前言
HTTP 我打算阅读《HTTP权威指南》,并分章节做笔记。其中会漏掉我认为不是必要或者在那个章节还没有仔细说明的知识,因为感觉事无巨细的列出来是教科书的事。
第一章
第一章并没啥知识点
MIME : HTTP传送的数据一般会放在请求体中,而请求体是二进制的数据, 所以理论上能支持众多数据类型。HTTP 对这些类型做了分类,叫做 MIME (Multipurpose Internet Mail Extension). 应用程序如浏览器接受到一个数据时,就会根据不同的 MIME 做分别处理。
MIME 一般放在HTTP报文的首部中的 Content-type 中如 : Content-type: image/jpeg;
第二章 URL 与资源
URL 寻找信息所需的资源位置。
URL 的组成
URL一般有9个部分(一般用不了9个)
结构如下:
<协议>://<用户>:<密码>@<端口号>/<路径>;<参数>?<查询词>#<哈希值>
自行 google ,一个个的介绍说了也记不住。
URL 快捷方式
并不是每一个URL都需要严格的写满访问资源所需的全部信息。
这个知识点应该对爬虫程序也有帮助,因为工作的时候有个写爬虫的过来问我相关的知识
举个例子:
如果你在 www.baidu.com/xxx/xxx页面中有这样一个超链接
./bbb.html
这里的超链接地址是合法的。点击会发现页面跳转到 www.baidu.com/xxx/bbb.html 。这里的./bbb.html也是一个合法的 URL 。 这种 URL 叫做相对 URL 。但最后请求的 URL 也还是要是一个完整的URL吧。这就需要一套从相对 URL 到完整 URL 的规则。请看下面。
基础 URL : 既然是相对 URL ,那么相对谁呢,相对的 URL 就叫做基础 URL 。
还是上面 html 为例 (写前端的只知道这些。。)基础 URL 就是 www.baidu.com/xxx/bbb.html 全部,全部,全部。在html中有个显示改变基础 URL 的标签
生成绝对 URL 规则如图:
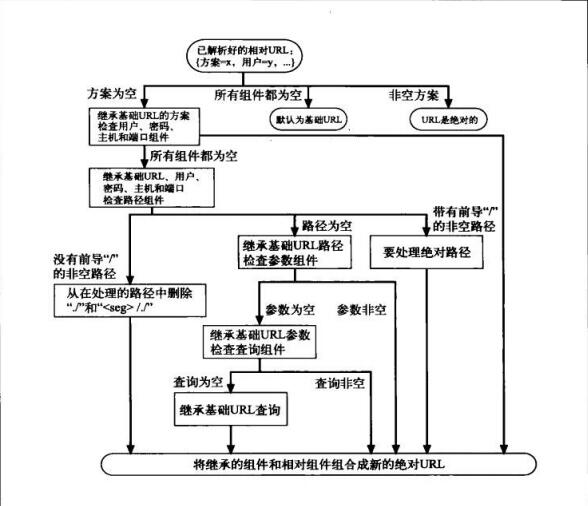
总结:
1.如果你的相对 URL 带协议的话,那这个就是最终的 URL 。
2.相对URL如果非空,且带前置 / ,如 '/hello',最终URL等于基础URL路径替换为相对URL之后的URL。如 相对URL 为 ‘/hello', 基础URL为 ‘www.baidu.com/balabala/balabla'. 那么最后生成 www.baidu.com/hello.
3.如果上两例都不是。那么就根据相对URL 缺少的部分与基础URL拼接。
如。 ‘./babba’与‘www.baidu.com/path/path2#afwe’ ,生成 www.baidu.com/path/babba.
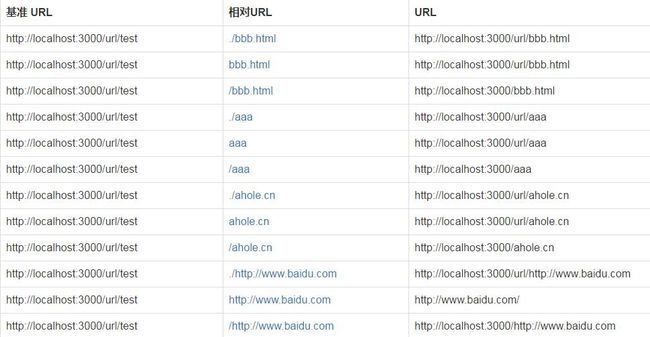
个人测试demo:
URL使用的编码
当你在 URL 输入框输入中文的时候,你可能发现你输入的中文会变%xx%xx的形式(如果没有,请按 F12 查看Network)。这说明URL只支持部分字符。
why ?
- 有部分协议只支持ASCII 码。如 SMTP
- URL 要求大家能看到,如果打入空格、换行符、甚至是一些不可见的字符如/u0000 ,从网络传输来讲这不算问题,但是对我们不太友好,毕竟看不见。所以URL也限制了协议字符。
那么问题来了
1.有时我们就需要用超过ASCII范文的字符,例如上例的搜索,难道我们要用http报文的请求体来发送数据吗,显然太麻烦,性能也不好。
2.还记得上面的篇幅中URL的格式吧,里面有‘/','?','#’这样的字符,如果我们就想发送这些字符呢?怎么能不混淆
how?
答案是转译。就是有一套规定把这些不合法的字符转化为另一个格式。
URL 的转译方法是使用 %% 的形式转换。
再细分两种,一种应对与符合编码的非法字符 ASCII 。
如 % -> 25(ASCII) -> %25;
超过ASCII范围的字符,因为用不同的编码有不同的结果,所以没有说法。但是思路还是一样的。以‘中‘使用Unicode为例子
中 -> 4E2D(Unicode) -> %4E%2D 。
非ASCII范围的具体使用哪种编码情况很多,可以参考 关于URL编码 - 阮一峰 ,但是个人感觉这种前后端约定好就行了,那可能考虑那么多。

结语
第二章结束,好像没啥知识点。