EIP的两个靠谱框架:si和mule3,在基本面上思路一致:基于发扬光大Spring OO的解耦能力,达到配置式使用、一定要用上spring xml schema;基于配置组装程序、基本的使用尽量走配置不走代码,这样si基本组件的重用性高。当然mule作为商业产品更进一步,基于Spring实现了对象热加载热替换。


spring-core有对消息的抽象,消息。不管你什么协议就俩个部分:Header和PayLoad:

Spring Integration provides abstractions over messaging and also other transports such as HTTP, TCP, and others. si进一步屏蔽掉不同协议,不管你是什么协议来到的消息,一视同仁全是org.springframework.messaging.Message. si从spring一路继承下来:
Message.
|
GenericMessage 常用
|
AdviceMessage
第二个si会用到的是:org.springframework.messaging.support.ErrorMessage,当发生错误异常时,si的异常处理器会创建该类型消息、将原始出错消息包装其中,比如我们在转发http消息时可能对方服务下线了:
我们希望拿到错误消息以及出错原始消息、存储成文件、再做后续处理(这是一个比较通用的处理方式,因为文件系统是最基本的)。可以使用转换器:
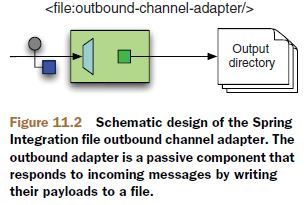
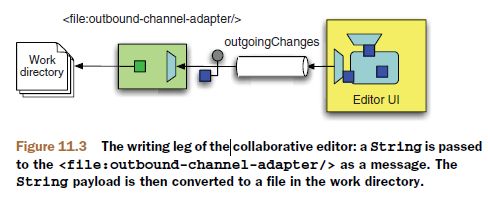
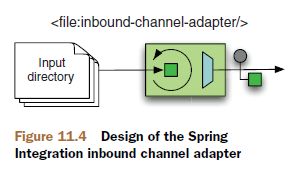
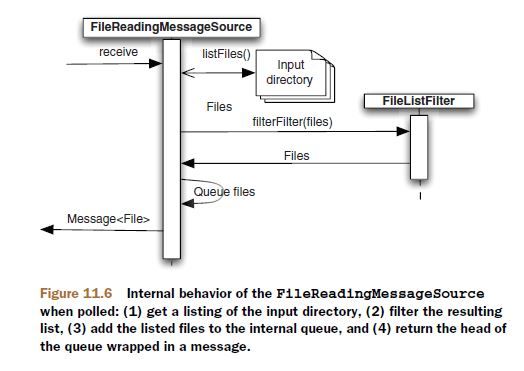
在这个转换器(POJO)的处理方法当中,收到的消息类型就是ErrorMessage,原始消息也在里面,想怎么处理随意。这种异常/错误处理思路,颇契合函数式的方法调用链,在一连串的方法调用链路上,中间出了异常也没关系,将异常当做新的消息继续往下传递。 从文件处理开始了解si,同时参考官方文档。一些文件IO的最佳实践。最佳实践建议不要自己用字符串拼文件路径文件名,而要尽量使用java.io.File处理,这样才能充分利用JVM的平台隔离能力保证你的代码跨平台。再就还是要用buffer包装stream适配磁盘:IO performance depends a lot from the buffering strategy. Usually, it's quite fast to read packets with the size of 512 or 1024 bytes because these sizes match well with the packet sizes used on harddisks in file systems or file system caches. But as soon as you have to read only a few bytes and that many times performance drops significantly. 文件形式消息的处理包括:从文件系统pick文件、扫描过滤目录、写文件、处理并发读写。EIP这本经典定义的四种信息交互模式文件传输、共享数据库、RPC和消息,前两种都是将信息通过第三方中介传输(JMS也是)需要更多序列化反序列化,后两种属于两个交互系统间内存到内存,理论上性能高一点,但没有了第三方可靠保障。早期同一台机器上的两个进程可以采用磁盘互相交换数据信息,交互系统如果都在一台机器,可以直接读写磁盘,不在一台,可以借助FTP. JMS和邮件都是有第三方服务器的消息形式,对于文件交互来说,磁盘也相当于第三方服务。不要小看文件传输方式,相比消息或webService似乎它太老了,但是文件传输比它们都要简单可靠、更通用,并不过时。很多企业费劲巴拉赶时髦上SOA特别是soap WS,结果发现被坑了,SOA没有错,是复杂而无用的soap坑爹,这些企业最终还是保留了很多文件传输方式。文件写入磁盘,这本身就是容错,此为优于soap WS的第一点,第二点:soap充斥着没什么实际用处、过度复杂的规范,而磁盘和文件系统成熟、简单,文件仍然是simplest thing that might possibly work. If a simple solution just works, it has earned a right to stay in business. 大多javaer像怕并发一样怕和文件系统打交道,这没必要,比如在UNIX中,一切皆文件,编写OS的人想要做点信息交互可以依赖什么?只有文件系统,文件系统的优点对缺点: 1、容错,容许应用crash - 额外的复杂:资源、锁; 2、磁盘空间大 - 磁盘慢; 3、文件处理比较简单 - 文件系统无一致性保障,像什么隔离、ACID或rest语义都没有,自己实现也不是障碍; 文件作为一个功能模块,SI专门提供有file命名空间,像这样: xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:file="http://www.springframework.org/schema/integration/file" xsi:schemaLocation="..... http://www.springframework.org/schema/integration/file http://www.springframework.org/schema/integration/file/ ➥spring-integration-file.xsd"> file:inbound-channel-adapter属于一种单向的接收文件的EndPoint端点。SI中可以理解端点是与外部交互的、Channel管道则是在内部流转消息的。 schema是spring达到重用目标的重要基石,使用file命名空间前缀,在eclipse和idea都可以快速定义组件包括channel adapter管道、各种transformer转换器(支持把文件内容读取为strings or byte arrays.),虽然它们全部可以仍然使用原始的bean标签定义,比如上述file:inbound-channel-adapter也可以按照bean配置: 但这样味道就不对了,完全按照shema定义出来的配置,近乎对程序整体的一个自然语言描述,至于代码,都是si封装好的那一套,这就是对si代码的高效重用,OO讲究隔离变化,变化是怪兽、把变化从代码中剥离、用配置封印。spring配置本质上就是做组装的、做程序装配的。 进入filesystem integration的琐碎细节,有助于你理解spring-integration-file项目,不过只是使用的话不看也可以。首先讨论读取文件时的排序和锁问题,这俩问题本来是写文件引发的,但是体现在读文件时。读写之间互斥的锁是必须要有的,且这个问题与OS相关,读写之间没有互斥锁,上一点点量、读很容易就会读到unfinished files,作为不完整的非法消息进入系统,后面异常等着你。 只用JDK读文件很套路了,用Buffer包装Stream: BufferedReader input = new BufferedReader(new FileReader(aFile)); StringBuilder contents = new StringBuilder(); //单线程构造字符串用SB try { String line = null; while (( line = input.readLine()) != null){ contents.append(line); contents.append(System.getProperty("line.separator")); } } finally { input.close(); } 用si就这么简单: o.s.i.file.FileReadingMessageSource : Created message: [GenericMessage [payload=C:\...\sql.txt, headers={file_originalFile=C:\...\recoveryChannel\sql.txt, id=88cd300e-8ae5-691e-8185-59a52b3c00be, file_name=sql.txt, file_relativePath=sql.txt, timestamp=1540960288297}]] FRMS作为消息源会如上创建GenericMessage 什么文件可以读取处理,si管这叫做过滤,过滤掉什么样的文件不能读取处理,si提供一个扩展点:FileListFilter,你可以扩展实现它以决定什么文件可以处理什么文件不处理,默认自带俩:IgnoreHiddenFileListFilter隐藏文件过滤(4.2引入)、AcceptOnceFileListFilter防重复读取过滤。 我们知道文件锁分为共享锁(读锁)和排他锁(写锁),共享和排他都是绝对的语义,简单说就是排他锁和排他锁共享锁之间都是互斥的。si的实现比较mule还是简陋,si并没有基于文件锁做通用的文件读写互斥,如果写入端和读取端都是你的si程序那好说: 1、如果读写端都在一个context里,自动互斥; 2、如果不是在一个context里但都是si项目:可以使用入栈管道的filename-pattern=“.msg”和出栈管道的temporary-file-suffix=“.tmp”基于后缀实现读写互斥; 3、如果有一端是不受控外部程序,比如写入端是其他异构系统,那么还可以酌情使用LastModifiedFileListFilter: 从5.0开始,以文件形式进入的消息增加了如下Header供你使用: 1、FileHeaders.FILENAME常量:配置中取:filename-generator-expression="headers.file_name" 2、FileHeaders.ORIGINAL_FILE:File本身,可用于拿到原始文件;headers.file_originalFile 3、FileHeaders.RELATIVE_PATH:用于带目录层次的需求;headers.file_relativePath 对应一个文件消息的头部是这样: headers={ file_originalFile=C:\...\34481a31-c7a6-652c-3e9f-86c4c7543261.msg, id=5ec39fbf-3d78-1258-228e-a7ff68faf431, //si的消息ID是UUID file_name=34481a31-c7a6-652c-3e9f-86c4c7543261.msg, file_relativePath=34481a31-c7a6-652c-3e9f-86c4c7543261.msg, timestamp=1540796199647 } 一些场景当中,读取文件的顺序很重要(类比MQ的有序消息队列),通用型FRMS必须能够处理排序,FRMS列举一个目录下的文件使用了File’s listFiles()方法,它返回File[]、一个有序数组,但是这个顺序在不同OS、不同配置下不一定一致,长话短说,你必须提供一个Comparator来保障排序。现在的问题是,当文件不是按序写入的时候,FRMS内部队列也必须能够对已经包装为消息的文件进行重新排序: 如果文件不是按照生成顺序添加到内部队列的,FRMS是无所适从的,它自己不知道顺序乱了。如果你写文件的顺序就是你希望它们被处理的顺序、并且你提供了comparator排序器,那就好说了,FRMS会依据comparator读取处理文件。不要妄想只依赖消息生成顺序It’s never a good idea to depend on message order implicitly. 如果不得不,你得定义resequencer重排器。 锁这个东西,最大的麻烦是不同OS实现不一样,幸好我们有JVM。si的转换器将读取文件当前内容(at the moment they reached the end of it.)并处理转换为String or byte[],简单说就是有啥读啥有多少读多少,一个正在被某进程写入的文件,只要不被打开读取、其引用随便传递没问题,而一旦还没写完就被打开读取,就会读到不完整内容。避免这种premature早熟读的最佳方式,是由写进程来决定该文件何时写完了:你可以用写完文件的转储移动方式move-when-ready,给文件名加个前缀用来标识还没写完的和已经写完的也属于这种,举例来说:如果读写两端都是si,读文件就可以和写文件配合起来了,在写文件一端,使用temporary-file-suffix来指定一个正在写的文件(临时文件)前缀(该属性与append属性互斥),文件写完则修改文件名为正式文件名,正式文件名由一个文件名生成规则FileNameGenerator指定,读写两端都需要遵守这个文件名生成规则,可将FileNameGenerator配置为独立bean,在读写两端的filename-generator属性都指向这同一个bean. 其他判断文件是否完成写入的靠谱手段,包括比如对于xml格式的文件,可以依据xml根标签的结束作为判据,其他的只要是有格式的内容都可以采用类似方式。实际上这种方式也用于TCP,所以说TCP和文件有类似之处:都是字节流、既然是流、都需要有判断结束的手段。TCP比文件更好的地方在于,TCP消息有头,那么最简便的方式就是在头部定义消息长度,但是文件没有,文件不分Header、Body。结束标志这种方式显然不如move-when-ready,它还得读文件读到末尾。再者对于一些并发写的情况,可能末尾已经写完了但是中间部分还正在写,比如BitTorrent就这么干的,再比如写图片也常这么干,其实这些都是有点low的tricky,正统搞法是文件锁。 文件锁美中不足的是:File locking works differently on different operating systems。JVM在java.nio库对文件锁有一个抽象,si在java.nio 2.0版本上同时支持文件的锁和过滤,你可以注入NioFileLocker,当然要求写文件一端也具备对锁的处理。锁是比较完备的保底方案但是有一定复杂性。 在mule3中提供有使用 java.nio.channels.FileLock文件锁 实现基本互斥的org.mule.transport.file.FileMessageReceiver,相当于si的FileReadingMessageSource,但它是主动poll的组件,它内部有一个尝试获取文件锁方法: protected boolean attemptFileLock(File sourceFile) throws MuleException { FileLock lock =null; FileChannel channel =null; boolean fileCanBeLocked =false; try { channel = (new RandomAccessFile(sourceFile,"rw")).getChannel(); lock = channel.tryLock(); //////////////////////////////////////【添加代码】 }catch (FileNotFoundException var24) { throw new DefaultMuleException(FileMessages.fileDoesNotExist(sourceFile.getName())); }catch (IOException var25) { ; }finally { if(lock !=null) { fileCanBeLocked =true; try { lock.release(); }catch (IOException var23) { ; } } if(channel !=null) { try { channel.close(); }catch (IOException var22) { ; } } } return fileCanBeLocked; } 以上代码用于读取文件的场景下可用,但是如果写文件的第三方进程不讲究,没有按规矩加文件锁的话就失效了,那么我们可以定义我们要读的消息文件末尾比如在这个类中定义: private static String PublishEvent =""; 然后在上述【添加代码】处增加判断正确的文件内容结尾: byte[] dst =new byte[18]; long fileSize = channel.size(); int offset = (int)(fileSize -18L); if(offset >=18 && fileSize >=512L) { int result = channel.read(ByteBuffer.wrap(dst), (long)offset); if(result != -1 && result !=0) { String endTag =new String(dst,"UTF-8"); if(!endTag.contains(PublishEvent) ) { lock =null; } }else { lock =null; } }else { lock =null; } 写文件就比读文件简单了,写文件第一需要指定写目录,第二你得有一个字节数组或者是字符串去写、以及一个文件名。如果只用JDK,代码就是这么啰嗦: Writer output = new BufferedWriter( new FileWriter(aFile) ); try { output.write("This is written to the file in default encoding"); } finally { output.close(); } 用si的file:outbound-channel-adapter管道,替代了FileOutputStreams或FileWriters的功能: 唯一需要你操心的只是组装这些组件、适当配置、兼顾读取端:文件用什么编码?、再一个就是读写互斥锁的问题,当你写一个大文件,怎么阻止读取端读取未完成的文件?最简单传统的方式就是文件写完了才移动到读取端监听的目录下或者重命名,file:outbound-channel-adapter也是首选改文件名:当它写文件时,会先打开一个临时文件、临时文件有一个后缀名,供读取端识别尚未写完的文件,这样写入端就可以安全地写入文件内容、写完之后对文件进行改名、就o了。 正式的文件名字由FileNameGenerator提供,你可以将其作为一个bean声明出来、再使用filename-generator属性做注入,spring老司机明白的这里你就可以自定义了,默认实现是:org.springframework.integration.file.DefaultFileNameGenerator,默认行为是如果找不到合适文件名那么就用消息ID,消息ID即UUID也就是生成文件是:UUID.msg. file:outbound-channel-adapter可接受的消息payLoad类型包括byte[], File(文件搬运)以及String,该配置元素代表文件出栈管道,EIP术语里这也是一种endpoint端点,端点包括输入和输出,概念涵盖更大一些,只要是和外部系统做IO的地方都是端点。该元素属性包括: 1、id: id和channel二选一必须有,The ID of the endpoint or the implicit channel leading to it 2、channel:把消息转换到文件的管道,可以不配置,有默认实现; 3、directory:写目录,这个必须的; 4、filename-generator:文件名生成规则,默认使用header或者是File对象的name,UUID; 5、delete-source-files:如果输入消息也是文件,那么写完会删除这个源头文件; 按照上述,一个最简文件出栈管道长这样: charset="UTF-8" directory="C:\....." auto-create-directory=""/> 有时候,你会遇到想要在代码里直接获取chennel Bean发送消息,那么可以首先实现ApplicationContextAware获取到context,然后这么写: MessageChannel channel =context.getBean("2GPMS", MessageChannel.class);//拿到通道 Message message = MessageBuilder.withPayload(payload).build();//构建消息,payload是文本格式的消息PayLoad. channel.send(message, 10000);//fire 当你遇到即需要把当前消息往后传递、继续处理,还需要马上给发送者一个合适的ack响应时,上述就有用了。进一步的,通过context可以做很多事: File inDir = (File)new DirectFieldAccessor(context.getBean(FileReadingMessageSource.class)).getPropertyValue("directory"); LiteralExpression expression = (LiteralExpression)new DirectFieldAccessor(context.getBean(FileWritingMessageHandler.class)).getPropertyValue("destinationDirectoryExpression"); File outDir =new File(expression.getValue()); System.out.println("Input directory is: " + inDir.getAbsolutePath()); System.out.println("Output directory is: " + outDir.getAbsolutePath()); 如上代码,才是spring的正确使用姿势。 在一些场景下你可能还得处理写完的文件,此时可以使用 既然是写文件,有可能遭遇的异常是IOException,比如说写磁盘出错了,si会抛出MessageDeliveryException(包含原始IOException),si允许你将此异常bubble up as a RuntimeException. 还一种异常情况是可能无意覆盖了已有文件,这个你就需要确保FileNameGenerator的文件名生成规则正确,规则就一条:不同的消息文件文件名要保证不同,DefaultFileNameGenerator可以保证在同一个Application Context下、文件名唯一。 文件这一章节,举的例子很像,是一个旅行日记Trip Diary、一个多客户端协作编写文本的例子,使用上述outbound adapter可以实现协作编辑器的增量保存功能,这要求文件可以正确识别以及有序,为此,文件名定义为客户端应用的key 进程ID(which is unique for each time the application context is loaded)加时间戳,你可以把文件名规则自定义为一个Bean比如叫做ChangeFileNameGenerator,然后组装它们: 在具备Spring插件的idea环境下,社区版企业版都可以选中上述某个属性点进去查看xsdDoc. 上述文件出栈的图形表示: Trip Diary module must read files from a directory to update the displayed diary with changes from other editors. 读写都有了,难点在于读文件端决定哪个文件以及何时可以开始读取,可以认为读文件端就像TCP监听一样监视一个目录,所谓监视即为周期性获取到该目录下的文件列表、判断哪一个是新出现的可以读取,看上去很简单实则不然,想象你正在监视一个目录,同时还有别人在往里拖放文件,一两个文件好说,当大批量文件同时刷新,哪个是哪个你就晕了。 默认情况下,si的文件入栈读取管道会对目录下出现的每个文件只获取一次,不会重复读取,你也可以自定义扩展FileListFilters. Java File API的核心是java.io.File,它是不可变的,意味着一旦创建再不会改变,这很好,特别是在并发处理当中,这一点给你省了不少麻烦,以File对象作为PayLoad的消息是绝对线程安全的。 读写管道如果都位于一个applicationContext,那么他们之间可以自动协作(也就是文件读写锁都有了);如果不是比如你是读端但是写端是第三方系统(If the writing isn’t under your control, though),那你只能继承AbstractFileListFilter 或实现 FileListFilter 去实现自定义的FileListFilter. si的文件支持内置FileToByteArrayTransformer 和 FileToStringTransformer可将文件转为byte[]或字符串。si file可以协助你方便地实现文件与消息之间的互相转换,但是针对文件的更复杂处理能力还是比不上专业文件处理工具如Spring Batch. 最后,所有组件都在spring context里,任何时候都可以直接拿到,进行操作(而且互相之间依然保持无耦合): MessageChannel channel =context.getBean("Channel Bean ID", MessageChannel.class); Message message = MessageBuilder.withPayload(payload).build(); channel.send(message, 10000);Can you be friends with the filesystem?
11.5 Under the hood
11.5.1 FRMS 读文件
文件排序
锁
11.2 Writing files 写文件