Python:将爬取的网页数据写入Excel文件中
通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的简单实现方法。
必要的第三方库:requests、beautifulsoup4、xlwt。
先来看看通过使用Excel文件保存数据的一个简单实例。
#导入xlwt模块 import xlwt #创建一个Workbook对象,即创建一个Excel工作簿 f = xlwt.Workbook() #创建学生信息表 #sheet1表示Excel文件中的一个表 #创建一个sheet对象,命名为“学生信息”,cell_overwrite_ok表示是否可以覆盖单元格,是Worksheet实例化的一个参数,默认值是False sheet1 = f.add_sheet(u'学生信息',cell_overwrite_ok=True) #标题信息行集合 rowTitle = [u'学号',u'姓名',u'性别',u'出生年月'] #学生信息行集合 rowDatas = [[u'10001',u'张三',u'男',u'1998-2-3'],[u'10002',u'李四',u'女',u'1999-12-12'],[u'10003',u'王五',u'男',u'1998-7-8']] #遍历向表格写入标题行信息 for i in range(0,len(rowTitle)): # 其中的'0'表示行, 'i'表示列,0和i指定了表中的单元格,'rowTitle[i]'是向该单元格写入的内容 sheet1.write(0,i,rowTitle[i]) #遍历向表格写入学生信息 for k in range(0,len(rowDatas)): #先遍历外层的集合,即每行数据 for j in range(0,len(rowDatas[k])): #再遍历内层集合,j表示列数据 sheet1.write(k+1,j,rowDatas[k][j]) #k+1表示先去掉标题行,j表示列数据,rowdatas[k][j] 插入单元格数据 #保存文件的路径及命名 f.save('D:/WriteToExcel.xlsx')
在D盘对应的名为WriteToExcel.xlsx的Excel文件中,发现信息已被插入到表格中。
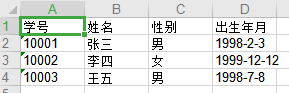
类似地,将爬取到的数据写入Excel文件中保存。
import requests from bs4 import BeautifulSoup import xlwt def getHtml(): #k代表存储到Excel的行数 k=1 #创建一个工作簿 f = xlwt.Workbook() #创建一个工作表 sheet = f.add_sheet("Python相关职业招聘信息") rowTitle = ['职位名', '公司名', '工作地点', '薪资', '发布时间','链接'] for i in range(0,len(rowTitle)): sheet.write(0, i, rowTitle[i]) url='https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' #解析第1页 for page in range(1): res = requests.get(url.format(page)) res.encoding = 'GBK' soup = BeautifulSoup(res.text, 'html.parser') t1 = soup.find_all('.t1 span a') t2 = soup.select('.t2 a') t3 = soup.select('.t3') t4 = soup.select('.t4') t5 = soup.select('.t5') for i in range(len(t1)): job = t1[i].get('title')#获取职位名 href = t2[i].get('href')#获取链接 company = t2[i].get('title')#获取公司名 location = t3[i+1].text#获取工作地点 salary = t4[i+1].text#获取薪资 date = t5[i+1].text#获取发布日期 print(job + " " + company + " " + location + " " + salary + " " + date + " " + href) f.write(k,0,job) f.write(k,1,company) f.write(k,2,location) f.write(k,3,salary) f.write(k,4,date) f.write(k,5,href) k+=1#每存储一行 k值加1 f.save('D:/Python相关职业招聘信息.xlsx')#写完后调用save方法进行保存 if __name__=='__main__': getHtml()
![]()