1.requests库安装
pip install requests
举例:
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200 #200表示成功
>>> r.encoding = "utf-8"
>>> r.text #打印网页内容
'\r\n 百度一下,你就知道 \r\n

这样,百度的主页已经成功被抓取下来了。
requests的7个主要的方法

2.requests库的get()方法


requests库get方法的源代码

所以,requests库的get()方法实际上是调用requests库的request的方法来实现的
所以,虽然requests库有7中方法,但是实际上可以把它理解成一种方法,也就是request的方法。

重点看一下response对象




原则上,r.apparent_encoding 是比r.encoding更为准确的一种形式
3.爬取网页的通用代码框架
6种常见的requests库的连接异常




通用代码框架使得用户爬取网页更加可靠,有效,稳定
3.HTTP协议以及request库方法
HTTP协议:超文本传输协议

简单的说,就是用户发起请求,服务器发生响应,这就是简单的请求与响应模式







r.headers反馈得到的头部信息
当试图展示全部内容,用r.text,结果为空



4.requests库主要方法的解析
















5.爬取实例
(1)京东商品页面的爬取

(2)亚马逊商品页面的爬取



亚马逊的服务器识别了这次访问是由requests库的爬虫引起的
所以
先构建一个键值对
重新定义了user-agent,使它等于Mozilla/5.0

对headers进行修改

这时候,user-agent就变成了Mozilla/5.0
返回的结果


(3)百度360搜索关键词提交




(4)网络图片的爬取和储存


(5)IP地址归属地的自动查询
6.Beautiful Soup库的安装
pip install beautifulsoup4


两种方式获取源代码
1是可以直接浏览器上查看网页源代码

2是可以用requests

除了给出demo,还需要给出一个解析demo的解释器,这里的解释器是html.parser,也就是说我们这里是对demo进行html的解析

beautifulsoup库只需要2行代码

7.Beautiful Soup库的基本元素

任何的html文件都是由一组尖括号组成的标签组织起来的,每一对尖括号构成一个标签,而标签之间存在上下游关系,形成一个标签树






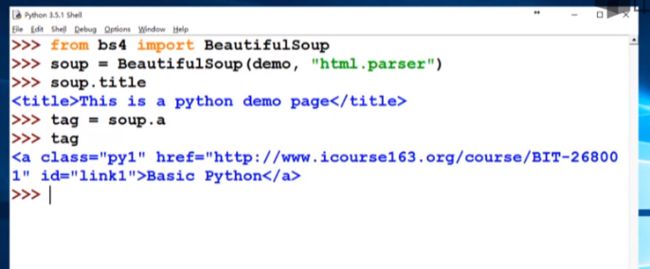
使用soup.title可以获得title信息
使用soup.a获得a标签的tag
当html中包含多个相同的tag时,使用soup.tag是会获得第一个tag信息

soup.a.name获得a标签的名字
soup.a.parent.name获得a标签的父亲的名字,也就是包含a标签的上一级标签的名字
soup.a.parent.parent.name同理,获得的是上上级标签的名字

tag.attrs获取tag的属性信息,可以看出来它是一个字典,存在键值对
因此,可以用
tag.attrs['class']来获得class属性的值
tag.attrs['href']来获得href属性的值
type(tag.attrs)可以获得属性的类型,它是一个dict
type(tag),获取tag的类型信息

soup.a.string获得tag a的NavigableString
可以看出,p标签中还包含一个b标签
因此,soup.tag.string可以跨标签获得标签的NavigableString
比如


beautiful soup的comment信息
8.基于bs4库的HTML内容的遍历方法



要注意的是,contents返回的是列表,而children和descendants返回的是迭代类型,需要for循环输出










9.基于bs4库的HTML格式输出

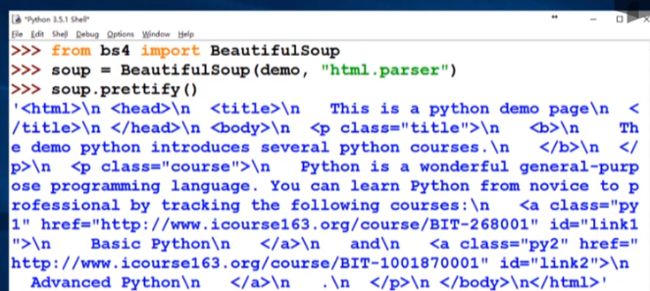

print之后都分行显示


10.信息标记的三种形式
















11.三种信息标记形式的比较





12.信息提取的一般方法





13.基于bs4库的HTML内容查找方法



如果给find_all的参数是True,将返回所有的标签信息










14.中国大学排名定向爬虫实例
(1)实例介绍






(2)中国大学排名定向爬虫实例代码编写
import requests
import bs4
import requests
import bs4
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr("td")
ulist.append([tds[0].string,tds[1].string,tds[2].string])
def printUnivList(ulist,num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range (num):
u = ulist[i]
print ("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
main()
结果如下
排名 学校名称 总分
1 清华大学 北京市
2 北京大学 北京市
3 浙江大学 浙江省
4 上海交通大学 上海市
5 复旦大学 上海市
6 南京大学 江苏省
7 中国科学技术大学 安徽省
8 哈尔滨工业大学 黑龙江省
9 华中科技大学 湖北省
10 中山大学 广东省
11 东南大学 江苏省
12 天津大学 天津市
13 同济大学 上海市
14 北京航空航天大学 北京市
15 四川大学 四川省
16 武汉大学 湖北省
17 西安交通大学 陕西省
18 南开大学 天津市
19 大连理工大学 辽宁省
20 山东大学 山东省
(3)中国大学排名定向爬虫实例优化
问题:

结果的中文不对齐

