DDL:Data Defination Language
描述Hive表数据的结构:create alter drop.....
Hive构建在Hadoop之上
Hive的数据存放在HDFS之上
Hive的元数据可以存放在RDBMS之上;
数据库操作:
创建数据库基础语句:CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
default是Hive中默认的一个数据库
hive表在hdfs中的默认存放路径:/user/hive/warehouse/
数据库基本操作:
create 、alter 、drop 、show 、desc 、use
最最!!基本数据类型
int bigint float double decimal
boolean XXX
string
date/timestamp XXX
分隔符
行: \n
列: \001 ^A ==>
1 zhangsan 30
1$$$zhangsan$$$30
全部数据类型见官网:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
表操作:
Table
进入数据库:use ruozedata;
创建表的同时,指定行分隔符:
CREATE TABLE ruozedata_person
(id int comment 'this is id', name string comment 'this id name' )
comment 'this is ruozedata_person'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' ;
create table ruozedata_emp
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double, deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' ;
载入数据:
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE ruozedata_emp;
local: 从本地文件系统加载数据到hive表
非local:从HDFS文件系统加载数据到hive表
OVERWRITE: 加载数据到表的时候数据的处理方式,覆盖
非OVERWRITE:追加;
创建一个表并把另一个表的数据结构完全导入
(相当于复制一个表):
CREATE table ruozedata_emp2 as select * from ruozedata_emp;
仅仅复制表结构:
CREATE table ruozedata_emp3 like ruozedata_emp;
改名:ALTER TABLE ruozedata_emp3 RENAME TO ruozedata_emp3_new;
表的基本操作:
create alter drop show desc
创建表默认使用的是MANAGED_TABLE:内部表
ruozedata_emp_managed
drop:hdfs+meta;
内部表删除是完全删除,hdfs中的数据,与mysql中的meta全部删除;
EXTERNAL:外部表
create EXTERNAL table ruozedata_emp_external
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double, deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION "/ruozedata/external/emp" ;
drop: drop meta;
外部表删除是只删除mysql中的meta,不删除hdfs中的数据,删除之后再创建一个表指到数据的位置,就可以获取数据了,内部表也可以通过指定LOCATION的方式,加载数据;
使用insert插入数据:
create table ruozedata_emp4 like ruozedata_emp;
INSERT OVERWRITE TABLE ruozedata_emp4
select * FROM ruozedata_emp;
关键是要插入数据与接受数据表的列数,参数类型要一致;int可以插入到string但是string不一定能插入int中;
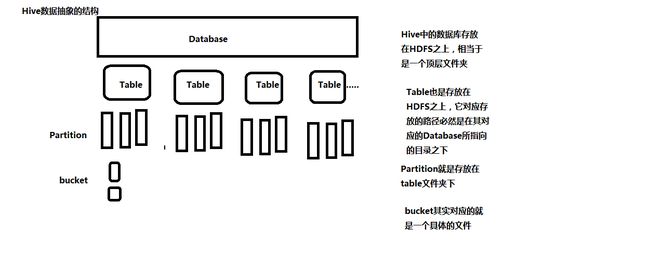
最后附一张hive数据结构图: