
本文来自 Apache Kylin Meetup 北京站上小米大数据平台 OLAP 负责人陈学辉的分享。
小米拥有众多产品线,业务遍及全球 80 多个国家和地区,数据规模大,对查询响应时间要求高。本次分享主要介绍了 Kylin 在小米内部的使用情况,包括适用的业务场景,遇到的挑战,源自业务实践中的功能优化点。
小米业务场景
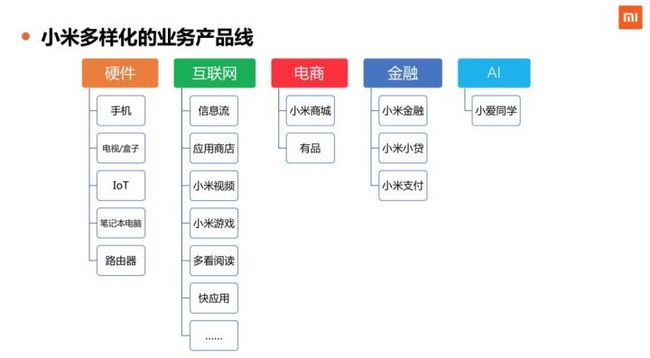
小米的产品业务线包含硬件、互联网、电商、金融、AI等等,绝大部分都有非常强烈的数据分析和统计需求。小米在不断进行全球化的商业布局,在全球各地都有自己相关的硬件、互联网等业务在开展。
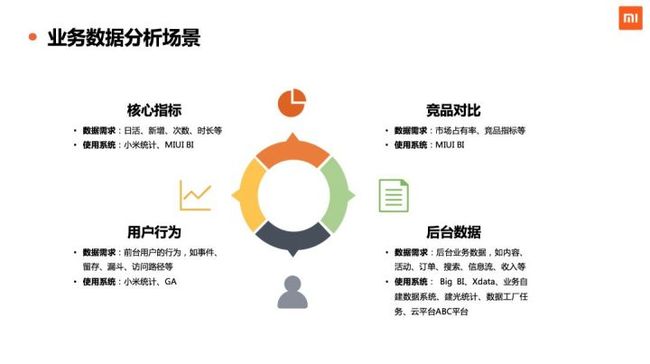
下图为小米目前的主要业务数据分析场景。
下图为小米业务上对数据的需求。
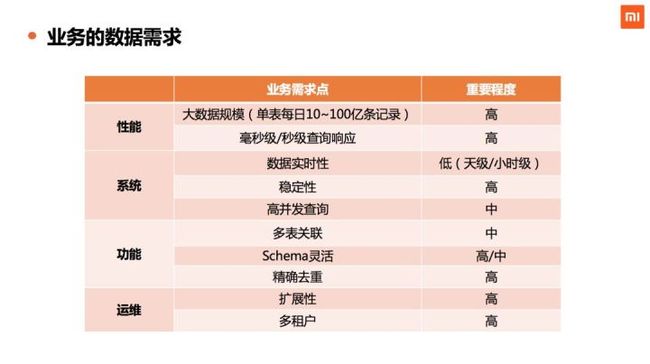
在性能层面,数据规模大,且对查询响应时间要求高。
在系统层面,小米的大部分场景,时效性要求不是特别高,一般来说天级或小时级的时效性,就能够满足业务大部分的需求。但对数据系统的稳定性要求非常高。高并发查询目前来看,需求中等。
在功能层面,对多表关联这种场景,需求中等。Schema 灵活性在用户分析的场景要求会比较高,在其他的场景要求适中。精确去重在绝大部分场景之中是强依赖的需求,所以我们非常注重这一块的能力。
在运维层面,我们比较关心数据系统的扩展性,以及多租户性,保证资源隔离、各个业务不互相干扰。
简单给大家介绍小米内部的几种主要的数据分析和统计系统。

数据工场是小米内部的数据仓库平台,服务于小米绝大部分的业务。这套系统的局限和不足也有很多,比如说报表展现比较简单。一个任务对应一个图表,工作量会随统计需求呈现出正相关的增长。
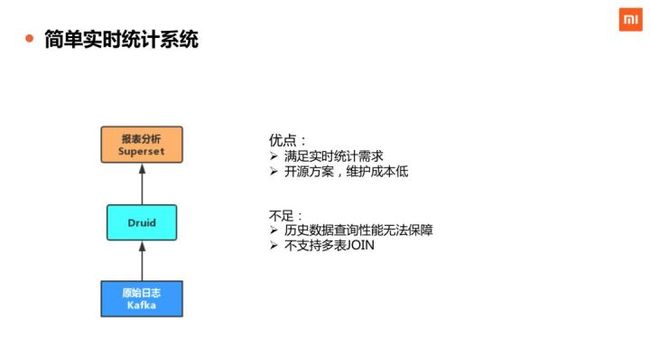
第二,就是简单实时的统计系统。在实时性要求比较高的场景里,我们用开源的方案,去比较快速地搭建这样的系统,这样的系统比较满足我们实时性比较高的需求,维护的成本相对比较低,缺陷是对于大跨度的历史数据查询性能得不到满足,且不支持多表 Join。
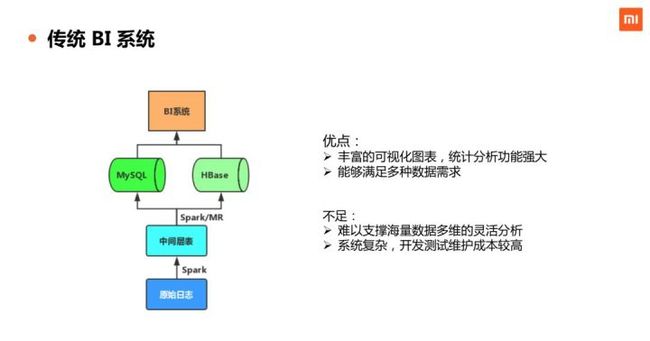
第三,是传统的 BI 系统。BI 比较重量级,需要比较大的维护成本。优点是丰富的可视化图表,统计分析功能也会非常强大。它主要是偏人工定制,因而能够满足各种各样的数据需求。不足点也很明显,第一难以支撑海量数据多维的灵活分析,第二是整个系统的开发运维成本较高,因为大部分都是靠人工写代码,对计算逻辑正确性、系统稳定性等方面有较高要求。
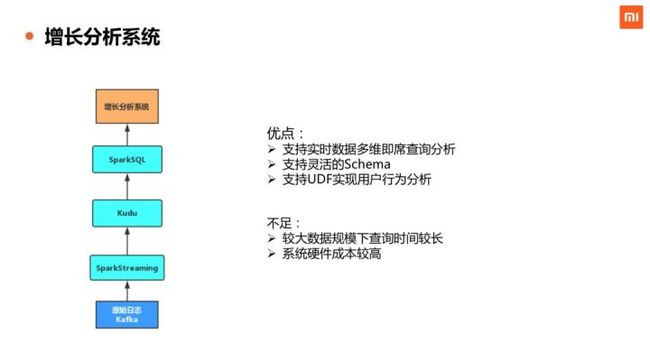
最后,是我们 2018 年启动的增长分析系统,该系统基于“事件模型”为互联网业务提供 App 内的用户行为分析能力,使用 SparkSQL+Kudu 的技术方案实现实时多维分析,能够同时提供统计聚合和明细粒度的查询分析。这个系统的优点是能够提供实时多维的数据查询分析,实时动态增加字段,支持多种用户行为分析的模型。不足之处,在数据规模比较大的情况下,查询响应时间较长,另外整个系统的硬件成本比较高。
我们正在研发的 Big BI 自助 BI 报表平台,主要用到 Kylin+Doris 两个开源 OLAP 系统的多维分析能力。
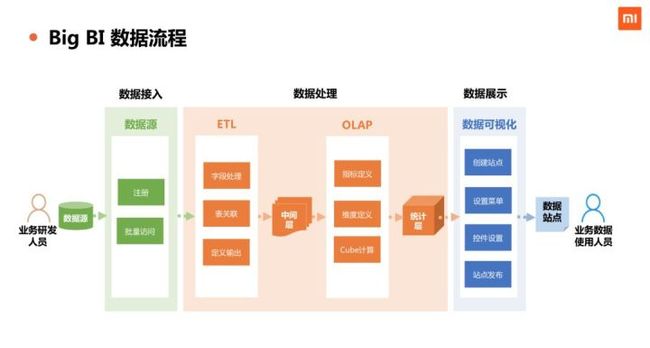
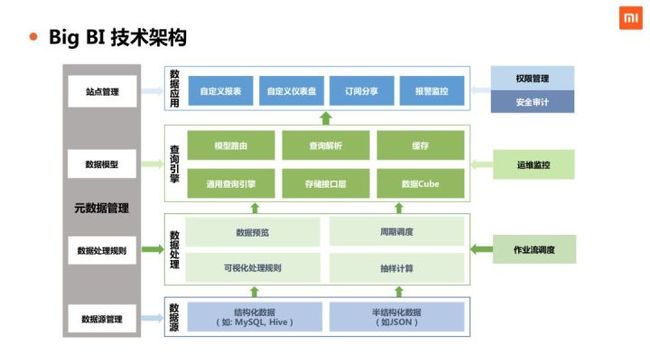
BigBI 希望通过自动化的方式去实现业务数据从 0 到 1 的过程,从最开始的数据源接入到数据处理(包括数据清洗ETL和数据建模),再到数据展现,实现全环节可配置化,提升 BI 系统研发效率。技术架构图如下:
Kylin的使用情况
接下来给大家分享 Kylin 在小米内部应用的基本情况、实践案例、使用技巧和未来规划等内容。
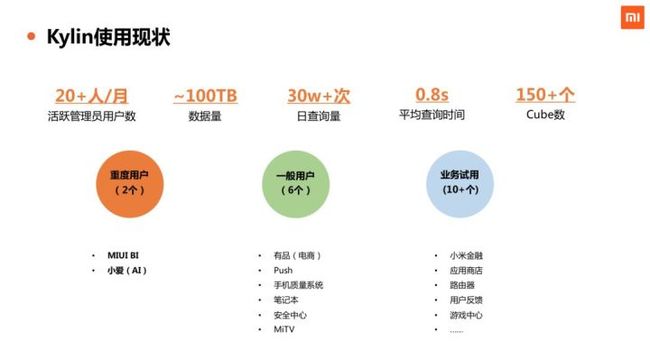
小米内部大概有十几个业务在使用 Kylin,平均每个月活跃的项目管理员有 20 多人,每个项目会有 1 到 2 个管理员(研发)来维护 Kylin 的 Cube 数据。目前 Kylin 总体数据量在 100 TB 级别,平均每天对 Kylin 的查询次数是 30W 次以上,整体平均查询响应时间是 0.8 s 左右,Cube 总数是 150 个左右。
Kylin 有2个重度用户,一个是 MIUI BI,MIUI BI 是覆盖手机数据和互联网 App 数据的公司级 BI 平台。另外一个是人工智能产品小爱同学,小爱业务也会大量地用到Kylin做数据统计。另外,一般用户有有品、Push、手机质量系统等。重度用户大概每天查询量都是在 10 万级以上,一般用户的日均查询量在 1k 到 10k 之间。
小米内部维护了一个自有的 Kylin 的分支,我们会定期同步社区的 Kylin 版本。目前线上环境使用的是 Kylin 2.5.2 版本,启用了 Cube Planner 特性,方便分析 Cuboid 查询命中情况,提高 Cube 优化剪枝效率。
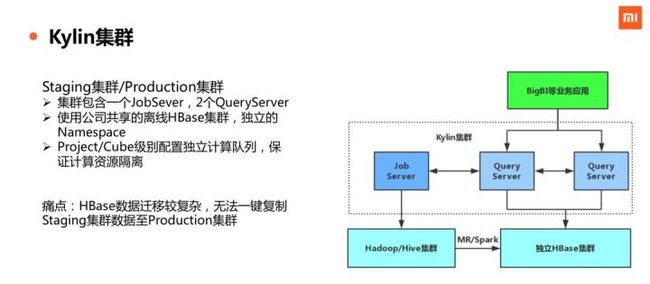
公司内部的 Kylin 集群包含 3 台服务器,其中 1 台 JobSever,2 台 QueryServer,能够满足前面所提到的日常查询量负载。Kylin的后端存储使用了公司统一维护 HBase,为此,修改 Kylin 代码适配了公司的 HBase v0.98。通过 Project 或者 Cube 级别配置独立计算队列,基本实现了计算资源隔离,确保业务之间的 Cube 构建过程互不影响。
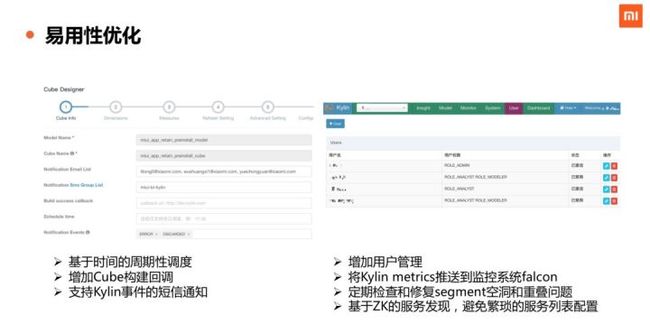
我们在 Kylin 上做了一些易用性的改进。业务使用方面,支持了基于日期时间的周期性调度,这样可以让我们的 Cube 每天定时地去跑,不用我们通过别的手段去触发。另外,增加了 Cube 构建成功事件的回调,每天成功构建 Cube之后,产生回调通知,方便业务系统都将最新的数据用起来。
为了支持多用户,我们在 Kylin 界面上增加了用户管理的页面,便于为多个业务线创建用户和管理权限。一个常见的场景,因为队列资源紧张或其他原因,导致业务某一天的 Cube 构建失败而产生空洞,一般需要人工触发再次构建,针对这个业务使用痛点问题,我们开发了定期检查和修复 segment 的空洞和重叠情况功能,当发现某一个业务线有不连续的 Cube 数据时候,自动触发相关 segment 的构建任务。
监控运维方面,支持了 Kylin 各种内部事件的短信通知,能够帮助我们的研发工程师及时了解系统情况。我们打通了小米内部的 falcon 监控平台,将 Kylin 的关键的指标,如查询时间等信息推送到 falcon 上,建立 Kylin 的服务监控。我们还做了基于 ZK 的服务发现功能,避免繁琐的手工配置,降低运维的成本。
以上是我们在易用性方面的优化,我们还向社区提交了十余项改进和修复的 patch。

其中第一项是 support max segment merge span,是我们从内部合并的角度去做一些优化,我们会去设置一个最大的 segment 的粒度,当 segment 到达最大的粒度之后,对应的中间文件不再继续保留而被清理掉,可以节省 HDFS 的存储空间。其他 patch 大家有兴趣的话可以通过 Jira ID 查看具体的改动内容。
接下来讲一下我们内部实践中的一些简单实用技巧。

编写 SQL 查询语句时,比如说用 date、sum 等关键词,是需要用双引号来括起来的。需要注意的是,SQL 语句查询的表应该是 Hive 表名,而不是 Cube 和 Model 的名称。Cube 和 Model 是 Kylin 逻辑上的抽象,查询的对象实际还是 Hive 表而非 Cube/Model。
设计 Cube 时,可以通过调整 Rowkey 顺序来优化查询性能。这一块有几个小点的分享:第一要将查询中作为过滤条件的字段,放在其他维度前面,保证它优先被查询到;第二是将经常出现的维度放在不经常查询的维度的前面;第三是对于基数较高的维度,如果高基维度会出现在过滤条件中,则将它先前移,否则后移,因为高基维度通常会导致数据膨胀比较厉害。
最后一点是 UV 统计场景的心得,大家知道,当 UV 量级达到上亿级别时,COUNT DISTINCT 的计算成本和存储成本比较高。我们的优化思路是,在数据预处理的时候,保证一个 ID 的数据只存一行数据,同时设置字段 UV 值为1表示该 ID 是活跃的,通过 SUM(UV) 替代 COUNT DISTINCT 来计算 UV,大幅节省了计算时间和存储空间。

另外,简单分享一下我们之前在 MIUI BI 项目里使用 Kylin 时遇到的维度互斥问题。MIUI BI 的国家维度,包含了全部国家,海外国家,中国,印度,印尼,俄罗斯等不同层次的维度值。这种复合维度在 Kylin 构建 Cube 时,统计数据是有问题的,因为 Kylin 内在要求维度的不同取值之间不能有包含关系,否则统计值不准确。另外,在 MIUI BI 的场景里,层级维度并不能满足业务的需求,因为 Kylin 的层级维度要求在查询时低级别维度时,需要同时带上低级别维度对应的高级别维度。我们的解决的方案是,构造维度互斥,将一个维度拆成两个,保证 2 个维度之间能够实现互斥的效果。这样的话 Cube 计算的统计值就是正确的,这种拆分维度方案带来的副作用会导致查询语句变复杂。

查询性能和弹性运维方面探索更好的方案。另外一个重要的方向是,希望能够把 Kylin、Doris、SparkSQL 等多种引擎结合起来实现智能路由,充分发挥每种引擎的长处,形成公司级的 OLAP 解决方案。目前公司许多产品线 OLAP 需求是通过多种技术方案和引擎来实现的,比较杂乱,希望未来能够形成统一的 OLAP 解决方案,降低研发和维护成本。关于 Kylin 的底层的存储引擎,我们正在测试 Kylin On Parquet 方案,希望通过这个方案能够提升 Kylin 查询性能。另外我们也会在弹性运维上去做尝试,试图把 Kylin 部署到 Kubernetes 上,把 Kubernetes 的一些特性用起来,提高运维效率。
Q&A
提问:每次构建 Cube 数据量的大小,每个 Cube 构建时间大概是多少?
回答:我们大概是 500 G;绝大部分业务 1 天的数据大概一个小时内能构建完。
提问:最后一页你提到比较关注 Kylin on Parquet 的方案。能够讲一下你们希望通过 Kylin on Parquet 来获得什么方面的收益?
回答:我们发现 HBase 模糊匹配的效率不是特别好,希望通过 Parquet 列式存储格式提升 scan 性能。
回答:其实我可以请到我们这边资深的同学来讲一下,他做了大量的工作。刘绍辉是我们计算平台的同学,也经常给 Kylin 社区提交 Patch。
绍辉:测试 Parquet 主要是因为 HBase 有一些数据量的限制,数据量不匹配的时候,在 HBase 上会狂扫数据,但你拿到的数据其实很少,这样的话对 HBase 的压力也是很大。现在我们测试的情况是把流程跑通了,但是后面会有一些结合业务的测试,还在继续做的过程中,后面是希望慢慢有一些业务实际使用起来,提高整个 Kylin 的性能。
提问:你们现在 Kylin 的构建,是由基础业务来做?还是交给了实际业务来做?
回答:一般情况会由业务的研发人员设计和构建 Cube,业务同学更懂他们的数据和查询需求,我们会在 Kylin 技术和剪枝优化方面给业务的研发同学提供帮助和支持。
提问:
回答:小米内部大部分场景是 10 个左右的维度就能够满足业务需求,我们的业务场景下的维度不会特别多。Kylin 本身有 64 个维度的限制。
提问:Kylin On Parquet 处理的相关业务或者说数据格式有什么要求?还有一个问题就是 Kylin ON Parquet 和 Spark SQL 有什么区别?
主持人:Kylin on Parquet 和 Spark SQL 现阶段来说没有太大的关系,我们只是把 Parquet 作为 Kylin 一个存储的方式,把它转型到了 Spark 的格式。在查询的时候,我们会把 Kylin 生成的查询计划,转变成在 Spark 里面去做对 Parquet 文件的处理,然后我们给到 Spark 的并不是一个简单的内容,而是一个文件集的操作。未来这里可以再做一些打通,比如说能够把 Kylin 的查询直接的变成 SparkSQL,然后用 SparkSQL 去查 Parquet,这样的话 SparkSQL 也有自己的查询优化,这样的话最终能够达到一个比较好的性能。
数极客是新一代用户行为分析与数据智能平台,支持用户数据分析、运营数据分析、留存分析、路径分析、漏斗分析、用户画像、SEM数据分析等16种分析模型的数据分析产品,支持网站统计、网站分析、APP统计、APP分析等分析工具,以及会员营销系统和A/B测试工具等数据智能应用,支持SAAS和私有化部署,提升用户留存和转化率,实现数据驱动增长!