该文章所有内容截选自实验楼教程【Spark2.x 快速入门教程】第二节内容~
一、实验介绍
1.1 实验内容
从 Spark 2.0 始支持了SQL 2003 准语法。当我们使用某种编程语言开发的 Spark 作业来执行 SQL 时,返回的结果是 Dataframe/Dataset 类型的。
本节课我们将通过 Spark Sql 的 shell 命令行工具进行 Dataframe/Dataset 操作,以加深对 Spark 2.0 Sql 的理解,并在此基础上学以致用。
1.2 先学课程
- Scala 请参考:http://www.scalachina.com/
- 更详细的学习请参考: https://www.shiyanlou.com/courses/?course_type=all&tag=Scala&fee=all
1.3 实验知识点
- Dataframe/Dataset 介绍
- SparkSession
- Dataframe/Dataset 案例操作
1.4 实验环境
- Hadoop 2.6.1
- spark-2.1.0-bin-hadoop2.6.tgz
- Xfce 终端
1.5 适合人群
本课程属于中等难度级别,适合具有大数据基础的用户,如果对 Spark Sql 了解能够更好的上手本课程。
二、实验步骤
2.1 准备工作
双击打开桌面上的 Xfce 终端,用 sudo 命令切换到 hadoop 用户,hadoop 用户密码为 hadoop,用 cd 命令进入 /opt 目录。
$ su hadoop
$ cd /opt/
在 /opt 目录下格式化 hadoop。
$ hadoop-2.6.1/bin/hdfs namenode -format

在 /opt 目录下启动 hadoop 进程。
$ start-all.sh

用 jps 查看 hadoop 进程是否启动。

2.2 SparkSession 介绍
Spark SQL 统一入口就是 SparkSession,可以通过 SparkSession.builder()
来创建一个 SparkSession,有了 SparkSession 之后,就可以通过已有的 RDD,Hive 表,或者其他数据源来创建 Dataframe。由于本节课基于 Spark SQL 的 shell 命令行操作,所以在此仅此一提,在以后使用 Eclispe 等开发工具时再使用。
2.3 Dataframe
我们可以理解为 Dataframe 就是按列组织的 Dataset,在底层做了大量的优化。Dataframe 可以通过很多方式来构造:比如结构化的数据文件,Hive表,数据库,已有的 RDD,Scala,Java,Python,R 等语言都支持 Dataframe。Dataframe 提供了一种 domain-specific language 来进行结构化数据的操作,这种操作也被称之为 untyped 操作,与之相反的是基于强类型的 typed 操作。
准备数据 person.json,并上传至 hdfs,person.json 数据如下:
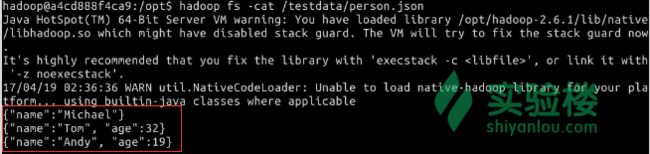
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
用mkdir命令在 hdfs 文件系统上创建 testdata 文件夹,并上传person.json。
hadoop fs -mkdir /testdata
sudo vi person.json
hadoop fs -put person.json /testdata
执行命令
hadoop fs -cat /testdata/person.json
查看内容
在 /opt 目录下启动 Spark。
$ spark-2.1.0-bin-hadoop2.6/sbin/start-all.sh

用 jps 查看 spark 进程是否启动

在 spark 的 bin 目录下启动 spark-shell。
$ cd spark-2.1.0-bin-hadoop2.6/bin
# a4cd888f4ca9 是主机名,要与您 hostnane 显示的名字一致
$ ./spark-shell --master spark://a4cd888f4ca9:7077

读取 json 文件,构造一个 untyped 弱类型的 dataframe。
$ val df = spark.read.json("hdfs://localhost:9000/testdata/person.json")

对数据进行操作。
$ df.show() //打印数据
$ df.printSchema() // 打印元数据

$ df.select($"name", $"age" + 1).show() // 使用表达式,scala的语法,要用$符号作为前缀
$ df.select("name").show() // select操作,典型的弱类型,untyped操作

$ df.createOrReplaceTempView("person") // 基于dataframe创建临时视图
$ spark.sql("SELECT * FROM person").show() // 用SparkSession的sql()函数就可以执行sql语句,默认是针对创建的临时视图
2.4 Dataset
Dataset 的序列化机制基于一种特殊的 Encoder,来将对象进行高效序列化,以进行高性能处理或者是通过网络进行传输。
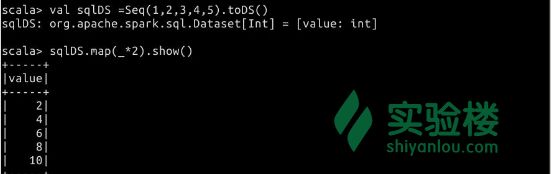
基于原始数据类型构造 dataset。
$ val sqlDS = Seq(1, 2, 3, 4, 5).toDS()
$ sqlDS.map(_*2).show()
基于已有的结构化数据文件,构造 dataset。
$ case class Person(name: String, age: Long)
$ val pds = spark.read.json("hdfs://localhost:9000/testdata/person.json").as[Person]
$ pds.show()

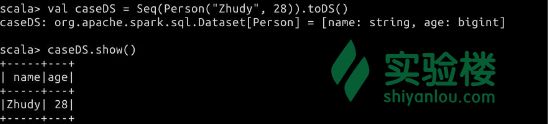
直接基于 jvm object 来构造 dataset。
$ val caseDS = Seq(Person("Zhudy", 28)).toDS()
$ caseDS.show()
若想要退出终端,可以用 :quit。
三、综合案例分析
现有数据集 department.json与employee.json,以部门名称和员工性别为粒度,试计算每个部门分性别平均年龄与平均薪资。
department.json如下:
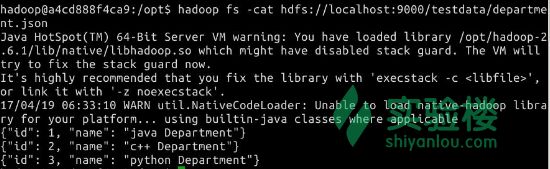
{"id": 1, "name": "Tech Department"}
{"id": 2, "name": "Fina Department"}
{"id": 3, "name": "HR Department"}
employee.json如下:
{"name": "zhangsan", "age": 26, "depId": 1, "gender": "male", "salary": 20000}
{"name": "lisi", "age": 36, "depId": 2, "gender": "female", "salary": 8500}
{"name": "wangwu", "age": 23, "depId": 1, "gender": "male", "salary": 5000}
{"name": "zhaoliu", "age": 25, "depId": 3, "gender": "male", "salary": 7000}
{"name": "marry", "age": 19, "depId": 2, "gender": "female", "salary": 6600}
{"name": "Tom", "age": 36, "depId": 1, "gender": "female", "salary": 5000}
{"name": "kitty", "age": 43, "depId": 2, "gender": "female", "salary": 6000}
两份数据我已经创建并上传至 hdfs 文件系统,请自行创建。
执行命令
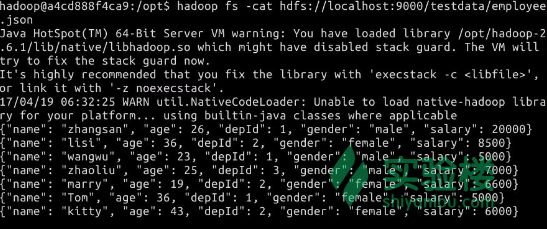
hadoop fs -cat hdfs://localhost:9000/testdata/department.json
hadoop fs -cat hdfs://localhost:9000/testdata/employee.json
查看内容
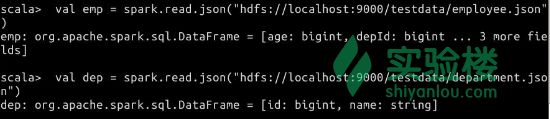
1). 加载数据
$ val emp = spark.read.json("hdfs://localhost:9000/testdata/employee.json")
$ val dep = spark.read.json("hdfs://localhost:9000/testdata/department.json")
2). 用算子操作
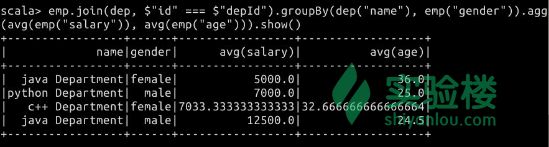
需要两个表进行 join 操作才能根据部门名称和员工性别分组再进行聚合,具体如下:
# 注意:两个表的字段的连接条件,需要使用三个等号
$ emp.join(dep, $"id" === $"depId") .groupBy(dep("name"), emp("gender")).agg(avg(emp("salary")), avg(emp("age"))).show()
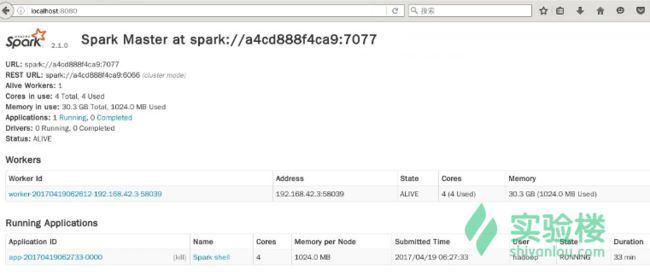
双击打开浏览器,输入 localhost:8080
可以看到 workers 节点,当前正在进行的 Runnign Applications,即为我们的开启的 spark-shell 命令行工具。
输入: localhost:4040,可以看到已经完成的 Jobs。
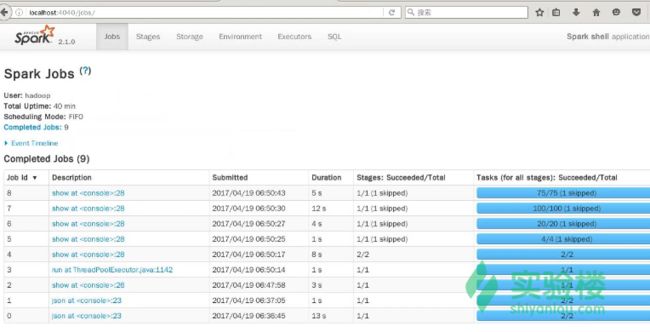
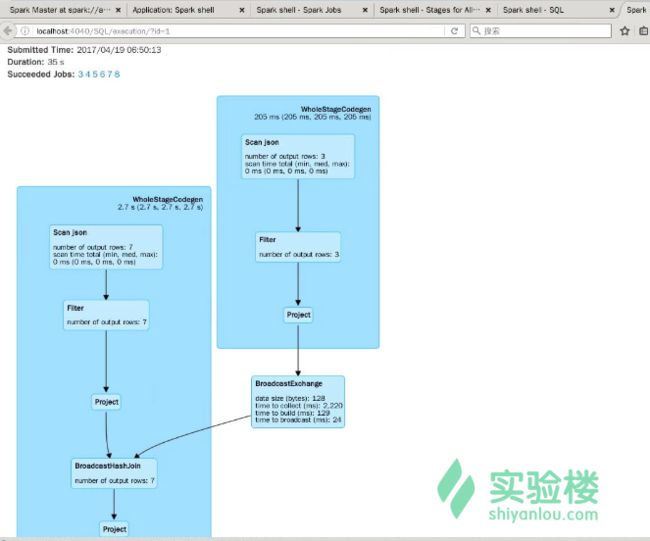
继续点击 SQL ->可以看到 Completed Queries,点击任意一个可以看到执行计划,当然还有更多的信息,您可以继续查看,在此不一一举例。
四、实验总结
本节课主要介绍了 Dataframe/Dataset,并进行一些较为简单的 SQL 操作,最后基于一个小案例讲解,并就 Spark 的 WebUi 进行介绍,希望学完本节课,能对您学习 Spark SQL 有一个更清晰地认识。
五、扩展阅读
- http://spark.apache.org/docs/latest/quick-start.html
- http://spark.apache.org/docs/latest/sql-programming-guide.html
说明
实验楼教程【Spark2.x 快速入门教程】总共7节内容,该文章是第二节内容,7节内容分别是:
- Spark2.x 新特性
- Spark SQL
- Hive on Spark
- Structured Streaming
- Spark 处理多种数据源
- Streaming 整合 Flume
- Streaming 整合 Kafka
如果想要查看全部内容,点击【Spark2.x 快速入门教程】即可~