需求
由于安卓手机的配置不尽相同,在公司推出安卓版360度全景相机 Insta360 Air 后,客服经常会收到来电,询问其手机型号是否适用该产品。大部分情况下顾客只知道自己的手机型号,却不知道其详细参数,这让客服的工作量大大增加。于是客服主管希望能把ZOL 中关村在线里的所有安卓系统的手机型号和其对应的参数通过爬虫搜集下来,做成Excel表格方便以后随时随地检索手机参数。
分析
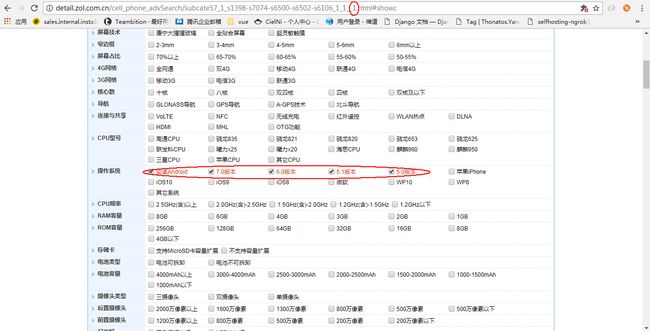
在选择限定的操作系统条件后,得到该url,经过测试发现,url最后下划线后面的数为页码。不过,手机列表的参数信息是不完整的,点击更多参数可以得到每个手机型号的详细参数信息,所以我们应该存下每个手机型号更多参数页面的url。
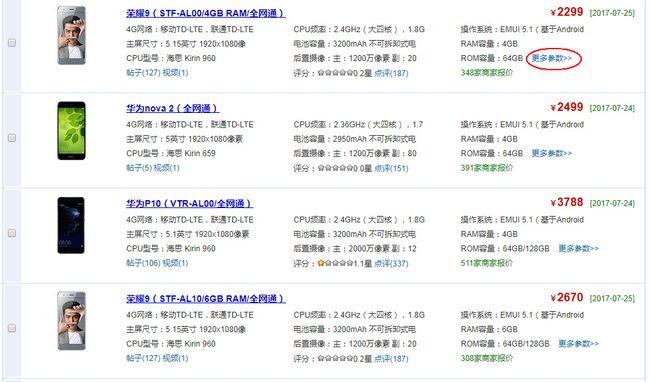
针对每一个型号的手机,访问其参数详情页进行参数采集。
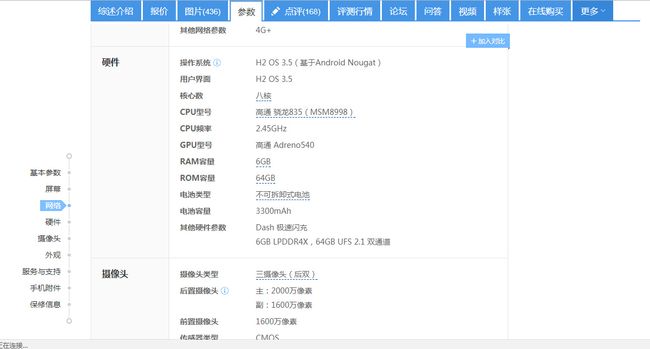
关于如何选用何种方式进行爬虫采集。由于ZOL中关村在线的手机信息数据都是在请求url时就同步返回给浏览器的,不存在js异步加载的问题,所以我们可以直接用urllib2库或者requests来请求url获取网页信息。由于网页信息比较复杂,我们需要 Beautiful Soup 来帮助我们解析html页面,获取参数信息。(Beautiful Soup教程)
实现
下面通过代码加注释来介绍具体的操作步骤,在这之前希望大家已经看过上面的Beautiful Soup教程,对Beautiful Soup的使用方法有一定了解。
# -*- coding: UTF-8 -*-
import sys
import urllib2
import re
import xlwt
import time
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding("utf-8")
def getValue(res, key):
try:
result = res[key]
except:
result = ''
return result
#存放手机参数详情页面的列表
link_list = []
base_url = 'http://detail.zol.com.cn/cell_phone_advSearch/subcate57_1_s1398-s7074-s6500-s6502-s6106_1_1__'
#控制页面数
for i in range(1, 145):
url = base_url + str(i) + '.html#showc'
response = urllib2.urlopen(url)
page = response.read()
soup = BeautifulSoup(page, 'html.parser')
ul = soup.find('ul', class_='result_list')
print url
temp = ul.find_all('a', text='更多参数>>')
for link in temp:
link_list.append('http://detail.zol.com.cn' + link['href']) #把每个手机型号的参数详情页存进数组
res_list = []
for url in link_list:
response = urllib2.urlopen(url)
page = response.read()
#使用beautiful soup解析html页面,page是字符串
soup = BeautifulSoup(page, 'html.parser')
result = {}
#去掉多余的br,br有可能会导致BeautifulSoup解析出错
for linebreak in soup.find_all('br'):
linebreak.extract()
#使用Beautiful Soup提供的方法定位我们想要得到的参数信息
div = soup.find('div',class_='breadcrumb')
a_list = div.find_all('a')
brand = a_list[2].string
model = a_list[3].string
result['brand'] = brand
result['model'] = model
th = soup.find('th',text='硬件')
tr = th.parent
list = tr.find('ul',class_='category-param-list').find_all('li')
for li in list:
spans = li.find_all('span')
key = spans[0].string
value = spans[1].string
# print spans[1]
if value == None:
value = ''
temp = spans[1].stripped_strings
for i in temp:
value += i + ','
# print key,value
result[key] = value
try:
system = result[u'操作系统']
if 'Android' in system:
pattern = re.compile("Android.{0,}", re.S)
items = re.findall(pattern, system)
try:
android = str(items[0])
except:
android = ''
else: android = ''
except:
android = ''
result['android'] = android
try:
span = soup.find('span',text='连接与共享')
temp = span.parent.find_all('span')[1]
hasOTG = 'OTG' in temp.strings
if hasOTG:
result['OTG'] = 'Y'
else:
result['OTG'] = 'N'
except:
result['OTG'] = 'N'
for key in result:
print key,result[key]
res_list.append(result)
#创建工作簿
workbook = xlwt.Workbook(encoding='utf8')
#创建sheet
sheet1 = workbook.add_sheet(u'手机参数表', cell_overwrite_ok=True)
row0 = [u'品牌', u'机型', u'是否支持OTG', u'安卓版本', u'操作系统', u'运行内存',
u'机身内存', u'扩展容量', u'CPU型号', u'GPU型号', u'CPU频率', u'存储卡', u'用户界面', u'电池容量', u'电池类型', u'核心数']
for i in range(0, len(row0)):
sheet1.write(0, i, row0[i])
row_index = 1
for res in res_list:
rows = [
getValue(res, 'brand'),
getValue(res, 'model'),
getValue(res, 'OTG'),
getValue(res, 'android'),
getValue(res, u'操作系统'),
getValue(res, u'RAM容量'),
getValue(res, u'ROM容量'),
getValue(res, u'扩展容量'),
getValue(res, u'CPU型号'),
getValue(res, u'GPU型号'),
getValue(res, u'CPU频率'),
getValue(res, u'存储卡'),
getValue(res, u'用户界面'),
getValue(res, u'电池容量'),
getValue(res, u'电池类型'),
getValue(res, u'核心数')
]
for i in range(len(rows)):
sheet1.write(row_index, i, rows[i])
row_index += 1
t = str(time.time())
workbook.save(t + '.xls') # 保存文件
Github地址: https://github.com/NiShuang/mobile_info_crawler
结果
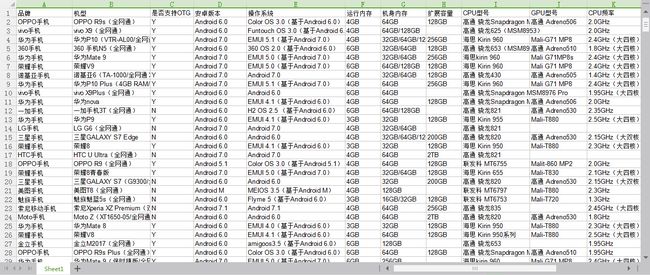
导出的Excel表格如下图所示:
文章标题:ZOL中关村在线手机参数爬虫
文章作者:Ciel Ni
文章链接:http://www.cielni.com/2017/07/28/zol-phone-crawler/
有问题或建议欢迎在我的博客讨论,转载或引用希望标明出处,感激不尽!