,参数、以及请求方式,整明白这些就成功了一大半,对于后边数据的提取就是一些常规的思路
单线程总体来说是比较慢的,之后改进加多线程或者用scrapy框架爬取数据
以上就是关于requests爬取拉钩网的一个简单的思路,有问题的可以留言或者评论一块探讨