关键词:top、perf、sar、ksar、mpstat、uptime、vmstat、pidstat、time、cpustat、munin、htop、glances、atop、nmon、pcp-gui、collectl。
1. top
top是最常用的查看系统资源使用情况的工具,包括CPU、内存等等资源。
这里主要关注CPU资源。
1.1 /proc/loadavg
load average取自/proc/loadavg。
9.53 9.12 8.37 3/889 28165
前三个数字是1、5、15分钟内进程队列中平均进程数,包括正在运行的进程+准备好等待运行的进程。
第四个数字分子表示正在运行的进程数,分母是进程总数。
最后一个数字是最近运行的进程ID号。
其中top取的是/proc/loadavg的前三个数。
1.2 top使用
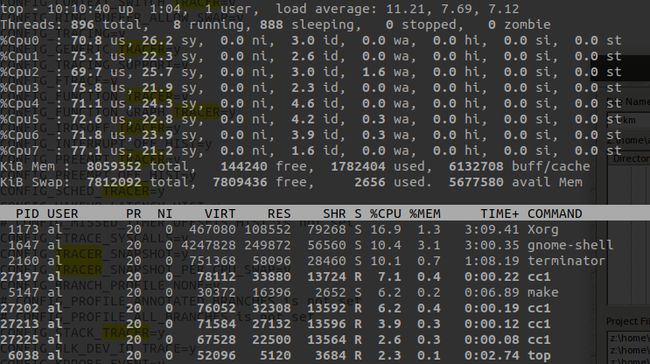
打开top,可以指定更新的周期。
输入H,打开隐藏的线程;输入1,可以显示单核CPU使用情况。
top -H -b -d 1 -n 200 > top.txt,每个1秒统计一次,共200次,显示线程细节,并保存到top.txt中。
top采样来源你还依赖于/proc/stat和/proc/
其中CPU信息对应的含义如下:
us是user的意思,统计nice小于等于0的用户空间进程,也即优先级为100~120。
ni是nice的意思,统计nice大于0的用户空间进程,也即优先级为121~139。
sys是system的意思,统计内核态运行时间,不包括中断。
id是idle的意思,几系统处于空闲态。
wa是iowait的意思,统计io等待时间。
hi是hardware interrupt,统计硬件中断时间。
si是software interrupt,统计软中断时间。
最后的st是steal的意思。
2. perf
《系统级性能分析工具perf的介绍与使用》有关于perf使用的详细介绍,这里重点关注CPU占用率。
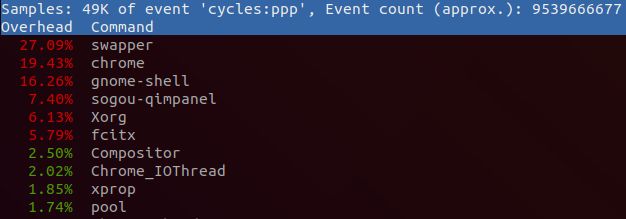
通过sudo perf top -s comm,可以查看当前系统运行进程占比。
这里不像top一样区分idle、system、user,这里的占比是各个进程在总运行时间里面占比。
通过sudo perf record记录采样信息,然后通过sudo perf report -s comm。
3. sar、ksar
sar是System Activity Report的意思,可以用于实时观察当前系统活动,也可以生成历史记录的报告。
要使用sar需要安装sudo apt install sysstat,然后对sysstat进行配置。
sar用于记录统计信息,ksar用于将记录的信息图形化输出。
ksar下载地址在:https://github.com/vlsi/ksar/releases。
sudo gedit /etc/default/sysstat--------------------------------将 ENABLED=“false“ 改为ENABLED=“true“。
sudo gedit /etc/cron.d/sysstat--------------------------------修改sar的周期等配置。
sudo /etc/init.d/sysstat restart--------------------------------重启sar服务
/var/log/sysstat/--------------------------------------------------sar log存放目录
使用sar记录开机到目前的统计信息到文件sar.txt。
LC_ALL=C sar -A > sar.txt
PS:这里直接使用sar -A,在ksar中无法正常显示。
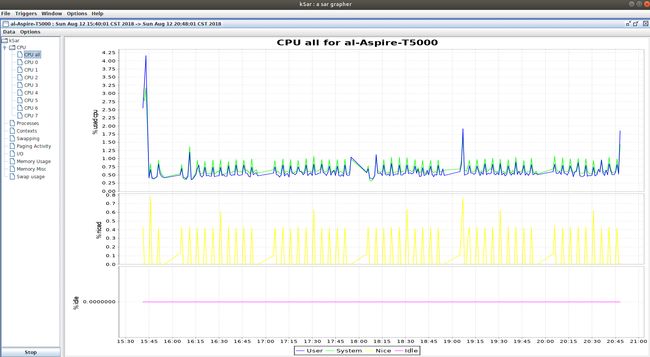
如下执行java -jar ksar.jar,然后Data->Load from text file...选择保存的sar.txt文件。
得到如下的图表。
还可以通过sar记录一段时间的信息,指定采样周期和采样次数。
这些命令前加上LC_ALL=C之后保存到文件中,都可以在ksar中图形化显示。
sar 1 100---------------------------------------所有cpu合一的统计信息
sar -P ALL 1 100-----------------------------包括cpu合一以及单个cpu的统计信息
sar -B 1 100-----------------------------------paging统计信息
sar -b 1 100----------------------------------块设备IO统计信息
sar -d 1 100----------------------------------块设备活动统计信息
sar -F 1 100---------------------------------挂载的文件系统统计信息
sar -r ALL------------------------------------显示详细的内存使用统计信息
sar -S----------------------------------------显示swap空间使用情况统计信息
sar -w---------------------------------------显示进程创建以及进程切换统计信息
sar -W--------------------------------------显示swap换入换出统计信息。
更详细请参考《How To Create sar Graphs With kSar To Identifying Linux Bottlenecks》、《Collect and report Linux System Activity Information with sar》。
4. mpstat
mpstat是Multiprocessor Statistics。当没有参数时,mpstat显示系统系统以来所有信息平均值。
常见用法如下,-P ALL监控所有CPU,细节显示特定CPU;10表示每10秒监控一次;20表示监控20次。
mpstat -P ALL 10 20
结果如下:
Linux 4.13.0-36-generic (xxx) 2018年08月13日 _x86_64_ (4 CPU)
11时01分09秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时01分19秒 all 3.44 6.26 5.15 0.13 0.00 0.20 0.00 0.00 0.00 84.82 11时01分19秒 0 3.09 13.46 3.29 0.00 0.00 0.10 0.00 0.00 0.00 80.06 11时01分19秒 1 4.41 3.11 5.02 0.00 0.00 0.60 0.00 0.00 0.00 86.86 11时01分19秒 2 2.96 0.20 9.29 0.00 0.00 0.10 0.00 0.00 0.00 87.45 11时01分19秒 3 3.32 7.95 3.12 0.50 0.00 0.00 0.00 0.00 0.00 85.11 11时01分19秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时01分29秒 all 3.65 6.09 5.08 0.00 0.00 0.25 0.00 0.00 0.00 84.93 11时01分29秒 0 3.92 11.07 4.63 0.00 0.00 0.20 0.00 0.00 0.00 80.18 11时01分29秒 1 4.39 1.90 3.49 0.00 0.00 0.80 0.00 0.00 0.00 89.42 11时01分29秒 2 3.35 0.10 10.14 0.00 0.00 0.00 0.00 0.00 0.00 86.41 11时01分29秒 3 2.91 11.26 2.21 0.00 0.00 0.00 0.00 0.00 0.00 83.62
usr表示用户空间进程,nice表示nice值大于0的用户空间进程。
sys是内核空间,iowait是I/O等待时间,irq是硬中断,soft是软中断,idle是空闲时间,guest和gnice都是虚拟机时间。
5. uptime
uptime是一个简单获取系统总共运行多长时间,以及最近1分钟、5分钟、15分钟的平均负载。
uptime通过/proc/uptime和/proc/loadavg获取相关信息。
up前是当前系统时间,up后是系统运行时长。
load average后是1分钟、5分钟、15分钟平均负载。
11:15:41 up 82 days, 20:34, 8 users, load average: 0.28, 0.40, 0.43
6. vmstat
vmstat主要用于监控系统内存使用情况的工具,但是也包含一些CPU相关信息。
使用方法vmstat 5 5表示运行5次,每次5秒。结果如下:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 472576 228688 559092 1061756 0 0 9 39 1 0 8 4 87 0 0 1 0 472576 228184 559100 1061756 0 0 0 13 1532 3395 10 6 84 0 0 1 0 472576 229308 559100 1061616 0 0 0 0 1446 3449 10 5 85 0 0 0 0 472576 229592 559108 1061616 0 0 0 6 1419 3474 10 5 85 0 0 1 0 472576 229804 559108 1061616 0 0 0 0 1446 3439 10 5 85 0 0
上面的参数可以分为6大部分:进程、内存、swap、io、中断和进程切换、cpu。
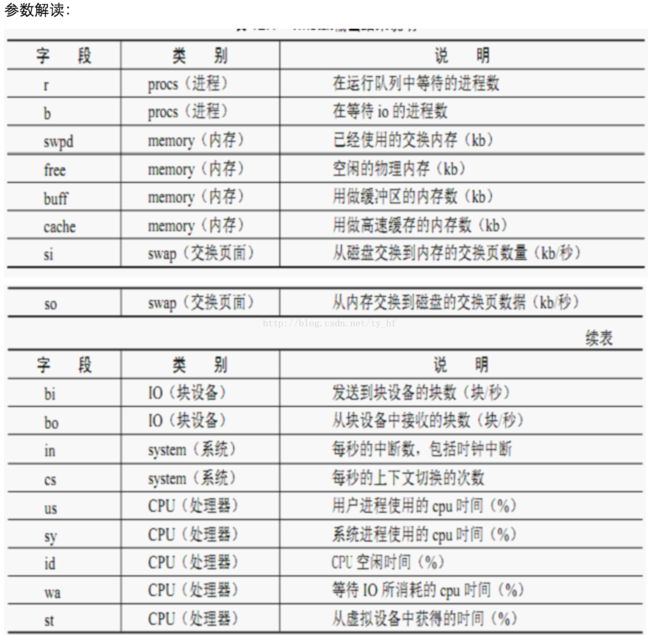
更加详细的解释:

参考文档:《Linux Performance Measurements using vmstat》
7. pidstat
pidstat主要用于监控全部或指定进程占用系统资源的情况。
7.1 查看CPU使用情况
pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
pidstat -p ALL---------------------------显示所有的进程统计信息,包括idle进程。
pidstat -p ALL -t------------------------更加详细的显示了线程统计信息。
pidstat [option] interval [count]-----周期采样和采样次数
除此之外还可以通过-p获取指定进程的统计信息。
pidstat还可以通过-r获取内存使用统计信息,通过-d获取IO使用统计信息。
7.2 查看内存使用情况
pidstat -p ALL -r结果如下:
15时18分21秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
15时18分21秒 0 1 0.02 0.00 185316 3028 0.08 systemd 15时18分21秒 0 2 0.00 0.00 0 0 0.00 kthreadd 15时18分21秒 0 4 0.00 0.00 0 0 0.00 kworker/0:0H 15时18分21秒 0 6 0.00 0.00 0 0 0.00 mm_percpu_wq 15时18分21秒 0 7 0.00 0.00 0 0 0.00 ksoftirqd/0 15时18分21秒 0 8 0.00 0.00 0 0 0.00 rcu_sched
minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数。
majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生。
VSZ: 该进程使用的虚拟内存(以kB为单位)。
RSS: 该进程使用的物理内存(以kB为单位)。
%MEM: 该进程使用内存的百分比。
Command: 拉起进程对应的命令。
7.3 查看磁盘使用情况
pidstat -p ALL -d结果如下:
15时20分40秒 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15时20分40秒 0 1 -1.00 -1.00 -1.00 243523129 systemd 15时20分40秒 0 2 -1.00 -1.00 -1.00 0 kthreadd 15时20分40秒 0 4 -1.00 -1.00 -1.00 0 kworker/0:0H 15时20分40秒 0 6 -1.00 -1.00 -1.00 0 mm_percpu_wq 15时20分40秒 0 7 -1.00 -1.00 -1.00 714512328679 ksoftirqd/0 15时20分40秒 0 8 -1.00 -1.00 -1.00 417757303594 rcu_sched
kB_rd/s: 每秒进程从磁盘读取的数据量(以kB为单位)。
kB_wr/s: 每秒进程向磁盘写的数据量(以kB为单位)。
kB_ccwr/s:每秒进程被取消向磁盘写的数据量(以kB为单位)。
Command: 拉起进程对应的命令。
8. time
time命令可以被用于统计指定程序的CPU耗时。
比如time cksum nomachine_6.0.80_1.exe得到如下结果。
2401940638 32606752 nomachine_6.0.80_1.exe
real 0m0.263s-----------------整个操作总耗时,0.263-0.094-0.011=0.158是IO等待耗时。
user 0m0.094s-----------------用户态耗时 sys 0m0.011s------------------内核态耗时 2401940638 32606752 nomachine_6.0.80_1.exe real 0m0.098s-----------------第二次执行就可以看出等待IO操作的时间基本上没有了。 user 0m0.097s sys 0m0.000s
9. cpustat
通过sudo apt install cpustat安装,cpustat -T -D -x结果如下。
Load Avg 0.66 0.54 0.49, Freq Avg. 1.46 GHz, 4 CPUs online------------------------------显示Load Avg信息和平均频率等。 3791.1 Ctxt/s, 1709.9 IRQ/s, 1800.0 softIRQ/s, 0.0 new tasks/s, 1 running, 0 blocked----进程切换次数、硬中断、软中断等等统计信息。 %CPU %USR %SYS PID S CPU Time Task-------------------------------------------CPU占用率、用户空间和内核空间占用率等。 25.74 25.74 0.00 11435 R 3 2.29w /usr/bin/python3 15.84 15.84 0.00 9445 S 0 1.49w /usr/lib/xorg/Xorg 10.89 9.90 0.99 2722 S 1 1.05w compiz 7.92 0.00 7.92 32352 S 2 16.60s [kworker/2:1] 0.99 0.00 0.99 32397 R 1 0.01s cpustat 0.99 0.99 0.00 11046 S 2 16.20h compiz 0.99 0.99 0.00 1317 S 0 8.76h /usr/NX/bin/nxnode.bin 0.99 0.00 0.99 10293 S 1 1.24m [kworker/1:2] 64.36 53.47 10.89 Total Load Avg 0.66 0.54 0.49, Freq Avg. 1.75 GHz, 4 CPUs online 2834.8 Ctxt/s, 1190.9 IRQ/s, 1183.3 softIRQ/s, 0.0 new tasks/s, 4 running, 0 blocked %CPU %USR %SYS PID S CPU Time Task 25.76 25.76 0.00 11435 R 3 2.29w /usr/bin/python3 18.18 18.18 0.00 9445 S 0 1.49w /usr/lib/xorg/Xorg 7.58 7.58 0.00 2722 S 1 1.05w compiz 6.06 0.00 6.06 32352 S 2 16.64s [kworker/2:1] 1.52 0.00 1.52 32397 R 1 0.02s cpustat 1.52 0.00 1.52 8 S 0 3.00h [rcu_sched] 1.52 0.00 1.52 18409 S 0 1.16m update-notifier 62.12 51.52 10.61 Total Distribution of CPU utilisation (per Task): % CPU Utilisation Count (%) 0.00 - 1.97 706 98.88 1.97 - 3.94 0 0.00 3.94 - 5.91 0 0.00 5.91 - 7.88 2 0.28 7.88 - 9.85 0 0.00 9.85 - 11.82 0 0.00 11.82 - 13.79 1 0.14 13.79 - 15.76 0 0.00 15.76 - 17.73 1 0.14 17.73 - 19.70 1 0.14 19.70 - 21.67 0 0.00 21.67 - 23.64 0 0.00 23.64 - 25.61 2 0.28 25.61 - 27.57 0 0.00 27.58 - 29.54 0 0.00 29.55 - 31.51 0 0.00 31.52 - 33.48 0 0.00 33.48 - 35.45 0 0.00 35.45 - 37.42 0 0.00 37.42 - 39.39 1 0.14 Distribution of CPU utilisation (per CPU):----------------------------------------------各CPU占用率,分用户空间和内核空间。 CPU# USR% SYS% 0 17.37 1.20 1 8.98 2.40 2 0.60 7.19