1.论文相关
CVPR2018
2. 简要介绍
2.1 摘要
我们提出了一个概念简单、灵活、通用的小批量学习框架,在这个框架中,分类器必须学会识别新类,每个类只给出了几个示例。我们的方法称为关系网络(RN),是端到端的从零开始训练的。在元学习过程中,它学习一个深度距离度量来比较场景中的少量图像,每个图像都是为模拟小样本设置而设计的。经过训练后,RN能够通过计算查询图像与每个新类的几个实例之间的关系得分对新类的图像进行分类,而无需进一步更新网络。除了在小样本学习上提供改进的性能外,我们的框架也很容易扩展到零样本学习。在五个基准上进行的大量实验表明,我们的简单方法为这两个任务提供了一种统一而有效的方法。
2.2 相关工作
其中许多方法都使用元学习或学习来学习策略,从一组辅助任务(元学习、学习来学习)中提取一些可传递的知识,这有助于他们很好地学习目标少数射击问题,而不受应用深度mod时可能出现的过度拟合的影响。ELS到稀疏数据问题。
2.2.1 Learning to Fine-Tune
2.2.2 RNN Memory Based
2.2.3 Embedding and Metric Learning Approaches
3. 思想
3.1
Therefore contemporary approaches to few-shot learning often decompose training into an auxiliary meta learning phase where transferrable knowledge is learned in the form of good initial conditions [10], embeddings [36, 39] or optimisation
strategies [29]. The target few-shot learning problem is then learned by fine-tuning [10] with the learned optimisation strategy [29] or computed in a feed-forward pass[36, 39, 4, 32] without updating network weights.
因此,当代的小样本学习方法往往将训练分解为辅助元学习阶段,在该阶段,可传递的知识以良好的初始条件[10]、嵌入[36、39]或优化策略[29]的形式学习。然后,通过微调[10]和学习的优化策略[29]来学习目标少量放炮学习问题,或者在不更新网络权重的情况下,通过前馈传递[36、39、4、32]来计算目标少量放炮学习问题。零镜头学习也面临着相关的挑战。识别器是由一个单一的例子以类描述的形式训练的(C.F.,一次拍摄一个单一的例子图像),使得基于梯度的学习数据不足成为一个挑战。
3.2
具体地说,我们提出了一种双分支关系网络(RN),它通过学习将查询图像与少量带快照标记的样本图像进行比较来实现少镜头识别。首先,嵌入模块生成查询和训练图像的表示。然后,通过关系模块比较这些嵌入,确定它们是否来自匹配的类别。根据[39,36]定义了基于情景的策略,嵌入和关系模块是元学习的端到端,以支持fewshot学习。这可以看作是对[39,36]策略的扩展,包括一个可学习的非线性比较器,而不是一个固定的线性比较器。我们的方法优于以前的方法,但更简单(无RNN[39,32,29])和更快(无微调[29,10])。我们提出的策略也直接推广到零镜头学习。在这种情况下,示例分支嵌入一个单镜头类别描述,而不是一个示例训练图像,关系模块学习比较查询图像和类别描述嵌入。
总的来说,我们的贡献是提供一个干净的框架,优雅地包含了少量和零镜头学习。我们对四个基准的评估表明,它提供了全面的令人信服的性能,同时比其他选择更简单、更快。
4.方法
4.1 问题定义
我们考虑了少样本分类器学习的任务。形式上,我们有三个数据集:一个训练集、一个支持集和一个测试集。支持集和测试集共享相同的标签空间,但训练集有自己的标签空间,与支持/测试集不相交。如果支持集包含C个独一无二的类,每个唯一类有K个带标签的样本,则目标小样本问题称为“C-way K-shot”。
只使用支持集,原则上我们可以训练分类器,为测试集中的每个样本分配一个类标签。然而,由于支持集中缺少带标签的样本,这种分类器的性能通常不令人满意。因此,我们的目标是在训练集上进行元学习,以提取可迁移的知识,使我们能够在支持集上更好地进行小样本学习,从而更成功地对测试集进行分类。
一种有效的利用训练集的方法是通过基于一个小片段(episode)的训练模拟小样本的学习设置,如[39]所述。在每个训练迭代中,通过从训练集中随机选择C个类,每个类有K个带有标签的样本来形成一个样本集作为一个小片段,以及它们的剩余部分C类的样本用作查询集。此示例/查询集拆分旨在模拟测试时将遇到的支持/测试集。如果需要,可以使用支持集进一步微调从样本/查询集训练的模型。在这项工作中,我们采用了这种基于小片段(episode)的训练策略。在我们的小样本实验中(见第节4.1)我们考虑一个样本(one-shot,K=1,图1)和五个样本(five-shot,K=5)设置。我们还解决了第3.3节中解释的K=0的零样本学习情况。
4.2 模型
4.2.1 One-Shot
我们的关系网络(RN)由两个模块组成:嵌入模块和关系模块,如图1所示。在查询集Q中的样本和样本集S中的样本输入到嵌入模块,该嵌入模块产生特征图和。特征图和用算子结合。在这项工作中,我们假设是特征图在深度上的连接,尽管其他选择是可能的。
样本和查询的组合特征图被送入关系模块,最终生成一个范围为0到1的标量,表示和之间的相似性,称为关系得分(relation score)。因此,在C-way one-shot设置中,我们为一个查询输入和训练样本集示例之间的关系生成C个关系分数:


4.2.2 K-Shot
对于K-Shot,其中K>1,我们对每个训练类所有样本的嵌入模块输出进行元素求和,形成该类的特征图。这个池化类级别的特征图与上面的查询图像特征图结合在一起。因此,在one shot 或few shot设置中,一个查询的关系得分(relation scores)数总是C。
4.2.2.1目标函数
我们使用均方误差(MSE)损失(等式(2))来训练我们的模型,将关系分数回归到基本事实(ground truth):匹配对具有相似性1,不匹配对具有相似性0。

MSE的选择有些不标准。我们的问题似乎是标签空间{0,1}的分类问题。然而,从概念上讲,我们正在预测关系分数,这可以被视为回归问题,尽管对于基本事实(ground-truth),我们只能自动生成{0,1}目标。
4.3 零样本学习
零样本学习类似于单样本学习,其中一个数据用于定义要识别的每个类。但是,它不为每个训练类提供一个带有一张快照图像的支持集,而是为每个训练类包含一个语义类嵌入向量。修改我们的框架来处理零样本的情况很简单:由于支持集使用了不同形式的语义向量(例如:属性向量而不是图像),因此除了用于图像查询集的嵌入模块外,我们还使用了第二个异构嵌入模块。然后像以前一样应用关系网。因此,每个查询输入的关系分数为:

零样本学习的目标函数与小样本学习的目标函数相同。
4.4 网络结构
由于大多数的小样本学习模型使用四个卷积块来做嵌入模块[39,36],为了进行公平比较,我们遵循相同的架构设置,见图2。更具体地说,每个卷积块分别包含一个3×3卷积的64个滤波器(64×3×3)、一个批归一化(batch normalisation)和一个相对非线性(ReLU nonlinearity layer)层。前两个卷积块还包含2×2的最大池化层,而后两个卷积块不包含。我们这样做是因为我们需要输出特征图来在关系模块中进一步卷积层。关系模块由两个卷积块和两个完全连接的层组成。每个卷积块都是一个3×3卷积,64个滤波器,然后进行批量归一化、relu非线性(ReLU nonlinearity layer)和2×2最大池化。对于Omniglot和MiniImageNet,最后一个最大池化层的输出大小分别为和。两个完全连接的层分别为8维和1维。除了输出层是Sigmoid外,所有完全连接的层都是RELU,以便在合理范围内为我们的网络体系结构的所有版本生成关系分数。

零样本学习体系结构如图3所示。在这种体系结构中,DNN子网是一个预先在imagenet上训练的现有网络(例如,Inception or ResNet)。

5.实验
我们在两个相关任务上评估了我们的方法:Omniglot和MiniImagenet上的小样本分类,以及具有属性的动物(AwA)和Caltech-UCSD Birds-200-2011 (CUB)上的零样本分类。所有的实验都是基于pytorch[1]实现的。
5.1 小样本识别
设置:所有实验中的小样本学习使用Adam[19],初始学习率为,每100000个episodes退火一半(annealed by half)。我们的所有模型都是从零开始进行端到端训练的,没有额外的数据集。
基线(Baselines):我们将其与各种最先进的小样本识别基线进行比较,包括neural statistician
[8], Matching Nets with and without fine-tuning [39],MANN [32], Siamese Nets with Memory [18], Convolutional Siamese Nets [20], MAML [10], Meta Nets [27], Prototypical Nets [36] and Meta-Learner LSTM [29]。
5.1.1 Omniglot
数据集:Omniglot[23]包含来自50个不同字母的1623个字符(类)。每类班有不同的人写的20个样本。在[32、39、36]之后,我们通过对现有数据进行90、180和270度的旋转来增加新的类,并使用1200个原始类加上旋转来进行训练,剩下的423个类加上旋转来进行测试。所有输入图像的大小调整为28×28。
训练:对于每个训练集episode的C个样本类中的每个类, 除K个样本图像外,5-way 1-shot包含19个查询图像,5-way 5-shot包含15个查询图像,20-way 1-shot包含10个查询图像,20-way 5-shot包含5个查询图像。这意味着在一个训练集/小批量中有19×5+1×5=100个图像用于5-way 1-shot实验。
结果: 在[36]之后,我们通过从测试集中随机生成的1000多个episode的平均值计算了Omniglot上小样本分类精度。对于1-shot和5-shot实验,我们在测试期间分别为每个类批处理1个和5个查询图像进行评估。结果如表1所示。我们在所有实验设置下均获得了较高的平均精度和较低的标准偏差,但5-way 5-shot,我们的模型的精度比[10]低0.1%。尽管如此,许多备选方案的机械设备更加复杂[27,8],或者针对目标问题进行微调[10,39],但我们没有。
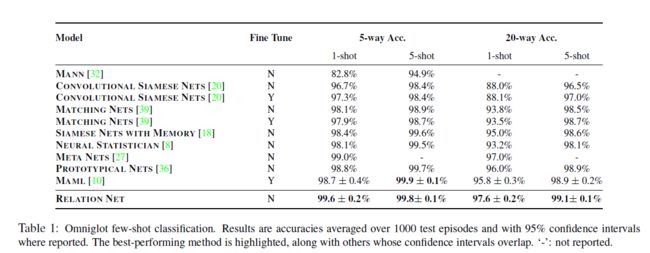
5.1.2 miniImageNet
数据集:MiniImageNet数据集最初由[39]提出,由60000张彩色图像组成,有100个类别,每个类别有600个示例。我们遵循了[29]引入的分割,分别有64、16和20个训练、验证和测试类。16个验证类仅用于监控泛化性能。
训练: 遵循目前多数小样本学习工作采用的标准设置,进行了5 way 1-shot和5 way 5-shot分类。对于每个训练集episode的C个样本类中的每个类, 除K个样本图像外,5-way 1-shot包含15个查询图像,5-way 5-shot包含10个查询图像。这意味着,例如,在一个训练集/小批中有15×5+1×5=80个图像用于5-way 1-shot实验。我们将输入图像的大小调整为84×84。我们的所有模型都是从零开始进行端到端训练的,随机初始化,没有额外的训练集。
结果: 像[36]一样,我们对每个episode每个类设置15张查询图像进行1-shot和5-shot场景的评估,通过对测试集随机生成的600多个episode进行平均,计算出小样本分类精度。
从表2可以看出,我们的模型在5 way 1-shot设置实现了最先进的性能,和5 way 5-shot上实现了有竞争力的结果。然而,原型网络[36]报告的1-shot测试结果要求每个训练episode训练30way15个查询图像,5-shot测试结果要求每个训练episode训练20way15个查询图像。当每个训练episode用5way15个查询图像训练时,[36]对于1-shot评估仅得到46.14±0.77%,明显弱于我们的。相比之下,每个训练episode,我们所有的模型都接受了5-way, 1 query for 1-shot、5 queries for 5-shot的培训,训练查询比[36]少得多。
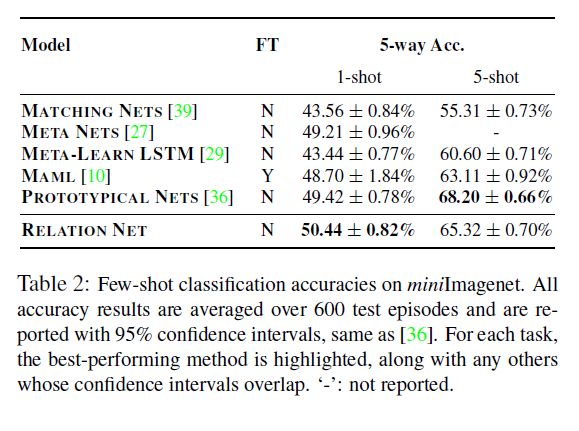
5.2 零样本识别
6. 启发
6.1
与以往工作的固定度量或固定特征和浅学习度量相比,关系网络可以看作是学习深度嵌入和学习深度非线性度量(相似函数)。这些都是端到端的相互调整,以便在短时间内相互支持。
为什么这会特别有用?通过使用一个灵活的函数逼近器来学习相似性,我们以数据驱动的方式学习一个好的度量,并且不必手动选择正确的度量(欧几里得、余弦、马哈拉诺比)。像[39,36]这样的固定指标假设特征只在元素方面进行比较,而最相关的[36]假设嵌入后的线性可分离性。因此,这些都严重依赖于所学嵌入网络的有效性,因此受到嵌入网络生成不充分的区分表示的程度的限制。相比之下,通过深度学习非线性相似度量和嵌入,关系网络能够更好地识别匹配/不匹配对。
6.2 可视化
(1)特征图和连接的方式改变,
参考资料
[1] 通过对比实现少样本或零样本学习Learning to Compare: Relation Network for Few-Shot Learning
[2] Learning to Compare: Relation Network for Few-Shot Learning论文笔记
[3] Learning to Compare: Relation Network for Few-Shot Learning 论文笔记
[4] karpathy/paper-notes
论文
[1] Learning to Compare: Relation Network for Few-Shot Learning
代码
[1] floodsung/LearningToCompare_FSL