Hadoop简介
Hadoop 是Apache基金会下一个开源的分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心,为用户提供了系统底层细节透明的分布式基础架构。
Github地址:https://github.com/apache/hadoop
官方网站:https://hadoop.apache.org/
官方文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
中文社区:http://chinahadoop.com/
Hadoop的两个核心组成:
1.HDFS:分布式文件系统,存储海量的数据。是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
2.MapReduce:并行处理框架,实现任务分解和调度。包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
Hadoop特点
1.高扩展:能可靠地存储和处理千兆字节的数据,理论上是无限的
2.低成本:借鉴谷歌,可以通过普通机器组成的服务器群来分发以及处理数据,这些服务器群总计可达数千个
3.高效率:通过分发数据,Hadoop可以在数据所在的节点上并行地处理他们,这使得处理的非常迅速
4.可靠性:Hadoop能自动地维护数据的多份副本,并且在任务失败后能自动的重新部署计算任务
Hadoop用途
搭建大型数据仓库,PB级数据存储、处理、分析及统计,用于搜索引擎、BI、日志分析及数据挖掘等
Hadoop生态圈
Hadoop 已经成长为一个庞大的生态体系,只要和大数据相关的领域,都有 Hadoop 的身影。下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数据工具。

在window中使用Hadoop
1.Hadoop下载
推荐通过镜像下载
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
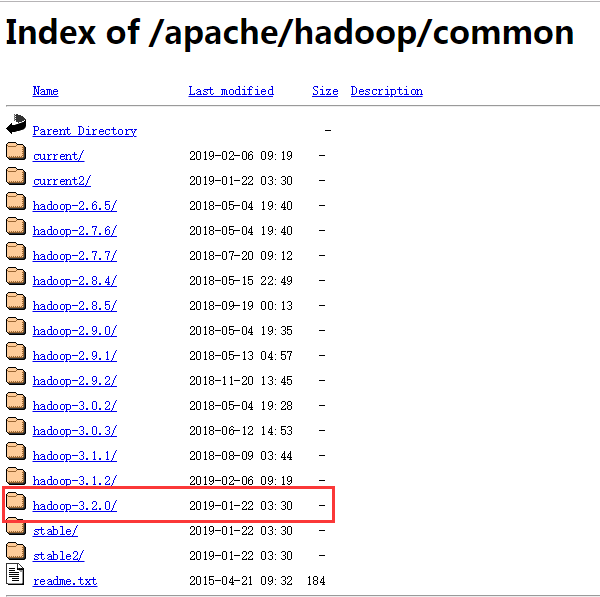
选择最新的3.2.0,下载tar.gz文件

2.Hadoop安装
下载完后直接解压
解压过程中可能遇到的问题

解决方法,在cmd中使用解压命令start winrar x -y hadoop-3.2.0.tar.gz
解压完成如下:

关键目录说明:
bin:存放Hadoop的操作命令
etc:存放Hadoop的配置文件
sbin:Hadoop的管理命令
share:包括Hadoop的文档和组件包
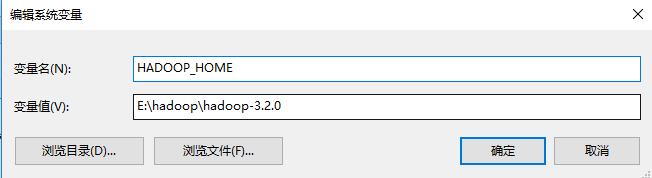
3.配置Hadoop相关的环境变量
新建系统变量
变量名:HADOOP_HOME
变量值:Hadoop解压路径
添加path属性,
%HADOOP_HOME%\bin和%HADOOP_HOME%\sbin添加到path环境变量中
检验是否安装Hadoop成功
cmd中输入hadoop version,显示安装的版本号即可

4.Hadoop配置文件的修改
主要在/etc/hadoop中修改
4.1.配置默认hdfs的访问端口,主要修改core-site.xml
9000端口是通过http协议连接Hadoop使用的端口
fs.defaultFS
hdfs://localhost:9000
修改后core-site.xml为
fs.defaultFS
hdfs://localhost:9000
4.2.设置复制数为1,即不进行复制。以及加入namenode文件路径以及datanode数据路径。主要修改hdfs-site.xml
需要先在Hadoop安装目录下新建两个文件夹namenode和datanode,用来做名字节点和数据节点的数据存储,根据自己的所在路径去设置
dfs.replication
1
dfs.namenode.name.dir
file:///E:/hadoop/hadoop-3.2.0/namenode
dfs.datanode.data.dir
file:///E:/hadoop/hadoop-3.2.0/datanode
修改后hdfs-site.xml为
dfs.replication
1
dfs.namenode.name.dir
file:///E:/hadoop/hadoop-3.2.0/namenode
dfs.datanode.data.dir
file:///E:/hadoop/hadoop-3.2.0/datanode
4.3.设置mr使用的框架为yarn,主要修改mapred-site.xml
mapreduce.framework.name
yarn
修改后mapred-site.xml为
mapreduce.framework.name
yarn
4.4.设置yarn使用mr混洗,主要修改yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
修改后yarn-site.xml为
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
5.启动Hadoop服务
5.1.格式化 HDFS,在cmd中执行hdfs namenode -format
前提:在windows中启动需要在bin目录中加入hadoop.dll和winutils.exe
否则会报异常
java.io.FileNotFoundException: Could not locate Hadoop executable:
E:\hadoop\hadoop-3.2.0\bin\winutils.exe
-see https://wiki.apache.org/hadoop/WindowsProblems
获取hadoop.dll和winutils.exe
Hadoop2.6.0到Hadoop3.0.0版本(如更新了新版本可以使用):
官方推荐:https://github.com/steveloughran/winutils
版本最好对应起来,更新到3.0.0版本,在上面直接下载即可,下载完后引入到bin目录
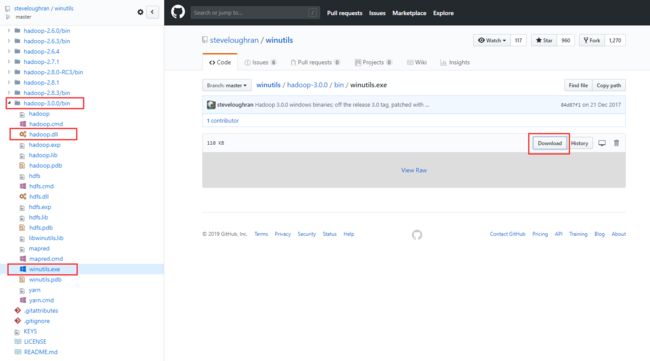
注:由于用的是Hadoop3.2.0版本
需要在https://github.com/s911415/apache-hadoop-3.1.0-winutils上获取
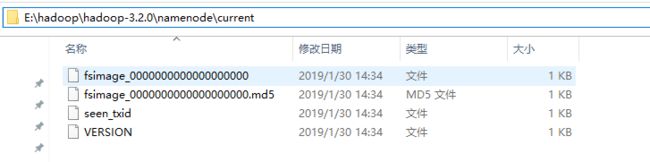
格式化成功如下

格式化之后,namenode里会自动生成一个current文件夹,则格式化成功
5.2.在sbin中执行start-all.cmd,可以用命令或者直接双击
同时启动了如下4个服务:
Hadoop Namenode
Hadoop datanode
YARN Resourc Manager
YARN Node Manager

可能存在的问题
5.2.1.其中Hadoop Namenode和YARN Resourc Manager启动会报异常
java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.yarn.server.timelineservice.collector.TimelineCollectorManager
原因:缺少timelineservice.jar包
解决方法:
把share\hadoop\yarn\timelineservice\的hadoop-yarn-server-timelineservice-3.2.0.jar复制到share\hadoop\yarn\lib文件夹
5.2.2.hadoop.dll引入错误,或者版本不对应,Hadoop datanode和YARN Node Manager启动会报异常
java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;I)Z
org.apache.hadoop.util.DiskChecker$DiskErrorException:
Too many failed volumes - current valid volumes: 0, volumes configured: 1, volumes failed: 1, volume failures tolerated: 0
报的异常是getStat出了问题,也就是说SHELL.WINDOWS是false了,应该是hadoop.dll的问题
解决方法:更换成对应版本的hadoop.dll
6.1通过YRAN网站查看Hadoop查看所有节点状态。默认地址为:http://localhost:8088/
6.2文件管理页面默认地址为:http://localhost:9870/
在3.0.0之前的版本中文件管理的端口是50070,在3.0.0中替换成9870端口
这里需要注意的是操作权限问题
权限不足会提示Permission denied: user=dr.who, access=WRITE, inode="/":sportsbenpeng:supergroup:drwxr-xr-x
可以在hdfs-site.xml中过滤权限验证
dfs.permissions
false