【嵌牛导读】:卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,CNN模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一。
【嵌牛鼻子】:卷积神经网络
【嵌牛提问】:什么是CNN模型?
【嵌牛正文】:
自AlexNet一举夺ILSVRC 2012 ImageNet图像分类竞赛的冠军后,卷积神经网络(CNN)的热潮便席卷了整个计算机视觉领域。CNN模型火速替代了传统人工设计(hand-crafted)特征和分类器,不仅提供了一种端到端的处理方法,还大幅度地刷新了各个图像竞赛任务的精度,更甚者超越了人眼的精度(LFW人脸识别任务)。CNN模型在不断逼近计算机视觉任务的精度极限的同时,其深度和尺寸也在成倍增长。

表1 几种经典模型的尺寸,计算量和参数数量对比
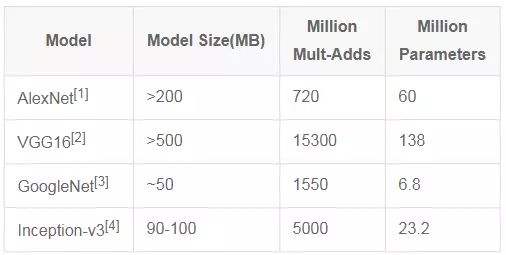
随之而来的是一个很尴尬的场景:如此巨大的模型只能在有限的平台下使用,根本无法移植到移动端和嵌入式芯片当中。就算想通过网络传输,但较高的带宽占用也让很多用户望而生畏。另一方面,大尺寸的模型也对设备功耗和运行速度带来了巨大的挑战。因此这样的模型距离实用还有一段距离。
在这样的情形下,模型小型化与加速成了亟待解决的问题。其实早期就有学者提出了一系列CNN模型压缩方法,包括权值剪值(prunning)和矩阵SVD分解等,但压缩率和效率还远不能令人满意。
近年来,关于模型小型化的算法从压缩角度上可以大致分为两类:从模型权重数值角度压缩和从网络架构角度压缩。另一方面,从兼顾计算速度方面,又可以划分为:仅压缩尺寸和压缩尺寸的同时提升速度。
本文主要讨论如下几篇代表性的文章和方法,包括SqueezeNet[5]、Deep Compression[6]、XNorNet[7]、Distilling[8]、MobileNet[9]和ShuffleNet[10],也可按照上述方法进行大致分类:
表2 几种经典压缩方法及对比

二、MobileNet
MobileNet是由Google提出的针对移动端部署的轻量级网络架构。考虑到移动端计算资源受限以及速度要求严苛,MobileNet引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,从而大大降低了卷积计算量,提升了移动端前向计算的速度。
1.1 卷积分解
MobileNet借鉴factorized convolution的思想,将普通卷积操作分成两部分:
Depthwise Convolution
每个卷积核滤波器只针对特定的输入通道进行卷积操作,如下图所示,其中M是输入通道数,DK是卷积核尺寸:

图 1 Depthwise Convolution[9]
Depthwise convolution的计算复杂度为 DKDKMDFDF,其中DF是卷积层输出的特征图的大小。
Pointwise Convolution
采用1x1大小的卷积核将depthwise convolution层的多通道输出进行结合,如下图,其中N是输出通道数:
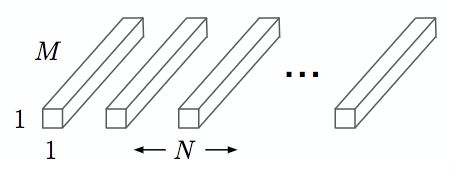
图2 Pointwise Convolution[9]
Pointwise Convolution的计算复杂度为 MNDFDF
上面两步合称depthwise separable convolution
标准卷积操作的计算复杂度为DKDKMNDFDF
因此,通过将标准卷积分解成两层卷积操作,可以计算出理论上的计算效率提升比例:
对于3x3尺寸的卷积核来说,depthwise separable convolution在理论上能带来约8~9倍的效率提升。
1.2 模型架构
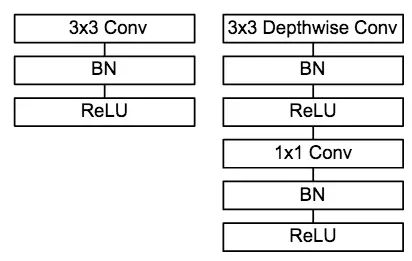
图3 普通卷积单元与MobileNet 卷积单元对比
MobileNet的卷积单元如上图所示,每个卷积操作后都接着一个BN操作和ReLU操作。在MobileNet中,由于3x3卷积核只应用在depthwise convolution中,因此95%的计算量都集中在pointwise convolution 中的1x1卷积中。而对于caffe等采用矩阵运算GEMM实现卷积的深度学习框架,1x1卷积无需进行im2col操作,因此可以直接利用矩阵运算加速库进行快速计算,从而提升了计算效率。
结果显示,MobileNet在保证精度不变的同时,能够有效地减少计算操作次数和参数量,使得在移动端实时前向计算成为可能。
二、ShuffleNet
ShuffleNet是Face++今年提出了一篇用于移动端前向部署的网络架构。ShuffleNet基于MobileNet的group思想,将卷积操作限制到特定的输入通道。而与之不同的是,ShuffleNet将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
2.1 设计思想
我们知道,卷积中的group操作能够大大减少卷积操作的计算次数,而这一改动带来了速度增益和性能维持在MobileNet等文章中也得到了验证。然而group操作所带来的另一个问题是:特定的滤波器仅对特定通道的输入进行作用,这就阻碍了通道之间的信息流传递,group数量越多,可以编码的信息就越丰富,但每个group的输入通道数量减少,因此可能造成单个卷积滤波器的退化,在一定程度上削弱了网络了表达能力。
2.2 网络架构
在此篇工作中,网络架构的设计主要有以下几个创新点:
提出了一个类似于ResNet的BottleNeck单元
借鉴ResNet的旁路分支思想,ShuffleNet也引入了类似的网络单元。不同的是,在stride=2的单元中,用concat操作代替了add操作,用average pooling代替了1x1stride=2的卷积操作,有效地减少了计算量和参数。
提出将1x1卷积采用group操作会得到更好的分类性能
在MobileNet中提过,1x1卷积的操作占据了约95%的计算量,所以作者将1x1也更改为group卷积,使得相比MobileNet的计算量大大减少。
提出了核心的shuffle操作将不同group中的通道进行打散,从而保证不同输入通道之间的信息传递。
ShuffleNet的shuffle操作如图11所示。

图 4 ShuffleNet网络单元[10]

图5 不同group间的shuffle操作[10]
结果显示,相比MobileNet,ShuffleNet的前向计算量不仅有效地得到了减少,而且分类错误率也有明显提升,验证了网络的可行性。
2.4 速度考量
作者在ARM平台上对网络效率进行了验证,鉴于内存读取和线程调度等因素,作者发现理论上4x的速度提升对应实际部署中约2.6x。
表9 ShuffleNet与AlexNet在ARM平台上速度对比 [10]
结束语
近几年来,除了学术界涌现的诸多CNN模型加速工作,工业界各大公司也推出了自己的移动端前向计算框架,如Google的Tensorflow、Facebook的caffe2以及苹果今年刚推出的CoreML。相信结合不断迭代优化的网络架构和不断发展的硬件计算加速技术,未来深度学习在移动端的部署将不会是一个难题。