目录:
实践1:基于autoscaling cpu指标的扩容与缩容
实践2:基于prometheus自定义指标QPS的扩容与缩容
Pod自动扩容/缩容(HPA)Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据资源利用率或者自定义指标自动调整replication controller, deployment 或 replica set,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
HPA主要是对pod资源的一个计算,对当前的副本数量增加或者减少。
HPA大概是这样的,我们需要创建一个hpa的规则,设置这样的一个规则对pod实现一个扩容或者缩容,主要针对deployment,当你当前设置的资源利用率超出你设置的预值,它会帮你扩容缩容这些副本。
1、HPA基本原理
Kubernetes 中的 Metrics Server 持续采集所有 Pod 副本的指标数据。HPA 控制器通过 Metrics Server 的 API(Heapster 的 API 或聚合 API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作。如图所示。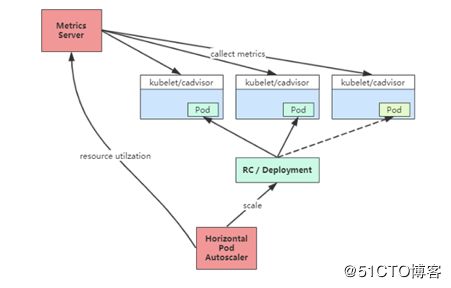
在弹性伸缩中,冷却周期是不能逃避的一个话题, 由于评估的度量标准是动态特性,副本的数量可能会不断波动。有时被称为颠簸, 所以在每次做出扩容缩容后,冷却时间是多少。
来看这张图,首先hpa要创建一个规则,就像我们之前创建ingress的规则一样,里面定义好一个扩容缩容的一个范围然后指定好对象,指定好它的预值,hpa本身就是一个控制器,循环的控制器,它会不断的从metrics server 中去获取这个指标,判断这个预值是不是到达你设置规则的预值,如果是的话,就会去执行这个scale帮你扩容这个副本,如果长期处于一个低使用率的情况下,它会帮你缩容这个副本,这个metrics server的资源来源是来自于cadvisor去拿的,想一下cadvisor可以提供那些指标,hpa可以拿到的,比如cpu,内存的使用率,主要采集你这些的利用率,所以hpa在早期已经支持了对CPU的弹性伸缩
Hpa就是k8s中这个pod水平扩容的一个控制器,但是要实现
Pod的扩容,他需要一定的条件,他要拿一定的指标,这里是有预值的,他要判断你的指标,是不是超出这个预值,对你进行缩容扩容,所以要想得到这个指标,你还需要装一个组件,metrics server,在之前呢这个组件的实现是由heapster heapstar现在已经是慢慢弃用了,基本上不怎么去使用heapstat了,所以metrics server来提供这些数据,提供这些资源的利用率。
比如有三个副本,来实现三个pod的伸缩,所以有东西去判定资源的利用率,比如基于cpu的,计算3个pod的资源利用率,例如3个pod的资源利用率是50%,拿到这个值之后,你就要去使用这个hpa,这个里面会定义个预值,有个规则,这个预值设置60%,它会周期性的与cpu去匹配,如果超出这个60%,那么就去扩容,这里还有定义扩容pod副本的数量
比如我这组pod的访问量是异常的,比如受到一些小***,我的cpu就超过50%,如果没有限制去最大扩容到多大的副本,它会无限的增大,之前3个副本可能一下就增加了10个副本,甚至50个,那么很快就能拖死整个集群,所以在hpa中都设置3个指标,第一个设置,pod的区间值,这个最大能扩容多少个pod,最小是多少个pod,比如1-10,最小可以创建1个,最大可以创建10个,这是一个缩容扩容的一个范围值,接下来就是一个预值的判断,第三个就是操作哪个对象,哪一组pod,这三个都是要在hpa中去判断的
那么在什么情况下,去缩容扩容
扩容就是资源不够了超过这个60%了,但是在这个区间它是由个状态转化的,一个是扩容的状态,一个是缩容的状态,这两个状态就好比现在的资源利用率60%了,进行扩容了,有3个副本就扩容到10个副本了,这是没问题的,然后马上这个值下来了,之前是到了70%-80%了,现在一下到了20%,从10直接缩容到5个,这两个是有状态转化的,所以hpa得基于保证说不可能状态转化的区间频率太高,如果太高就会出现好比时好时坏,间歇性的突发,并不是一直的突发,它会导致一会扩一会缩,最后导致这个应用不稳定,所以hpa就有一个冷却的机制,第一次扩容之后,第二次要想扩容必须经过这个冷却时间,那么默认是3分钟,缩容呢,第一次后,第二次缩容要等5分钟之后,这就是一个默认的一个值,来保障你当前业务的稳定性,是通过kube-controller-manager组件启动参数设置的
在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。
可以通过调整kube-controller-manager组件启动参数设置冷却时间:
• --horizontal-pod-autoscaler-downscale-delay :扩容冷却
• --horizontal-pod-autoscaler-upscale-delay :缩容冷却2、HPA的演进历程
目前 HPA 已经支持了 autoscaling/v1、autoscaling/v2beta1和autoscaling/v2beta2 三个大版本 。
目前大多数人比较熟悉是autoscaling/v1,这个版本只支持CPU一个指标的弹性伸缩。
这个也比较简单,创建一个规则,使用采集的组件就能用了,
而autoscaling/v2beta1增加了支持自定义指标,除了cadvisor暴露的指标外,还支持自定义指标,比如像第三方提供的QPS,或者基于其他的一些资源进行扩容,就是支持一些第三方的一些组件了。
autoscaling/v2beta2又额外增加了外部指标支持。
而产生这些变化不得不提的是Kubernetes社区对监控与监控指标的认识认识与转变。从早期Heapster到Metrics Server再到将指标边界进行划分,一直在丰富监控生态。
所以有这些指标的变化,k8s对监控的认识进行了转变,因为弹性伸缩,在k8s中含金量还是比较高的,之前是没有太好的方案,所以在这一块也不是应用很多,然后再到社区对这一块进行完善,现在应用的也逐渐增多了。
实例
V1版本就是一个cpu的一个限制,其实早期也会内存也进行开放,后期只针对cpu进行了限制,因为只暴露cpu,是因为暴露内存并不是使用弹性伸缩的一个指标,因为像一个内存都会有一些应用去管理,比如java,内存都是有一个jvm去管理,所以使用内存扩容的一个指标,并不是很好,所以只暴露了cpu的指标,cpu还是比较准确的,pod,cpu利用率上来之后,负载高了,流量高了,所以这块参考价值比较大的,所以只使用cpu,在这里指定一个百分比就行。
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50:v2beta2版本
就支持了很多的自定义的东西,比如resource,pods.object,external
可以根据cpu做一些pod暴露指标方面的工作,也可以针对第三方的一些指标,还有一些第三方的指标,像消息队列之类的,
V2支持的更多了
2.5 基于CPU指标缩放
1、 Kubernetes API Aggregation
在 Kubernetes 1.7 版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过 API Server 的 HTTP URL 对新的 API 进行访问和操作。为了实现这个机制,Kubernetes 在 kube-apiserver 服务中引入了一个 API 聚合层(API Aggregation Layer),用于将扩展 API 的访问请求转发到用户服务的功能。
要使用v1版本基于cpu指标缩放,首先要开启API的聚合,在k8s1.7版本中去引入的,它引入是想让第三方的应用程序注册进来,都能注册到api中,去访问这个api时就能调用这个组件了,这张图,首先api的聚合时从API server去启用的,上面当作API server ,下面当作组件,APIserver它本身就是以后端聚合层后面的,只不过它都在这个里面实现了,实际上apiserver在聚合层后面,可以把聚合层当作一个代理层,就像nginx代理web一样,代理的话就可以代理多个了,就不局限于apiserver了,像metrics server,自己开发的一个组件也能注册进来,然后让他代理,它代理之后就可以访问api,从而访问到这个组件了,那么聚合层就像请求的url帮你转发到后面的组件上,后面的组件都会对应api,根据注册到聚合层的api转发,简而言之就是扩展api的功能,就是方便自己开发的组件,集成到这个api里面,就像调用api一样调用你的组件,其实这就是一个聚合层的目的,在k8s中如果使用kubeadm部署的,默认的聚合层已经是启用了,如果是二进制的部署方式去部署的,那么要按二进制的方式去启动聚合层,这个根据自己的环境去启动,因为每个人部署的二进制都不一样。
需要在kube-APIServer中添加启动参数,增加以下配置:
vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \
--requestheader-allowed-names=kubernetes \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
...第一行指定的根证书,就是访问聚合层也要有一定的认证,不是谁的都能访问,本身也有一定的安全机制存在,也就是一个可信任的ca
第二,三行代理的是客户端的证书,大致的意思是放在聚合层进行认证的,来判断你是否有机制来访问
第四行的就是允许的名称,这个是提供的证书里面的,来判段这个名称是不是能够访问,这个我使用的是apiserver的证书,也可以使用ca单独为这个生成一个新的证书
第五行,请求头来判断是否可以访问
第六行,就是启动聚合层的路由
重启这个字段[root@k8s-master1 ~]# vim /opt/kubernetes/cfg/kube-apiserver.conf
将开始聚合层的配置添加进入
[root@k8s-master1 ~]# systemctl restart kube-apiserver
[root@k8s-master1 ~]# ps -ef |grep kube-apiserver2、部署 Metrics Server
Metrics Server是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。
Metric server从每个节点上Kubelet公开的摘要API收集指标。
Metrics server通过Kubernetes聚合器注册在Master APIServer中。
它必须能拿到cpu的利用率,有这个才能做对比,要不要扩容,所以要部署一个metrics server到集群中,让它为hpa提供CPU的数据查询,metrics server相当于一个聚合器,它那的数据就是cadvisor 的数据,它将那些数据每个节点的数据进行聚合,这是它说做的事,因为你要扩容,并不是一个副本去扩容,并不是参考一个副本的指标,要参考你当前跑的pod的都要考虑,而每个上面都有cadvisor,那访问当前的pod,就只访问到当前的利用率,而cadvisor也没有什么聚合的作用,要想对所有的pod的资源利用率做一个汇总,那么上面就有这个metrics server了,之前是有heapstar去做的,现在是由metrics server去做的,帮你去汇总,然后hpa从这个汇总信息里去拿整体cpu的利用率来判断这个域,所以metrics server就是一个聚合器,
而且还会从每个节点上kubelet收集这些指标,并通过k8s聚合器注册在k8s中的apiserver中,所以metrics必须启动聚合器,所以metrics就能主动的将自己注册进去,注册进去之后就可以metrics暴露的一个名称来请求metrics,会根据你携带的名称帮你转发到后面的metrics的pod
git clone https://github.com/kubernetes-incubator/metrics-server
cd metrics-server/deploy/1.8+/
vi metrics-server-deployment.yaml # 添加2条启动参数
...
containers:
- name: metrics-server
image: zhaocheng172/metrics-server-amd64:v0.3.1
command:
- /metrics-server
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
...确保pod起来
[root@k8s-master1 1.8+]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-59fb8d54d6-7rmx2 1/1 Running 0 43m
kube-flannel-ds-amd64-4jjmm 1/1 Running 0 43m
kube-flannel-ds-amd64-9f9vq 1/1 Running 0 43m
kube-flannel-ds-amd64-gcf9s 1/1 Running 0 43m
metrics-server-64499fd8c6-xkc6c 1/1 Running 0 61s部署起来先看看metrics-server有没有正常工作,先看一下pod有没有错误日志,再看看有没有注册到聚合层
通过kubectl get apiservers,查看有没有注册到,这里为true才算正常
[root@k8s-master1 1.8+]# kubectl get apiservices
v1beta1.metrics.k8s.io kube-system/metrics-server True 19s然后查看kubectl top node来查看node资源的利用率
[root@k8s-master1 1.8+]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 517m 25% 1021Mi 62%
k8s-node1 994m 49% 551Mi 33%
k8s-node2 428m 10% 2466Mi 32% 也可以通过kubectl top pod来查看pod的资源利用率
[root@k8s-master1 1.8+]# kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-59fb8d54d6-7rmx2 13m 14Mi
kube-flannel-ds-amd64-4jjmm 15m 23Mi
kube-flannel-ds-amd64-9f9vq 7m 15Mi
kube-flannel-ds-amd64-gcf9s 9m 15Mi
metrics-server-64499fd8c6-xkc6c 3m 14Mi /也可以通过metrics api 的标识来获得资源使用率的指标,比如容器的cpu和内存使用率,这些度量标准既可以由用户直接访问,通过kubectl top命令,也可以由集群中的控制器pod autoscaler用于进行查看,hpa获取这个资源利用率的时候它是通过接口的,它请求的接口就是api,所以也可以根据api去获取这些数据,
测试:可以获取这些数据,这些数据和top看到的都是一样的,只不过这个是通过api 去显示的,只不过是通过json去显示的
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
[root@k8s-master1 1.8+]# kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"k8s-master1","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master1","creationTimestamp":"2019-12-12T03:45:06Z"},"timestamp":"2019-12-12T03:45:03Z","window":"30s","usage":{"cpu":"443295529n","memory":"1044064Ki"}},{"metadata":{"name":"k8s-node1","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node1","creationTimestamp":"2019-12-12T03:45:06Z"},"timestamp":"2019-12-12T03:45:00Z","window":"30s","usage":{"cpu":"285582752n","memory":"565676Ki"}},{"metadata":{"name":"k8s-node2","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node2","creationTimestamp":"2019-12-12T03:45:06Z"},"timestamp":"2019-12-12T03:45:01Z","window":"30s","usage":{"cpu":"425912654n","memory":"2524648Ki"}}]}将命令行输出的格式转换成json格式----jq命令[root@k8s-master1 1.8+]# kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes |jq
3、 autoscaing/v1 ( cpu指标实践 )
autoscaling/v1版本只支持CPU一个指标。
首先部署一个应用并指出一个service,我们一会测试一下进行流量压测,cpu达到60%的预值然后就进行自动扩容副本,如果流量下来,然后就进行自动的缩容
[root@k8s-master1 hpa]# cat app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 5
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 90m
memory: 90Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80创建HPA策略
用命令生成kubectl autoscale –help
这里可以查看到使用的命令用-o yaml输出出来—dry-run过滤空的字段
kubectl autoscale deployment foo --min=2 --max=10
kubectl autoscale deployment nginx --min=2 --max=10 -o yaml --dry-run > hpa-v1.yaml
[root@k8s-master1 hpa]# cat hpa-v1.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx
spec:
maxReplicas: 6
minReplicas: 3
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
targetCPUUtilizationPercentage: 60
scaleTargetRef:表示当前要伸缩对象是谁
targetCPUUtilizationPercentage:当整体的资源利用率超过60%的时候,会进行扩容。
Maxreplicas:是最大扩容到的副本量
Minreplicas:是最小缩容到的副本量查看扩容状态
[root@k8s-master1 hpa]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0%/60% 3 6 3 52m开启压测,进行对我们的cluster IP进行测试
[root@k8s-master1 hpa]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 443/TCP 5h20m
nginx ClusterIP 10.0.0.211 80/TCP 48m 安装压测命令
yum install httpd-tools -y
[root@k8s-master1 hpa]# ab -n 1000000 -c 10000 http://10.0.0.211/index.html测试cpu已经成功超出预值
[root@k8s-master1 hpa]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 148%/60% 3 6 6 56m最大的副本量是6个,现在已经成功自动扩容
[root@k8s-master1 hpa]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-969bfd4c9-g4zkc 1/1 Running 0 34m
nginx-969bfd4c9-hlcmc 1/1 Running 0 51s
nginx-969bfd4c9-mn2rd 1/1 Running 0 52m
nginx-969bfd4c9-rk752 1/1 Running 0 34m
nginx-969bfd4c9-zmmd8 1/1 Running 0 51s
nginx-969bfd4c9-zz5gp 1/1 Running 0 51s关闭压测,过一会大概5分钟之后就会自动的缩容。
[root@k8s-master1 hpa]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-969bfd4c9-g4zkc 1/1 Running 0 39m
nginx-969bfd4c9-mn2rd 1/1 Running 0 57m
nginx-969bfd4c9-rk752 1/1 Running 0 39m
工作流程:hpa -> apiserver -> kube aggregation -> metrics-server -> kubelet(cadvisor)4、autoscaling/v2beta2(多指标)
为满足更多的需求, HPA 还有 autoscaling/v2beta1和 autoscaling/v2beta2两个版本。
这两个版本的区别是 autoscaling/v1beta1支持了 Resource Metrics(CPU)和 Custom Metrics(应用程序指标),而在 autoscaling/v2beta2的版本中额外增加了 External Metrics的支持。
为了满足更多的需求,hpa还有v2beat1和v2beat2两个版本,这个跨度也比较大,这个可以实现自定义指标
[root@k8s-master1 hpa]# kubectl get hpa.v2beta2.autoscaling -o yaml > hpa-v2.yaml
apiVersion: v1
items:
- apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace: default
spec:
maxReplicas: 6
minReplicas: 3
metrics:
- resource:
name: cpu
target:
averageUtilization: 60
type: Utilization
type: Resource
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx与上面v1版本效果一样,只不过这里格式有所变化。
v2还支持其他另种类型的度量指标,:Pods和Object。
type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1ktype: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2kmetrics中的type字段有四种类型的值:Object、Pods、Resource、External。
• Resource:指的是当前伸缩对象下的pod的cpu和memory指标,只支持Utilization和AverageValue类型的目标值。
• Object:指的是指定k8s内部对象的指标,数据需要第三方adapter提供,只支持Value和AverageValue类型的目标值。
• Pods:指的是伸缩对象Pods的指标,数据需要第三方的adapter提供,只允许AverageValue类型的目标值。另外就是pod暴露的指标,比如http的请求数,吞吐量,也就是http它本身暴露的出来的,但是暴露出来,它不能拿到这些指标,还需要借助一些第三方的监控,也就是使用hpa这里面值的判断,这个提前是要通过kubectl apiservices里面看到注册进去,到聚合层,所有的hpa都是通过聚合层去拿到的,它其实是请求的api到聚合层,然后聚合层帮你代理到后面的组件,比如像metics-service ,它去帮你拿的,然后每个kubelet帮你收集的(cadvisor每个pod的资源利用率,它帮你做一个聚合,聚合之后通过聚合器暴露出来,然后来查询设定的pod的资源利用率,并且做了一个平均,这样就能通过hpa就能拿到之后的目标值,然后hpa再帮你判断,是否达到这个预值,到的话,帮你扩容。
基于pod的实例,pod本身暴露的指标,比较吞吐量,qps,如果目标是1k也会触发
Hpa ->apiserver->agg->聚合层->prometheus-adapter然后它注册到聚合层里面来,prometheus本身就是一个监控系统,它能采集到所有pod暴露的指标,自己存储起来,并且展示,adapter主要将自己注册到聚合层里面并且它能转换这个监控指标apiserver相应的数据接口和prometheus的接口是不一样的,adapter在这里存在的关键是数据格式的转化,对接的不单纯的是prometheus或者其他的监控系统,要想实现自定义指标完成数据的转化和注册,然后prometheus将每个pod展示出来
• External:指的是k8s外部的指标,数据同样需要第三方的adapter提供,只支持Value和AverageValue类型的目标值。
• 工作流程:hpa -> apiserver -> kube aggregation -> prometheus-adapter -> prometheus -> pods
2.6 基于Prometheus自定义指标缩放
资源指标只包含CPU、内存,一般来说也够了。但如果想根据自定义指标:如请求qps/5xx错误数来实现HPA,就需要使用自定义指标了,目前比较成熟的实现是 Prometheus Custom Metrics。自定义指标由Prometheus来提供,再利用k8s-prometheus-adpater聚合到apiserver,实现和核心指标(metric-server)同样的效果。
资源一般就包含cpu、内存就够了,像公有云也是一样都是基于cpu、内存保守型的维度来实现的,但是我们可能会有一些特殊额需求,比如web的服务请求的QPS,或者这组web提供的这组数据,这也是很常见的需求,不过这类需求,并不是很多,它实现没那么简单,目前很成熟的方案就是用prometheus来自定义这些指标
它大概的流程是这样的,api adapter注册到apiserver中的通过apiservice就可以看到,然后到prometheus,然后从pod中获取到这些指标
1、部署Prometheus
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
Prometheus 特点:
• 多维数据模型:由度量名称和键值对标识的时间序列数据
• PromSQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
• 不依赖分布式存储,单个服务器节点可直接工作
• 基于HTTP的pull方式采集时间序列数据
• 推送时间序列数据通过PushGateway组件支持
• 通过服务发现或静态配置发现目标
• 多种图形模式及仪表盘支持(grafana)
Prometheus组成及架构
• Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
• ClientLibrary:客户端库
• Push Gateway:短期存储指标数据。主要用于临时性的任务
• Exporters:采集已有的第三方服务监控指标并暴露metrics
• Alertmanager:告警
• Web UI:简单的Web控制台
部署:
这里没有详细说prometheus的部署,要是需要就看我前面一篇发表的文章
这里只需要部署一个服务端就可以,可以拿到pod的数据就可以,这里还有个pv的自动供给,所以这里我提前部署好了,之前的文章我都写过,这里不做过多演示,
[root@k8s-master1 prometheus]# kubectl get pod,svc -n kube-system
NAME READY STATUS RESTARTS AGE
pod/coredns-59fb8d54d6-7rmx2 1/1 Running 0 25h
pod/grafana-0 1/1 Running 0 18m
pod/kube-flannel-ds-amd64-4jjmm 1/1 Running 0 25h
pod/kube-flannel-ds-amd64-9f9vq 1/1 Running 0 25h
pod/kube-flannel-ds-amd64-gcf9s 1/1 Running 0 25h
pod/metrics-server-64499fd8c6-xkc6c 1/1 Running 0 24h
pod/prometheus-0 2/2 Running 0 23m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana NodePort 10.0.0.233 80:30007/TCP 18m
service/kube-dns ClusterIP 10.0.0.2 53/UDP,53/TCP 25h
service/metrics-server ClusterIP 10.0.0.67 443/TCP 24h
service/prometheus NodePort 10.0.0.115 9090:30090/TCP 23m 访问我的prometheus的30090,这里我没有部署node节点上的node_experiod的组件所以没有采集到,这个因为用不到,我前面的文章部署有详细说明,这里不做这个
3、基于QPS指标实践
部署一个应用:
[root@k8s-master1 hpa]# cat hpa-qps.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: metrics-app
name: metrics-app
spec:
replicas: 3
selector:
matchLabels:
app: metrics-app
template:
metadata:
labels:
app: metrics-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: zhaocheng172/metrics-app
name: metrics-app
ports:
- name: web
containerPort: 80
resources:
requests:
cpu: 200m
memory: 256Mi
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: metrics-app
labels:
app: metrics-app
spec:
ports:
- name: web
port: 80
targetPort: 80
selector:
app: metrics-app该metrics-app暴露了一个Prometheus指标接口,可以通过访问service看到:
[root@k8s-master1 hpa]# curl 10.0.0.107/metrics
HELP http_requests_total The amount of requests in total
TYPE http_requests_total counterhttp_requests_total 31。这一块是我这个pod总共请求了多少的访问,累计值
HELP http_requests_per_second The amount of requests per second the latest ten seconds
TYPE http_requests_per_second gauge
http_requests_per_second 0.5 这个是10秒之内的吞吐率,也就是有0.5个http请求,吞吐率和qps是不一样的概念,qps是指一个范围内求的一个量,但是他们都是求当前量化的一个指标
现在去查看prometheus有没有请求到那三个pod的数据
通过http_requests_total,可以看到我们在yaml中去定义的name_app: metrics-app
之前的如果也想被prometheus采集到,那么就需要去暴露这个指标,这是其一,其二就是采集这个指标,所有的pod的数据是通过yaml中的注解去实现的
app: metrics-app
annotations:
prometheus.io/scrape: "true"。让它能够采集
prometheus.io/port: "80"。 访问它的地址也就是url
prometheus.io/path: "/metrics"。 默认都是metrics
这三个注解的字段都是prometheus开头的,所以要把这个指标拿走监控起来
Prometheus会扫描k8s中的pod有没有暴露的指标,有的话,它会自动加入被监控端,然后将暴露出来,所以这就是prometheus对k8s的自动发现所能感知所监控到
现在采集到了然后就是部署custom metrics adapter
部署 Custom Metrics Adapter
但是prometheus采集到的metrics并不能直接给k8s用,因为两者数据格式不兼容,还需要另外一个组件(k8s-prometheus-adpater),将prometheus的metrics 数据格式转换成k8s API接口能识别的格式,转换以后,因为是自定义API,所以还需要用Kubernetes aggregator在主APIServer中注册,以便直接通过/apis/来访问。
这个主要作用就是将自己注册到api-server中,第二就是转换成api可以识别的数据,https://github.com/DirectXMan12/k8s-prometheus-adapter
该 PrometheusAdapter 有一个稳定的Helm Charts,我们直接使用。
先准备下helm环境:
[root@k8s-master1 helm]# wget https://get.helm.sh/helm-v3.0.0-linux-amd64.tar.gz
[root@k8s-master1 helm]# tar xf helm-v3.0.0-linux-amd64.tar.gz
[root@k8s-master1 helm]# mv linux-amd64/helm /usr/bin现在就可以使用helm 了,安装好helm,还能配置一个helm的仓库
也就是它将adapter存放到这个仓库里面了
添加的话建议使用微软云的adapter的
[root@k8s-master1 helm]# helm repo add stable http://mirror.azure.cn/kubernetes/charts
"stable" has been added to your repositories
[root@k8s-master1 helm]# helm repo ls
NAME URL
stable http://mirror.azure.cn/kubernetes/charts这样的话,我们就能使用helm install,安装adapter了
因为adapter这个chart比如它要连接prometheus的地址,就是默认的chart并不能之前使用,还得把它改了,所以要指定它的地址和端口,直接通过set命令来替换chart默认的变量
部署prometheus-adapter,指定prometheus地址:
[root@k8s-master1 helm]# helm install prometheus-adapter stable/prometheus-adapter --namespace kube-system --set prometheus.url=http://prometheus.kube-system,prometheus.port=9090
NAME: prometheus-adapter
LAST DEPLOYED: Fri Dec 13 15:22:42 2019
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
prometheus-adapter has been deployed.
In a few minutes you should be able to list metrics using the following command(s):
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
[root@k8s-master1 helm]# helm list -n kube-system
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
prometheus-adapter kube-system 1 2019-12-13 15:22:42.043441232 +0800 CST deployed prometheus-adapter-1.4.0 v0.5.0 查看pod已经部署成功
[root@k8s-master1 helm]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-59fb8d54d6-7rmx2 1/1 Running 0 28h
grafana-0 1/1 Running 0 3h30m
kube-flannel-ds-amd64-4jjmm 1/1 Running 0 28h
kube-flannel-ds-amd64-9f9vq 1/1 Running 0 28h
kube-flannel-ds-amd64-gcf9s 1/1 Running 0 28h
metrics-server-64499fd8c6-xkc6c 1/1 Running 0 27h
prometheus-0 2/2 Running 0 3h35m
prometheus-adapter-77b7b4dd8b-9rv26 1/1 Running 0 2m36s检查判断pod是否工作正常,这里已经是注册到聚合层了
[root@k8s-master1 helm]# kubectl get apiservice
v1beta1.custom.metrics.k8s.io kube-system/prometheus-adapter True 13m这样就能通过一个原始的url去测试这个接口能不能用[root@k8s-master1 helm]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" |jq
创建hpa策略
[root@k8s-master1 hpa]# cat hpa-v5.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: metrics-app-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: metrics-app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: 800m查看创建成功的状态,目前是没有拿到这个值的。因为适配器还不知道你要什么指标(http_requests_per_second),HPA也就获取不到Pod提供指标。
ConfigMap在default名称空间中编辑prometheus-adapter ,并seriesQuery在该rules: 部分的顶部添加一个新的:
[root@k8s-master1 hpa]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
metrics-app-hpa Deployment/QPS /800m 3 6 0 16m
nginx Deployment/nginx 0%/60% 3 6 3 24h 添加新的字段,来收集我们想实现的QPS的值[root@k8s-master1 hpa]# kubectl edit cm prometheus-adapter -n kube-system
将这一块放到rules下,,而且中间这个其实是promsql,这个可以执行的,而且和我们的之前输出的结果是一样的,{里面表示字段不为空,更精确一些},这个主要是查询出一系列数据,下面一段是管联,将ns和pod关联,来拿数据,都是对应的关系。
和前面的一样,只不过前面的是http的访问的累计值,现在我们要转换成一个速率,QPS的值是通过范围之内,1分钟之内采集了多少指标进行相加,再除以60秒,就是每秒的值, matches: "^(.*)_total",也举手匹配前面的值进行替换,来提供 as: "${1}_per_second"的值,也就是QPS的值,用这个值为http提供接口,
rules:
- seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'
这个值是求的它的一个平均值,也就是2分钟之内0.42http请求,每一次执行就就近执行的平均数
rate(http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}[2m])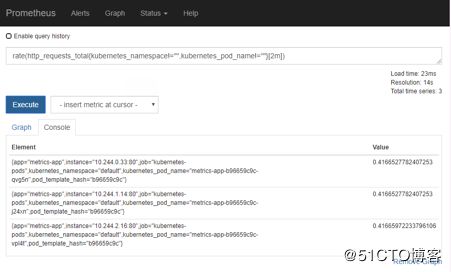
因为我们是多个pod,所以我们需要相加对外提供一个指标,然后我们再给一个by,给个标签,这样的话进行标签去查询
sum(rate(http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}[2m]))
使用by,定义标签的名称方便去查询
sum(rate(http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}[2m])) by (kubernetes_pod_name)
测试api
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second"目前已经收到我们的值了
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
metrics-app-hpa Deployment/metrics-app 416m/800m 1 10 3 2m13s
nginx Deployment/nginx 0%/60% 3 6 3 25h压测
Kubectl get svc
metrics-app ClusterIP 10.0.0.107 80/TCP 3h15m
ab -n 100000 -c 100 http://10.0.0.107/metrics 查看扩容状态
[root@k8s-master1 hpa]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
metrics-app-hpa Deployment/metrics-app 414m/200m 1 10 10 8m36s
nginx Deployment/nginx 0%/60% 3 6 3 26h
[root@k8s-master1 hpa]# kubectl get pod
NAME READY STATUS RESTARTS AGE
metrics-app-b96659c9c-5jxsg 1/1 Running 0 3m53s
metrics-app-b96659c9c-5lqpb 1/1 Running 0 5m24s
metrics-app-b96659c9c-6qx2p 1/1 Running 0 2m21s
metrics-app-b96659c9c-bqkbk 1/1 Running 0 3m53s
metrics-app-b96659c9c-f5vcf 1/1 Running 0 2m21s
metrics-app-b96659c9c-j24xn 1/1 Running 1 3h12m
metrics-app-b96659c9c-vpl4t 1/1 Running 0 3h12m
metrics-app-b96659c9c-wxp7z 1/1 Running 0 3m52s
metrics-app-b96659c9c-xztqz 1/1 Running 0 3m53s
metrics-app-b96659c9c-zhq5r 1/1 Running 0 5m24s
nfs-client-provisioner-6f54fc894d-dbvmk 1/1 Running 0 5h40m
nginx-969bfd4c9-g4zkc 1/1 Running 0 25h
nginx-969bfd4c9-mn2rd 1/1 Running 0 25h
nginx-969bfd4c9-rk752 1/1 Running 0 25h等待一会大概5分钟就会进行副本的缩容
小结:
- 通过/metrics收集每个Pod的http_request_total指标;
- prometheus将收集到的信息汇总;
- APIServer定时从Prometheus查询,获取request_per_second的数据;
- HPA定期向APIServer查询以判断是否符合配置的autoscaler规则;
- 如果符合autoscaler规则,则修改Deployment的ReplicaSet副本数量进行伸缩。