参考官方文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html#spider 学习笔记
安装
安装分别在ubunut和MAC系统下安装,过程如下:
ubuntu系统:
# 使用pip安装Scrapy
sudo pip install Scrapy
# 遇到报错,报哪个包没有,就是用pip安装哪个
MAC系统:
# 先确保已经安装 xcode
xcode-select --install
# 使用 pip 安装 Scrapy
sudo pip install Scrapy
# 遇到报错 关于six-1.4.1的,无法升级到新的版本。如下两种解决办法:
1、 sudo pip install scrapy --ignore-installed six # 跳过
2、 sudo easy_install "six>=1.5.2" # 使用easy_install 升级six。然后安装
创建项目:
$ scrapy startproject tutorial # 创建项目
$ cd tutorial/ ; tree # 进入到目录,并展示目录结构
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py # 保存爬去到的数据的容器,继承 scrapy.Item 类
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
└── dmoz_spider.py # 该文件为自己创建,继承 scrapy.Spider 类。定义属性:
# name(唯一,区别spider)
# start_urls(spider启动时进行爬去的列表,第一个被获取到
的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提
取)
# pasrse() 方法,被调用时,每个初始URL完成下载后生成的
Response 对象将会作为唯一的参数传递给该函数。 该方法负责解
析返回的数据(response data),提取数据(生成item)以及生成
需要进一步处理的URL的 Request 对象。
编写第一个爬虫
目的:获取url页面源码。(并未用到上边定义的Items)
创建一个spider,继承scrapy.Spider类,并定义一些属性:
-
name:用于区别Spider。 该名字必须是唯一的,不可以为不同的Spider设定相同的名字。 -
start_urls:包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取 -
parse():是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response(页面内容)对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
在tutorial/spiders目录中创建dmoz_spider.py,如下:
#coding=utf-8
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allow_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
#----- 从start_urls中读取页面源码信息,并写入本地---#
def parse(self,response):
# reponse.body 会输出请求url的源码,response.url 是所请求的 url 地址
# 通过下面的输出语句发现,start_urls 中的url地址的请求结果被分别带入到该方法中。
print "debug---------"
print response.body
print response.url
print "debug----------"
# 过滤出请求 url 地址的最后一段,并以该段的名字来创建文件,并写入对应的网页源码。
filename = response.url.split("/")[-2] + '.html'
with open(filename,"wb") as f:
f.write(response.body)
执行:
进入项目的根目录,执行下列命令启动spider
$ scrapy crawl dmoz
执行结果:在项目目录下,会生成两个文件,Books.html和Resources.html,文件内容分别是两个url页面的源码。
编写第二个项目(从选定的url地址中提取我们想要的信息)
定义Item
Item是保存爬取到的数据的容器。其使用方法和字典类似,虽然可以在Scrapy中直接使用dict,但是Item提供了额外保护机制来避免拼写错误导致的未定义字段错误。
编辑tutorial目录中的items.py文件,根据我们需要获取到的数据对item进行建模。下边分别定义了title、url和网站的描述。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
通过开发者工具对页面的源码进行分析,我们要提取的信息如下:
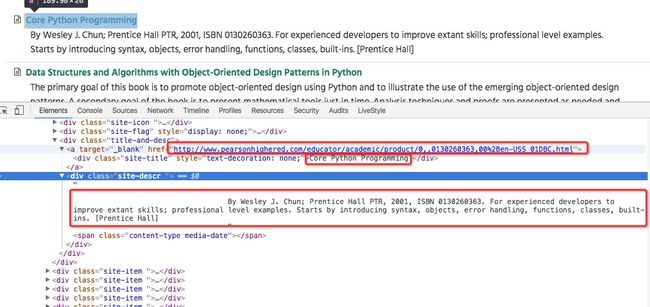
在tutorial/spiders目录中创建dmoz_spider.py,如下:
#coding=utf-8
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allow_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
# ----- 从start_urls中的页面源码中提取自己需要的,title、link、简介
def parse(self, response):
for sel in response.xpath('//*[@class="title-and-desc"]'):
# item 对象是自定义的 python 字典,可以使用标准的字典语法来获取到每个段子的值,字段就是之前在items.py文件中用Field赋值的属性。
item = DmozItem()
item['title'] = sel.xpath('a/div/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('div/text()').extract()
yield item
执行:
进入项目的根目录,执行下列命令启动spider
$ scrapy crawl dmoz
在输出的debug信息中,可以看到生成的items列表。更直观一点可以将items写入文件:
$ scrapy crawl dmoz -o items.json -t josn
# -o 指定文件名称 -t 指定格式
查看items.json内容:
$ cat items.json | head -n 5
[
{"title": ["eff-bot's Daily Python URL "], "link": ["http://www.pythonware.com/daily/"], "desc": ["\r\n\t\t\t\r\n Contains links to assorted resources from the Python universe, compiled by PythonWare.\r\n ", "\r\n "]},
{"title": ["O'Reilly Python Center "], "link": ["http://oreilly.com/python/"], "desc": ["\r\n\t\t\t\r\n Features Python books, resources, news and articles.\r\n ", "\r\n "]},
{"title": ["Python Developer's Guide "], "link": ["https://www.python.org/dev/"], "desc": ["\r\n\t\t\t\r\n Resources for reporting bugs, accessing the Python source tree with CVS and taking part in the development of Python.\r\n ", "\r\n "]},
{"title": ["Social Bug "], "link": ["http://win32com.goermezer.de/"], "desc": ["\r\n\t\t\t\r\n Scripts, examples and news about Python programming for the Windows platform.\r\n ", "\r\n "]}
追踪链接项目
上边两个项目,url地址都是直接给出,现在需要将一个页面中的url地址提取出来,并依次进行处理。
取http://www.dmoz.org/Computers/Programming/Languages/Python/中Related categories部分的url地址。如图:
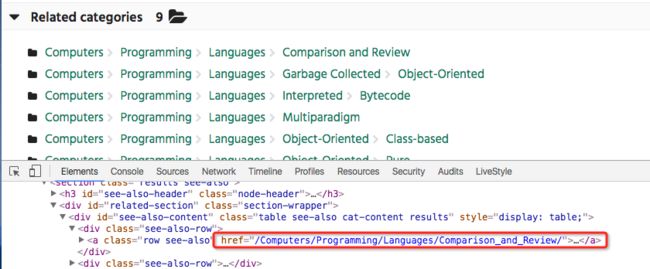
更改tutorial/items.py文件,加入fromurl,来表明这个信息来自哪个链接。如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DmozItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
fromurl = scrapy.Field()
在tutorial/spiders目录中创建dmoz_spider.py,如下:
#coding=utf-8
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allow_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/"
]
# ----- 追踪链接----#
def parse(self, response):
# 提取需要爬取的链接,产生(yield)一个请求, 该请求使用 parse_dir_contents() 方法作为回调函数, 用于最终产生我们想要的数据.。
print response.url
for link in response.xpath('//div[@class="see-also-row"]/a/@href'):
url = response.urljoin(link.extract())
yield scrapy.Request(url,callback=self.parse_dir_contents)
def parse_dir_contents(self,response):
# 提取信息,放入item中。这边增加了一个fromurl,所以在items.py 文件中,也要加入。
for sel in response.xpath('//*[@class="title-and-desc"]'):
item = DmozItem()
item['title'] = sel.xpath('a/div/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['fromurl'] = response.url
item['desc'] = sel.xpath('div/text()').extract()
yield item
执行:
进入项目的根目录,执行下列命令启动spider
$ scrapy crawl dmoz -o items1.json -t josn
查看items1.json内容:
cat items2.json | head -n 5
[
{"link": ["http://en.wikipedia.org/wiki/Bytecode"], "title": ["Bytecode "], "fromurl": "http://www.dmoz.org/Computers/Programming/Languages/Interpreted/Bytecode/", "desc": ["\r\n\t\t\t\r\n Growing article, with links to many related topics. [Wikipedia, open content, GNU FDL]\r\n ", "\r\n "]},
{"link": ["http://www.parrotcode.org/"], "title": ["Parrotcode "], "fromurl": "http://www.dmoz.org/Computers/Programming/Languages/Interpreted/Bytecode/", "desc": ["\r\n\t\t\t\r\n Home of Parrot Virtual Machine, made for dynamic languages, originally a target for Perl 6 compiler, hosts many language implementations in varied stages of completion: Tcl, Javascript, Ruby, Lua, Scheme, PHP, Python, Perl 6, APL, .NET. Open source.\r\n ", "\r\n "]},
{"link": ["http://vvm.lip6.fr/"], "title": ["Virtual Virtual Machine "], "fromurl": "http://www.dmoz.org/Computers/Programming/Languages/Interpreted/Bytecode/", "desc": ["\r\n\t\t\t\r\n VVM overview, history, members, projects, realizations, publications.\r\n ", "\r\n "]},
{"link": ["http://os.inf.tu-dresden.de/L4/l3elan.html"], "title": ["ELAN "], "fromurl": "http://www.dmoz.org/Computers/Programming/Languages/Multiparadigm/", "desc": ["\r\n\t\t\t\r\n Created 1974 by Technical University of Berlin group, as alternative to BASIC in teaching, for systematic programming, and related styles: top-down, bottom-up, recursive, modular, syntax-directed. Descriptions, brief resource list, documents. English, Deutsch.\r\n ", "\r\n "]},