背景
现在主流的数据库系统的故障恢复逻辑都是基于经典的ARIES协议,也就是基于undo日志+redo日志的来进行故障恢复。redo日志是物理日志,一般采用WAL(Write-Ahead-Logging)机制,所以也称redo日志为wal日志,redo日志记录了所有数据的变更,undo日志是逻辑日志,记录了所有操作的前镜像,方便异常时进行回滚。用户在提交事务时,只要确保写redo日志成功即可,并不需要对应的数据页也实时落盘,这套机制的基本思想是利用空间换时间,用户事务的更新实际上在数据页和redo日志中记录了两份,传统的数据库存储引擎都是基于B+Tree来组织数据页,因此刷数据页是离散小块IO,而写redo是顺序IO,对磁盘介质更友好,而且OLTP场景下,业务对RT(ResponseTime)也比较敏感,所以这套机制非常流行。
redo日志是保证数据不丢的关键因素,而且每个事务在提交时,都需要写redo日志,可想而知这块资源竞争是非常激烈的。这个问题是所有基于WAL机制的数据库系统个的共性问题,下文的讨论以MySQL为例,并以此说明MySQL8.0在这块的优化。
最初的redo日志机制
在MySQL的日志系统中,这里讨论的是InnoDB引擎,mtr(mini-transaction)是最小事务单位,一个用户事务会对应若干个mtr,mtr保证内部操作的原子性,比如B+Tree分裂操作,必需在一个mtr中。用户执行操作时,会同时更新数据页和写redo日志,mtr是redo日志的载体,存在每个会话的私有变量中。mtr提交时,会将本地redo日志拷贝到全局的log_buffer中,为了保证日志有序性,需要加锁来访问log_buffer,这把锁就是log_sys_t::mutex,所以这个锁竞争非常激烈。在这个锁保护下,除了要将本地日志拷贝到全局buffer,还需要将数据页加入了flush_list,供后台线程刷脏,辅助数据库检查点持续往前推进。检查点一方面能控制全局的redo日志文件大小,让日志具备循环复用的能力;另一方面,也能提高故障恢复速度。因为故障恢复的本质就是利用落盘的redo日志来恢复没有落盘的数据页。所以最开始(MySQL5.1)只有一把锁,大并发场景下,这个锁竞争非常激烈,MySQL在多核系统下也无法提升性能。
拆分log_sys_t::mutex
既然锁竞争压力大,那么最直观的想法就是拆锁。首先按功能拆分,刚刚说到,在mutex保护下,做了两件事,一件是拷贝本地日志到全局log_buffer;另一件事是将事务修改的page加入到flush_list。日志系统将这两件事解耦,引入了log_sys_t::flush_order_mutex,减少log_sys_t::mutex的持锁时间。将本地日志拷贝到log_buffer后,就可以释放log_sys_t::mutex,这样拷贝日志的线程和处理flush_list的线程就可以并发起来。
除了这个,日志系统还引入了双log_buffer机制,这个主要是为了解决全局log_buffer的读写并发问题。一个buffer用于拷贝日志到log_buffer,另一个log_buffer则用于读取,写入到日志文件。当需要读log_buffer时,则可以切换log_buffer的角色,这样就消除了写日志文件带来的访问log_buffer锁竞争。
但是,拆分完锁后,多个用户线程仍然需要在log_sys_t::mutex保护下,串行写log_buffer,由于memcpy操作比较重,所以这个锁竞争仍然非常激烈,需要优化。
消除log_sys_t::mutex
为了解决log_sys_t::mutex并发问题,MySQL 8.0引入了新的log_buffer机制,借助于lock_free的link_buf数据结构,利用原子变量来进行预占位,这样多个线程就能并发写redo,这种机制带来了一个空洞问题,因为写日志速度不一样,可能导致后占位(lsn较大)的线程先写完。但是我们写日志线程肯定是不能将带有空洞的buffer写到日志文件,因此会维护一个滑动窗口,即最小的连续的lsn:buf_ready_for_write_lsn。写日志线程会不断的检查 link_buf变量recent_written,然后写日志,推进buf_ready_for_write_lsn。
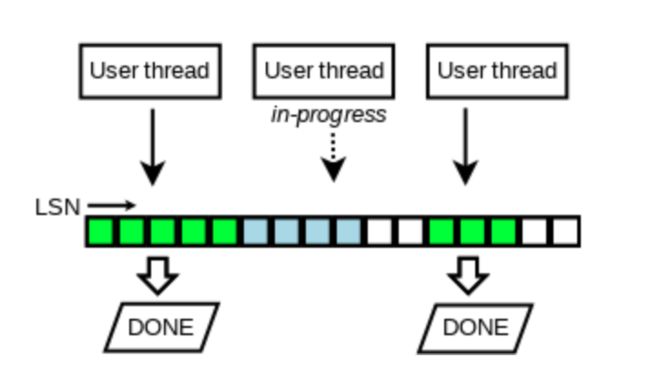
前面我们提到了系统中有两把锁,log_sys_t::mutex和log_sys_t::flush_order_mutex,通过占位方式,解决了写log_buffer的问题,那么如何解决将脏页有序加入到flush_list的问题呢?MySQL 8.0实现中仍然借助于link_buf数据结构,原来要求是加入flush_list的数据页的oldest_modification_lsn一定是递增的。这里顺便说下oldest_modification_lsn的含义,oldest_modification_lsn是指page第一次被修改后,mtr在log_sys_t中分配的lsn,即使这个page在flush下去之前,又在内存中被修改过N次,仍然以第一次修改的lsn为准,这样做的目的是,确保数据页内存的修改与检查点推进能对应上,避免检查点推进了,但对应的脏页可能还未刷盘,造成数据丢失问题。
由于是并发乱序写log_buffer,那么无法保证按lsn递增有序加入到flush_list,也就无法推进检查点。MySQL 8.0通过限制大于一定阀值L的lsn加入到flush_list做为权衡,假设当前flush_list的lsn最大值为M,那么只有在M值与当前线程lsn相差范围在L以内时,才将脏页写入flush_list。同样的,推进M,也依赖于link_buf变量recent_closed。这种策略本质上放宽了之前对于flush_list中对于LSN全局有序的限制到L范围内的有序。
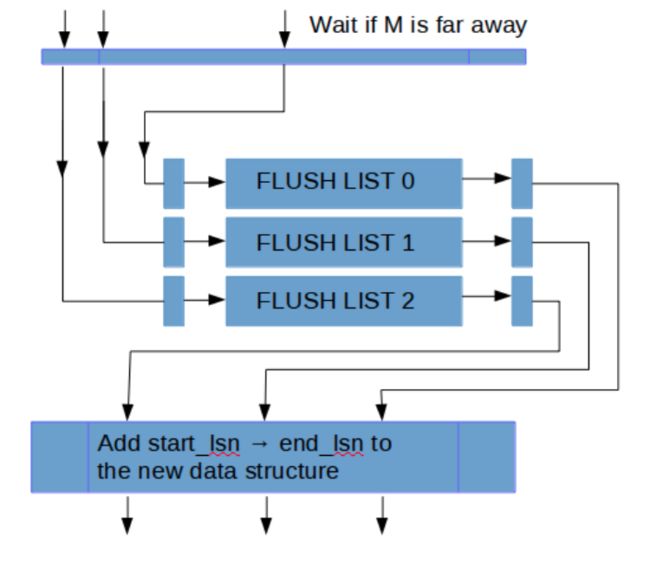
除了日志系统变成lock free,MySQL8.0还将写日志线程从用户线程中拆分出来,有单独的log writer线程和log flusher后台线程来处理写日志和sync日志。原来的写日志方式是,大家随机group-commit,由一个线程负责write/flush日志,其它线程等待,这种模式下group的大小比较随机。拆分后,处理更灵活,batch大小也更好控制,而且对于flush_log_at_trx_commit!=1的场景,只需要等log writer的通知即可。
总结
从MySQL日志系统优化的演进过程来看,始终是围绕锁log_sys_t::mutex展开。 从最初的按功能拆分出log_sys_t::flush_order_mutex,到按读写拆分实现为双log_buffer,以及最新的MySQL 8.0利用无锁机制彻底去掉这把锁,显然MySQL的并发能力是越来越强的。这种优化“套路”其实是比较朴素通用的,对于一个新的系统,通过一把大锁能简化并发逻辑,优先保证正确性。在系统慢慢演进过程中,我们可以按功能拆分锁,缓解锁冲突压力;如果某把锁处于核心链路,而且又成为瓶颈,那么再想办法继续拆,或者实现为无锁,彻底解决并发冲突问题,目的只有一个就是充分利用多核CPU资源,然线程多干活,减少响应时间的同时,拉高吞吐量,而不是都等待空闲着。文章中并没有涉及更多关于MySQL8.0日志系统优化的细节,官方文档已经写地足够好,大家可以详细看看。
参考文档
https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/
http://mysql.taobao.org/monthly/2018/07/01/
https://yq.aliyun.com/articles/592215?utm_content=m_49932