引入
Java提供了种类丰富的锁,每种锁因其特性的不同,在适当的场景下能够展现出非常高的效率。
下面先带大家来总体预览一下锁的分类图


java锁的具体实现类
1、乐观锁 VS 悲观锁
乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在Java和数据库中都有此概念对应的实际应用。
先说概念。对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java中,synchronized关键字和Lock的实现类都是悲观锁。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。
乐观锁在Java中是通过使用无锁编程来实现,最常采用的是CAS算法,Java原子类中的递增操作就通过CAS自旋实现的。

上面提到了CAS,关于CAS的详细介绍,请参考这篇博客深入浅出CAS
2. 自旋锁 VS 适应性自旋锁
在介绍自旋锁前,我们需要介绍一些前提知识来帮助大家明白自旋锁的概念。
阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
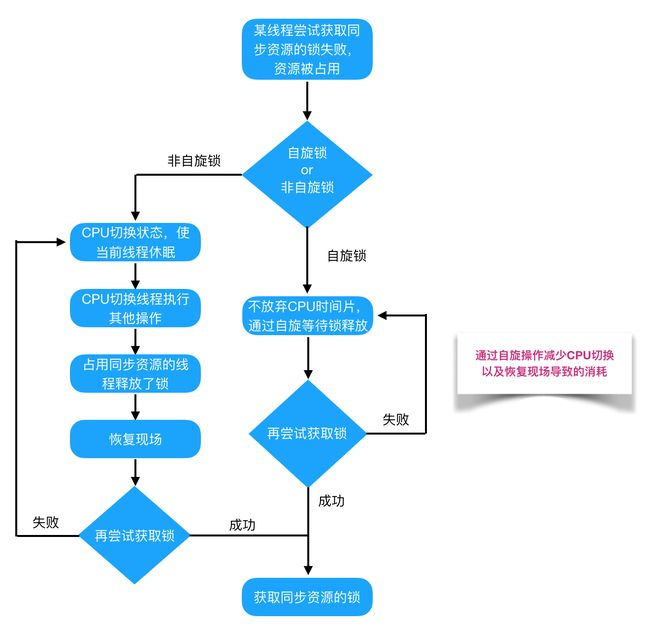
自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
自旋锁的实现原理同样也是CAS,AtomicInteger中调用unsafe进行自增操作的源码中的do-while循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
3. 公平锁 VS 非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。

如上图所示,假设有一口水井,有管理员看守,管理员有一把锁,只有拿到锁的人才能够打水,打完水要把锁还给管理员。每个过来打水的人都要管理员的允许并拿到锁之后才能去打水,如果前面有人正在打水,那么这个想要打水的人就必须排队。管理员会查看下一个要去打水的人是不是队伍里排最前面的人,如果是的话,才会给你锁让你去打水;如果你不是排第一的人,就必须去队尾排队,这就是公平锁。
但是对于非公平锁,管理员对打水的人没有要求。即使等待队伍里有排队等待的人,但如果在上一个人刚打完水把锁还给管理员而且管理员还没有允许等待队伍里下一个人去打水时,刚好来了一个插队的人,这个插队的人是可以直接从管理员那里拿到锁去打水,不需要排队,原本排队等待的人只能继续等待。如下图所示:

4. 可重入锁 VS 非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。下面用示例代码来进行分析:
public class Widget {
public synchronized void doSomething() {
System.out.println("方法1执行...");
doOthers();
}
public synchronized void doOthers() {
System.out.println("方法2执行...");
}
}
在上面的代码中,类中的两个方法都是被内置锁synchronized修饰的,doSomething()方法中调用doOthers()方法。因为内置锁是可重入的,所以同一个线程在调用doOthers()时可以直接获得当前对象的锁,进入doOthers()进行操作。
如果是一个不可重入锁,那么当前线程在调用doOthers()之前需要将执行doSomething()时获取当前对象的锁释放掉,实际上该对象锁已被当前线程所持有,且无法释放。所以此时会出现死锁。
而为什么可重入锁就可以在嵌套调用时可以自动获得锁呢?我们通过图示和源码来分别解析一下。
还是打水的例子,有多个人在排队打水,此时管理员允许锁和同一个人的多个水桶绑定。这个人用多个水桶打水时,第一个水桶和锁绑定并打完水之后,第二个水桶也可以直接和锁绑定并开始打水,所有的水桶都打完水之后打水人才会将锁还给管理员。这个人的所有打水流程都能够成功执行,后续等待的人也能够打到水。这就是可重入锁。

但如果是非可重入锁的话,此时管理员只允许锁和同一个人的一个水桶绑定。第一个水桶和锁绑定打完水之后并不会释放锁,导致第二个水桶不能和锁绑定也无法打水。当前线程出现死锁,整个等待队列中的所有线程都无法被唤醒。

之前我们说过ReentrantLock和synchronized都是重入锁,那么我们通过重入锁ReentrantLock以及非可重入锁NonReentrantLock的源码来对比分析一下为什么非可重入锁在重复调用同步资源时会出现死锁。
首先ReentrantLock和NonReentrantLock都继承父类AQS,其父类AQS中维护了一个同步状态status来计数重入次数,status初始值为0。
当线程尝试获取锁时,可重入锁先尝试获取并更新status值,如果status == 0表示没有其他线程在执行同步代码,则把status置为1,当前线程开始执行。如果status != 0,则判断当前线程是否是获取到这个锁的线程,如果是的话执行status+1,且当前线程可以再次获取锁。而非可重入锁是直接去获取并尝试更新当前status的值,如果status != 0的话会导致其获取锁失败,当前线程阻塞。
释放锁时,可重入锁同样先获取当前status的值,在当前线程是持有锁的线程的前提下。如果status-1 == 0,则表示当前线程所有重复获取锁的操作都已经执行完毕,然后该线程才会真正释放锁。而非可重入锁则是在确定当前线程是持有锁的线程之后,直接将status置为0,将锁释放。

5. 独享锁 VS 共享锁
独享锁和共享锁同样是一种概念。我们先介绍一下具体的概念,然后通过ReentrantLock和ReentrantReadWriteLock的源码来介绍独享锁和共享锁。
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
下图为ReentrantReadWriteLock的部分源码:

我们看到ReentrantReadWriteLock有两把锁:ReadLock和WriteLock,由词知意,一个读锁一个写锁,合称“读写锁”。再进一步观察可以发现ReadLock和WriteLock是靠内部类Sync实现的锁。Sync是AQS的一个子类,这种结构在CountDownLatch、ReentrantLock、Semaphore里面也都存在。
在ReentrantReadWriteLock里面,读锁和写锁的锁主体都是Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以ReentrantReadWriteLock的并发性相比一般的互斥锁有了很大提升。
6. 分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
7.偏向锁/轻量级锁/重量级锁
这三种锁是指锁的状态,并且是针对Synchronized。在Java 5通过引入锁升级的机制来实现高效Synchronized。这三种锁的状态是通过对象监视器在对象头中的字段来表明的。
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。