背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
本文将讨论memory reclaim内存回收这个话题。
在内存分配出现不足时,可以通过唤醒kswapd内核线程来异步回收,或者通过direct reclaim直接回收来处理。在针对不同的物理页会采取相应的回收策略,而页回收算法采用LRU(Least Recently Used)来选择物理页。
直奔主题吧。
2. LRU和pagevec
2.1 数据结构
简单来说,每个Node节点会维护一个lrvvec结构,该结构用于存放5种不同类型的LRU链表,在内存进行回收时,在LRU链表中检索最少使用的页面进行处理。
为了提高性能,每个CPU有5个struct pagevecs结构,存储一定数量的页面(14),最终一次性把这些页面加入到LRU链表中。
上述的描述不太直观,先看代码,后看图,一目了然!
typedef struct pglist_data {
...
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
...
}
/* 5种不同类型的LRU链表 */
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
struct lruvec {
struct list_head lists[NR_LRU_LISTS];
struct zone_reclaim_stat reclaim_stat; //与回收相关的统计数据
/* Evictions & activations on the inactive file list */
atomic_long_t inactive_age;
/* Refaults at the time of last reclaim cycle */
unsigned long refaults;
#ifdef CONFIG_MEMCG
struct pglist_data *pgdat;
#endif
/* 14 pointers + two long's align the pagevec structure to a power of two */
#define PAGEVEC_SIZE 14
struct pagevec {
unsigned long nr;
unsigned long cold;
struct page *pages[PAGEVEC_SIZE]; //存放14个page结构
};
/* 每个CPU定义5种类型 */
static DEFINE_PER_CPU(struct pagevec, lru_add_pvec);
static DEFINE_PER_CPU(struct pagevec, lru_rotate_pvecs);
static DEFINE_PER_CPU(struct pagevec, lru_deactivate_file_pvecs);
static DEFINE_PER_CPU(struct pagevec, lru_lazyfree_pvecs);
#ifdef CONFIG_SMP
static DEFINE_PER_CPU(struct pagevec, activate_page_pvecs);
#endif上述的数据结构,可以用下图来进行说明:

简单来说,在物理内存进行回收的时候可以选择两种方式:
- 直接回收,比如某些只读代码段等;
- 页面内容保存后再回收;
针对页面内容保存又分为两种情况:
swap支持的页,写入到swap分区后回收,包括进程堆栈段数据段等使用的匿名页,共享内存页等,swap区可以是一个磁盘分区,也可以是存储设备上的一个文件;- 存储设备支持的页,写入到
存储设备后回收,主要是针对文件操作,如果不是脏页就直接释放,否则需要先写回;
有上述这几种情况,便产生了5种LRU链表,其中ACTIVE和INACTIVE用于表示最近的访问频率,最终页面也是在这些链表间流转。UNEVITABLE,表示被锁定在内存中,不允许回收的物理页,比如像内核中大部分页框都不允许回收。
2.2 流程分析
看一下LRU链表的整体操作:
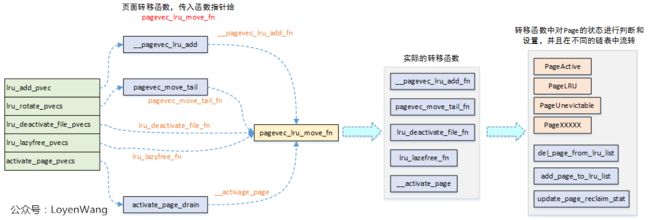
上图中,主要实现的功能就是将CPU缓存的页面,转移到lruvec链表中,而在转移过程中,最终会调用pagevec_lru_move_fn函数,实际的转移函数是传递给pagevec_lru_move_fn的函数指针。在这些具体的转移函数中,会对Page结构状态位进行判断,清零,设置等处理,并最终调用del_page_from_lru_list/add_page_to_lru_list接口来从一个链表中删除,并加入到另一个链表中。
首先看看图中最右侧部分中,关于Page状态,在内核中include/linux/page-flags.h中有描述,罗列关键字段如下:
enum pageflags {
PG_locked, /* Page is locked. Don't touch. */
PG_referenced, //最近是否被访问
PG_dirty, //脏页
PG_lru, //处于LRU链表中
PG_active, //活动页
PG_swapbacked, /* Page is backed by RAM/swap */
PG_unevictable, /* Page is "unevictable" */
} 针对这些状态在该头文件中还有一系列的宏来判断和设置等处理,罗列几个如下:
ClearPageActive(page);
ClearPageReferenced(page);
SetPageReclaim(page);
PageWriteback(page);
PageLRU(page);
PageUnevictable(page);
...上述的每个CPU5种缓存struct pagevec,基本描述了LRU链表的几种操作:
lru_add_pvec:缓存不属于LRU链表的页,新加入的页;lru_rotate_pvecs:缓存已经在INACTIVE LRU链表中的非活动页,将这些页添加到INACTIVE LRU链表的尾部;lru_deactivate_pvecs:缓存已经在ACTIVE LRU链表中的页,清除掉PG_activate, PG_referenced标志后,将这些页加入到INACTIVE LRU链表中;lru_lazyfree_pvecs:缓存匿名页,清除掉PG_activate, PG_referenced, PG_swapbacked标志后,将这些页加入到LRU_INACTIVE_FILE链表中;activate_page_pvecs:将LRU中的页加入到ACTIVE LRU链表中;
分析一个典型的流程吧,看看缓存中的页是如何加入到lruvec的LRU链表中,对应到图中的执行流为:pagevec_lru_add --> pagevec_lru_move_fn --> __pagevec_lru_add_fn,分别看看这三个函数,代码简单直接附上:
/*
* Add the passed pages to the LRU, then drop the caller's refcount
* on them. Reinitialises the caller's pagevec.
*/
void __pagevec_lru_add(struct pagevec *pvec)
{
//直接调用pagevec_lru_move_fn函数,并传入转移函数指针
pagevec_lru_move_fn(pvec, __pagevec_lru_add_fn, NULL);
}
EXPORT_SYMBOL(__pagevec_lru_add);
static void pagevec_lru_move_fn(struct pagevec *pvec,
void (*move_fn)(struct page *page, struct lruvec *lruvec, void *arg),
void *arg)
{
int i;
struct pglist_data *pgdat = NULL;
struct lruvec *lruvec;
unsigned long flags = 0;
//遍历缓存中的所有页
for (i = 0; i < pagevec_count(pvec); i++) {
struct page *page = pvec->pages[i];
struct pglist_data *pagepgdat = page_pgdat(page);
//判断是否为同一个node,同一个node不需要加锁,否则需要加锁处理
if (pagepgdat != pgdat) {
if (pgdat)
spin_unlock_irqrestore(&pgdat->lru_lock, flags);
pgdat = pagepgdat;
spin_lock_irqsave(&pgdat->lru_lock, flags);
}
//找到目标lruvec,最终页转移到该结构中的LRU链表中
lruvec = mem_cgroup_page_lruvec(page, pgdat);
(*move_fn)(page, lruvec, arg); //根据传入的函数进行回调
}
if (pgdat)
spin_unlock_irqrestore(&pgdat->lru_lock, flags);
//减少page的引用值,当引用值为0时,从LRU链表中移除页表并释放掉
release_pages(pvec->pages, pvec->nr, pvec->cold);
//重置pvec结构
pagevec_reinit(pvec);
}
static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec,
void *arg)
{
int file = page_is_file_cache(page);
int active = PageActive(page);
enum lru_list lru = page_lru(page);
VM_BUG_ON_PAGE(PageLRU(page), page);
//设置page的状态位,表示处于Active状态
SetPageLRU(page);
//加入到链表中
add_page_to_lru_list(page, lruvec, lru);
//更新lruvec中的reclaim_state统计信息
update_page_reclaim_stat(lruvec, file, active);
trace_mm_lru_insertion(page, lru);
}具体的分析在注释中标明了,其余4种缓存类型的迁移都大体类似,至于何时进行迁移以及策略,这个在下文中关于内存回收的进一步分析中再阐述。
正常情况下,LRU链表之间的转移是不需要的,只有在需要进行内存回收的时候,才需要去在ACTIVE和INACTIVE之间去操作。
进入具体的回收分析吧。
3. 页面回收
3.1 数据结构
与memory compact类似,页面回收也有一个与之相关的数据结构:struct scan_control
struct scan_control {
/* How many pages shrink_list() should reclaim */
unsigned long nr_to_reclaim;
/* This context's GFP mask */
gfp_t gfp_mask;
/* Allocation order */
int order;
/*
* Nodemask of nodes allowed by the caller. If NULL, all nodes
* are scanned.
*/
nodemask_t *nodemask;
/*
* The memory cgroup that hit its limit and as a result is the
* primary target of this reclaim invocation.
*/
struct mem_cgroup *target_mem_cgroup;
/* Scan (total_size >> priority) pages at once */
int priority;
/* The highest zone to isolate pages for reclaim from */
enum zone_type reclaim_idx;
/* Writepage batching in laptop mode; RECLAIM_WRITE */
unsigned int may_writepage:1;
/* Can mapped pages be reclaimed? */
unsigned int may_unmap:1;
/* Can pages be swapped as part of reclaim? */
unsigned int may_swap:1;
/*
* Cgroups are not reclaimed below their configured memory.low,
* unless we threaten to OOM. If any cgroups are skipped due to
* memory.low and nothing was reclaimed, go back for memory.low.
*/
unsigned int memcg_low_reclaim:1;
unsigned int memcg_low_skipped:1;
unsigned int hibernation_mode:1;
/* One of the zones is ready for compaction */
unsigned int compaction_ready:1;
/* Incremented by the number of inactive pages that were scanned */
unsigned long nr_scanned;
/* Number of pages freed so far during a call to shrink_zones() */
unsigned long nr_reclaimed;
};nr_to_reclaim:需要回收的页面数量;gfp_mask:申请分配的掩码,用户申请页面时可以通过设置标志来限制调用底层文件系统或不允许读写存储设备,最终传递给LRU处理;order:申请分配的阶数值,最终期望内存回收后能满足申请要求;nodemask:内存节点掩码,空指针则访问所有的节点;priority:扫描LRU链表的优先级,用于计算每次扫描页面的数量(total_size >> priority,初始值12),值越小,扫描的页面数越大,逐级增加扫描粒度;may_writepage:是否允许把修改过文件页写回存储设备;may_unmap:是否取消页面的映射并进行回收处理;may_swap:是否将匿名页交换到swap分区,并进行回收处理;nr_scanned:统计扫描过的非活动页面总数;nr_reclaimed:统计回收了的页面总数;
3.2 总体流程分析
与页面压缩类似,有两种方式来触发页面回收:
- 内存节点中的内存空闲页面低于
low watermark时,kswapd内核线程被唤醒,进行异步回收; - 在内存分配的时候,遇到内存不足,空闲页面低于
min watermark时,直接进行回收;
两种方式的调用流程如下图所示:

3.3 直接回收
__alloc_pages_slowpath
该函数调用_perform_reclaim来对页面进行回收处理后,再重新申请分配页面,如果第一次申请失败,将pcp缓存清空后再retry。__perform_reclaim
该函数中做了以下工作:
- 如果设置了
cpuset_memory_pressure_enabled,则先更新当前任务的cpuset频率表fmeter; - 将当前任务的标志置上
PF_MEMALLOC,防止递归调用页面回收例程; - 调用
try_to_free_pages来进行回收处理; - 恢复当前任务的标志;
try_to_free_pages
try_to_free_pages函数中,主要完成了以下工作:
- 初始化
struct scan_control sc结构; - 调用
throttle_direct_reclaim函数进行判断,该函数会对用户任务的直接回收请求进行限制; - 调用
do_try_to_free_pages进行回收处理;

再来看看throttle_direct_reclaim函数中调用的alloc_direct_reclaim:

只有throttle_direct_reclaim函数返回值为false,页面的回收才会进一步往下执行。
do_try_to_free_pages
- 通过
delayacct_freepages_start/delayacct_freepages_end量化页面回收的时间开销; - 随着回收优先级的调整,通过
vmpressure_prio来更新memory pressure值; - 循环调用
shrink_zones来回收页面,回收页面足够了或者可以进行内存压缩时,就会跳出循环不再进行回收处理;
3.4 异步回收
kswapd内核线程,当空闲页面低于watermark时会被唤醒,进行页面回收处理,balance_pgdat是回收的主函数,如下图:

异步回收线程和同步直接回收存进程在交互的地方:
- 在低水位情况下进程在直接回收时会唤醒
kswapd线程; - 异步回收时,
kswapd线程也会通过wake_up_all(&pgdat->pfmemalloc_wait)来唤醒等待在该队列上进行同步回收的进程;
kswapd内核线程会在内存节点达到平衡状态时,退出LRU链表的扫描。
3.5 shrink_node
前边铺垫了很多,真正的主角要上场了,不管是同步还是异步的回收,最终都落实在shrink_node函数上。

shrink_node的调用关系如上图所示,下边将针对关键函数进行分析。
get_scan_count
这个函数用于获取针对文件页和匿名页的扫描页面数。这个函数决定内存回收每次扫描多少页,匿名页和文件页分别是多少,比例如何分配等。
在函数的执行过程中,根据四种扫描平衡的方法标签来最终选择计算方式,四种扫描平衡标签如下:
enum scan_balance {
SCAN_EQUAL, // 计算出的扫描值按原样使用
SCAN_FRACT, // 将分数应用于计算的扫描值
SCAN_ANON, // 对于文件页LRU,将扫描次数更改为0
SCAN_FILE, // 对于匿名页LRU,将扫描次数更改为0
};来一张图:

shrink_node_memcg
shrink_node_memcg函数中,调用了get_scan_count函数之后,获取到了扫描页面的信息后,就开始进入主题对LRU链表进行扫描处理了。它会对匿名页和文件页做平衡处理,选择更合适的页面来进行回收。当回收的页面超过了目标页面数后,将停止对文件页和匿名页两者间LRU页面数少的那一方的扫描,并调整对页面数多的另一方的扫描速度。最后,如果不活跃页面少于活跃页面,则需要将活跃页面迁移到不活跃页面链表中。
来一张图:

shrink_list
在shrink_list函数中主要是从lruvec的链表中进行页面回收:
- 仅当活动页面数多于非活动页面数时才调用
shrink_active_list对活动链表处理; - 调用
shrink_inactive_list对非活动链表进行处理;
shrink_active_list
从函数的调用关系图中可以看出,shrink_active_list/shrink_inactive_list函数都调用了isolate_lru_pages函数,有必要先了解一下这个函数。
isolate_lru_pages函数,完成的工作就是从指定的lruvec中链表扫描目标数量的页面进行分离处理,并将分离的页面以链表形式返回。而在这个过程中,有些特殊页面不能进行分离处理时,会被rotate到LRU链表的头部。
shrink_active_list的整体效果图如下:

先对LRU ACTIVE链表做isolate操作,这部分操作会分离出来一部分页面,然后再对这些分离页面做进一步的判断,根据最近是否被referenced以及其它标志位做处理,基本上有四种去向:
1)rotate回原来的ACTIVE链表中;
2)处理成功移动到对应的UNACTIVE链表中;
3)不再使用返回Buddy系统;
4)如果出现了不可回收的情况(概率比较低),则放回LRU_UNEVICTABLE链表。
shrink_inactive_list
内存回收的最后一步就是处理LRU_UNACTIVE链表了,该写回存储设备的写回存储设备,该写到Swap分区的写到Swap分区,最终就是释放处理。
在提供最终效果图之前,先来分析一下shrink_page_list函数,它是shrink_inactive_list的核心。

从上图中可以看出,shrink_page_list函数执行完毕后,页面要不就是rotate回原来的LRU链表中了,要不就是进行回收并最终返回了Buddy System了。
所以,最终的shrink_inactive_list的效果如下图:

页面回收的模块还是挺复杂的,还有很多内容没有深入细扣,比如页面反向映射,memcg内存控制组等。
前前后后看了半个月时间的代码,就此收工。
下一个专题要开始看看SLUB内存分配器了,待续。
