今天有空将电脑配置完成,这里我稍微整理一下,为下一次配置留个记录,顺便分享一下成果。
目录:
I. 开始前的电脑配置和环境
II. 双系统安装(win10+linux mint都装在ssd,EFI引导)
III. GTX1070驱动
IV. CUDA9.0
V. cuDNN7.0
VI. Anaconda
VII. Tensorflow-GPU
VIII. Pycharm
VIIII. 测试
I. 开始前的电脑配置和环境
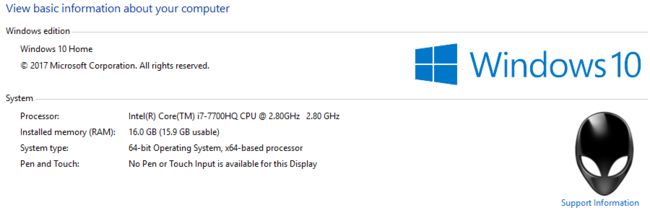

美行外星人,本身有出厂安装的win10 64位家庭版正版,win10装在了SSD上,配载了7代i7,GTX1070显卡,有一个128g的SSD和一个1T的机械硬盘,内存是16g的。
买时的目的就是为了在笔记本电脑中配置一个个人的深度学习工作站,同时闲暇时候也能兼顾玩一些大型的游戏,虽然不是最贵的顶配,而且是8代u出了以后,打折促销处理的7代u版,但价格非常美好,且配置已经能很好地完成我的目标了。
另外,电脑的硬盘是GPT格式的,启动也是UEFI模式,这就给安装双系统增加了不少难度,easyBCD什么的已经无法使用了,而且一定要用掉一个U盘作为启动盘,至少我暂时没有找到不需要报废U盘的办法。
另整个流程都是在实际电脑中完成,不是在虚拟机中,请确认你是装机老手,不然还是在虚拟机里练一下吧。
II. 双系统安装(win10+linux mint都装在ssd)
- 准备工作:
- 一个空的U盘
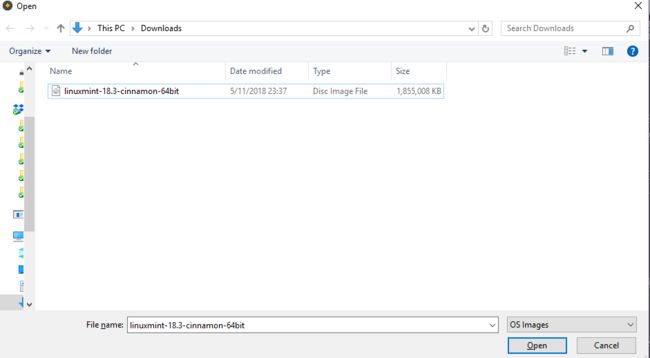
(在不得不耗费一个U盘前,我尝试了许多方法,试图从硬盘安装,还研究了下怎么从network安装,但无果,最后只能将一个8g的U盘作为启动盘了。) - linux mint官网下载iso镜像(https://linuxmint.com/download.php)

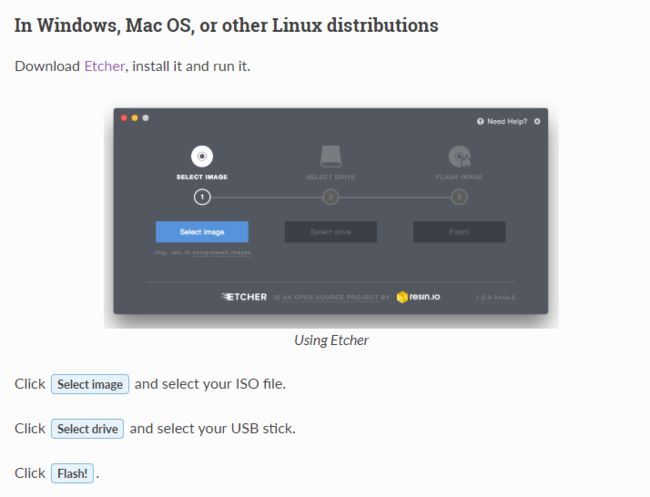
选择红框64位版,还有一步是选择合适的镜像,这个选恰当的就行了,我自己在美国,所以随手选了个USA的,速度还是很快的5分钟左右就下完了。 - linux mint官网推荐的镜像制作软件Etcher(https://etcher.io/)
- 一个空的U盘
接下来:
1.制作Linux Mint启动盘
-
安装Etcher后打开,和官网给的步骤一样,点击Select Image按钮,选中下载下来的iso镜像,插入空U盘,Etcher会自动检测到U盘,然后点Flash!
- 轻松加愉快,启动盘就制作完成了。Etcher制作完启动盘后会自动弹出U盘,所以直接拔下就可以了。
- 调整硬盘分区
右键资源管理器中的This PC/此电脑-管理-磁盘管理,打开windows里的磁盘管理器.
-
发现原本的电脑SSD盘128G,出厂时划分为了一个主分区装了win10和N块recovery的区域,机械硬盘作为数据盘,没有分区。

我的目标是win10不变将linux mint的系统装到SSD里的空余位置,其它的分区装在机械硬盘上,同时Linux和Win10共用机械硬盘里的数据,所以这里要把SSD里的隐藏恢复分区没有用的给删掉,只保留EFI分区和安装了win10的C盘。
好吧,128g的SSD还是太小了,家境好的还是选大些的SSD~等我有空也要再换一块。
打开Terminal:
1.C:\Users\manim>diskpart
2.DISKPART> list disk
Disk ### Status Size Free Dyn Gpt
-------- ------------- ------- ------- --- ---
Disk 0 Online 119 GB 1024 KB *
Disk 1 Online 931 GB 0 B *
3.DISKPART> select disk 0(选中SSD盘)
Disk 0 is now the selected disk.
4.DISKPART> list partition(查看分区)
5. DISKPART> select partition N(其中N是查看的分区编号,这一步代表你选中了分区)
Partition N is now the selected partition.
6.DISKPART> delete partition override(做这一步之前请谨慎确认选中的分区是无用的,且里面没有重要数据,否则删除后很难恢复)
DiskPart successfully deleted the selected partition.
接下来直接在windows的磁盘管理中,将ssd里分出一个10g大小的freespace即未分配区,机械硬盘里分出一个约400~500g大小的freespace即未分配区,保证主要进行深度学习工作的linux系统里有足够的空间。
将新卷变为未分配区的方法很简单,删除卷标就行了,最后将10G+450G的空间保持在‘未分配空间’的状态,也就是黑色。
- 设置BIOS
- 重启电脑,在启动界面猛按或长按某一个神秘按键,进入BIOS。这个按键不同的厂不一样,可能是F2,F10或DEL,一般都是这三个,不确定的话根据电脑自己google一下吧。
- 这里有三件事要完成:
- 将security boot关闭,设置成disabled,False,off之类的。
- 保持UEFI不变,但将快速boot之类的关闭,切记,千万不要弄巧成拙改成legacy。
- 将UEFI的USB启动设置为自动启动第一位序,如果没有该选项的话,可以在开机时长按F12之类的按键,自选boot方式。
- 重新启动电脑,选择UEFI下的USB启动选项,注意该选项会标注时UEFI模式。
- 绕开因显卡而死机的危机
- 原本进行完第三步,理所应当从USB启动,click,click,click下去,就能安装好Linux了,然而这里我却遇到了个相当令人烦躁的bug——Ubuntu不支持Nvidia的主流显卡——所以会各种卡在安装界面、logo界面、进度条界面……这也一度让我对外星人灯厂表示失望,当然,最后发现是Ubuntu的问题,和外星人无关。

- 官方的解释是,有一些显卡和主板不能够很好地在默认的Linux MInt环境的开源驱动下工作。
这里参考了linux mint官方文档,完美解决了这个问题。
解决方案一(官方推荐):
- 在安装时主动选择boot的选项,长按F12就可以进入主动选择boot选项的页面,选择usb boot,来到USB安装界面
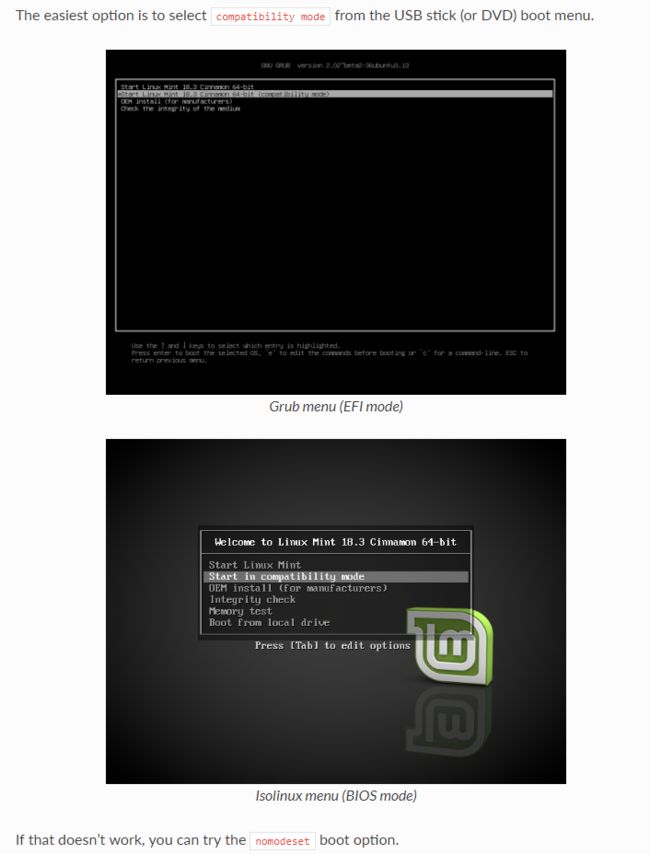
- 在USB安装界面选择
compatibility mode -
跑完流程后,系统会自动进入到安装界面
解决方案二(如果方案一帮不了你的话):
- 同样是在USB安装界面
- 按
e修改boot选项 - 将其中
quiet splash --的文本,替换为nomodeset - 最后按
F10就可以了
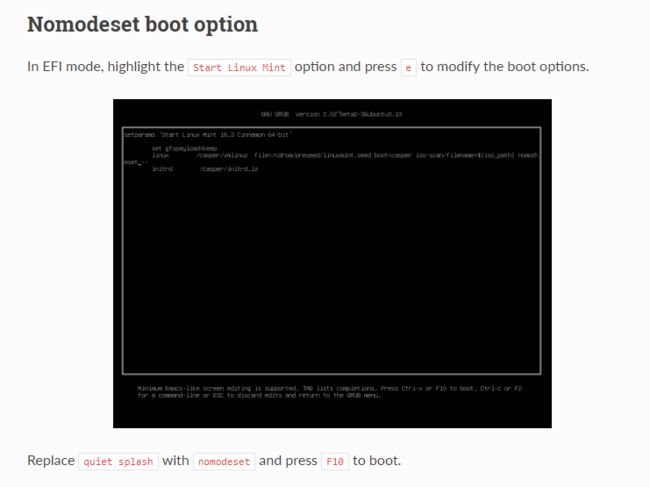 image.png
image.png
验证:
- 成功标志1:进入系统后会呈现很辣鸡的显示效果,一点和1080P及GTX高端卡不匹配,估计就是几代前的旧电脑的显示效果。
-
成功标志2:在点击开始安装系统后,能够看到linux系统的介绍广告,鼠标可以移动,不会卡住,进度条也继续往下走,还可以开火狐浏览器浏览网页。
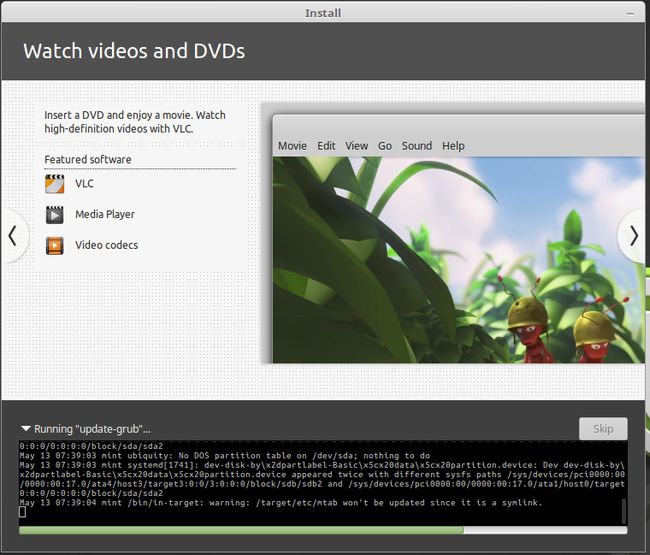
- ps:如果该成功的标志没有出现,强制关机,重新来一次吧!
- 安装Linux Mint
终于,我们可以开始安装Linux Mint了,这一步需要注意三点。
-
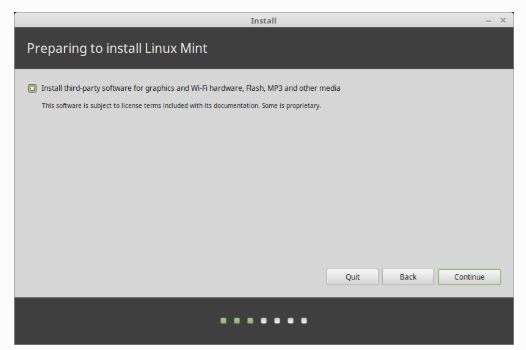
如果你赶时间,记得不要联网,也不要选择
Install third-party software那个选项,因为联网后会自动安装更新和驱动等,反之就自由选择,如果不联网,不选这个选项10分钟能跑完系统安装。
-
记得不要选择清除windows!也不要选择与什么一起共存的选项!切记要选择
Something else。
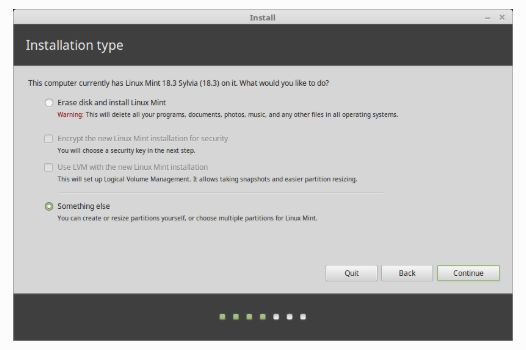
- Linux分区计划
- 因为我的目的是主要用linux来运行深度学习的工作,所以一些基本的软件譬如anaconda3,cuda9.0, cuDNN7.1, tensorflow-gpu, pandas, numpy ……等python的包,都要装上。
- 其中anaconda3在安装时默认装在/home分区,cuda和cuDNN都是装在/usr分区,python包是以anaconda3来管理,所以anaconda3装在哪,包就会在哪。以后写的程序和Project的临时文件一般都会存在/home里,当然,可以用github来管理,但本地还是会占用空间的。
- 另外虽然linux也可以调用SSD和机械硬盘里的数据,但运行的时候数据放在相同目录下还是会方便些,所以还要留出一定大小的空间直接放数据。
- 综上,我的分区计划如下:
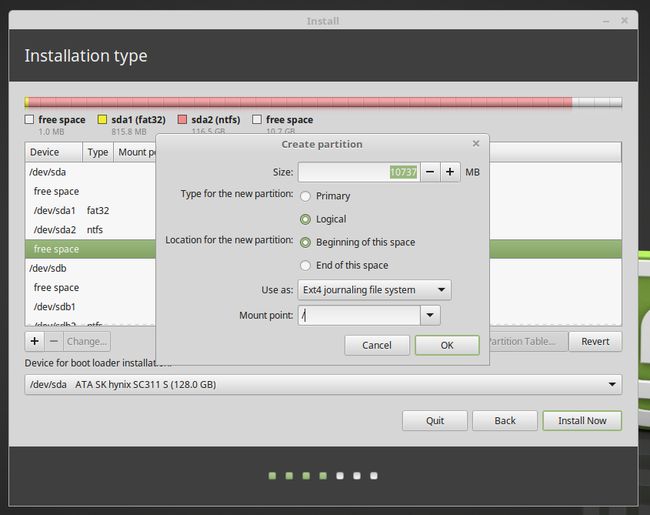
/boot不需要,我们把引导项和windows放在一起,因为是先有的win10再装的linux,所以win10不会覆盖掉,注意等会儿boot挂在时挂到SSD中的EFI分区上即可。
/ext4格式,logical,这个是系统所在的根目录,留下10g给linux系统以及一些杂七杂八的分区足矣。
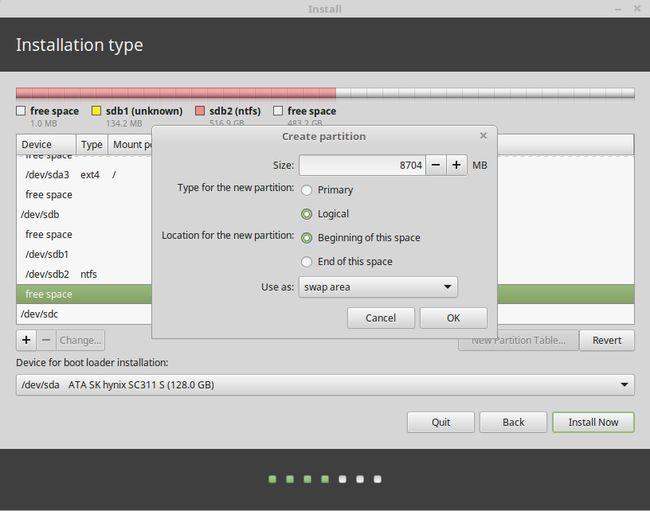
swap area交换空间,这个空间即你的虚拟内存,在物理内存用尽后,溢出的部分才回到虚拟内存中。该空间太大没用,太小又不行,根据内存大小选择,一般不要小于本身内存的一半,若是本身内存太小,可以设置大些。我的内存是16g,留下8g足够了。
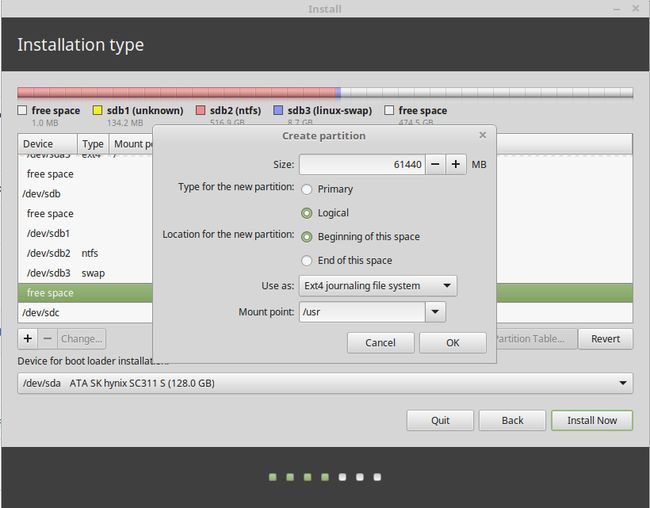
/usr默认软件安装空间,软件默认的安装位置都在这个区,因为要装pycharm和cuda、cuDNN,我留了60g。
/home将余下的freespace都给了Home空间,这个相当于是windows系统中的user区域,anaconda3,文档,日志等默认的位置都在这里,以后数据也都放这里,留多些没坏处。
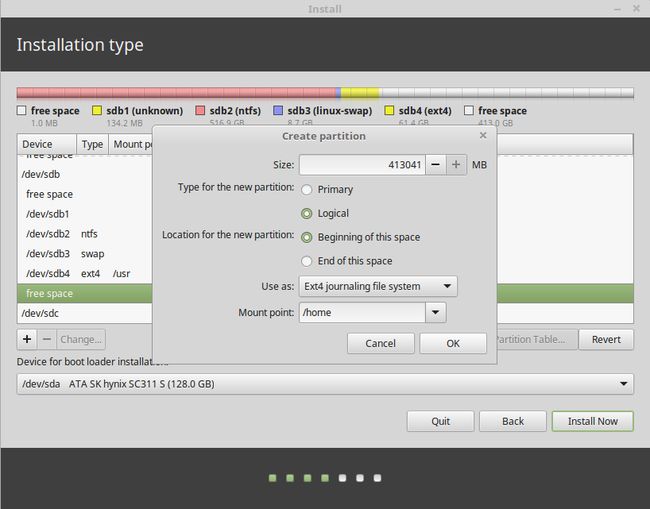
- 当然,还有更多的譬如
/var之类的区域,我没有一一细分,这些都会挂在根目录/下面。 - 接下来,将
boot挂到/dev/sda(x),这里的x指windows系统放置了引导项的EFI分区编号一般应该不是0就是1,后面会有windows boot manager的后缀,就可以点击开始安装了。 - 如果不联网的话安装过程在10分钟左右。
III. GTX1070驱动
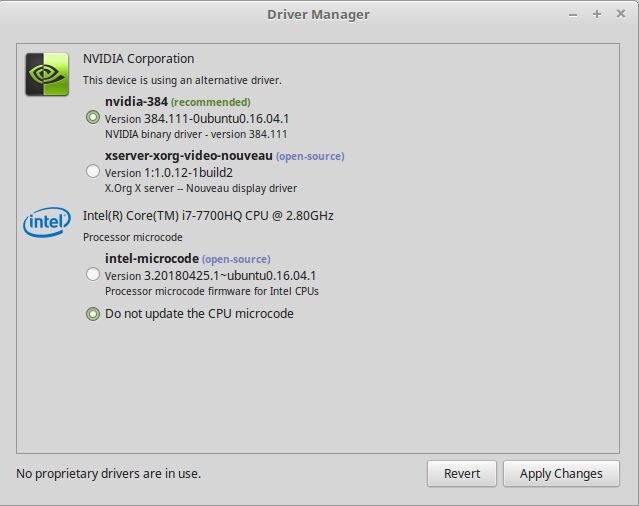
- 用linux自带的驱动管理安装最新的驱动即可
-
菜单-设置-驱动管理-384版最新驱动
IV. CUDA9.0
- 在官网下载CUDA9.0,选择Ubuntu16.04版,下载
- 在
Download目录打开Terminal,逐一输入以下代码
ps: 所有代码摘抄修改自官方指导:
1. sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb
2. sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
3. sudo apt-get update
4. sudo apt-get install cuda
5. export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
6. export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
7. export CUDA_HOME=/usr/local/cuda
8. sudo ln -s cuda-9.0 cuda
- 完成
V. cuDNN7.0
- 在官网下载cuDNN7.0,这里注意,tensorflow暂时还未支持7.1,所以我下载的还是7.0版本,要下载cuDNN还需要用邮箱注册一下,登录后才能下载,这个就注册下好了。
- 下载cuDNN v7.0.5 Library for Linux就可以了。
- 下好后同样在
Download打开terminal,逐一输入以下代码:
ps: 同样,参考官方指导
1. tar -xzvf cudnn-9.0-linux-x64-v7.tgz
2. sudo cp cuda/include/cudnn.h /usr/local/cuda/include
3. sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
4. sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
5. export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64export
6. CUDA_HOME=/usr/local/cuda
- 完成了
VI. Anaconda
- 在官网下载linux版的Anaconda3.6
- 在Download目录下打开terminal,逐一输入:
1. bash ~/Downloads/Anaconda3-5.1.0-Linux-x86_64.sh
2. 点击N次回车[Enter]
3. yes
4. 再点击一次回车[Enter]
5. yes
- 可以尝试下能否打开
1. source ~/.bashrc
2. anaconda-navigator
-
安装完成
VII. Tensorflow-GPU
- 接下来我们开始安装Tensorflow-gpu版本,这次安装的是最新版tensorflow1.8
- 打开anaconda的terminal,输入:
1. sudo apt-get install python3-numpy python3-dev python3-pip python3-wheel
2. sudo apt-get install libcupti-dev
3. pip install --upgrade -I setuptools
4. conda create -n tensorflow python=3.6
5. conda activate tensorflow
6. pip install --ignore-installed --upgrade \
https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.8.0-cp36-cp36m-linux_x86_64.whl
- 完成
随手在terminal试验下:
python
import tensorflow as tf
# Creates a graph.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(c))

VIII. Pycharm
- 接下来我们装一个python的IDE,先去官网下个Pycharm
- 下载好以后,根据官网指导安装一下。
- 先在
/usr目录,或其他你想要安装的目录下解压下载的包,进入pycharm的bin目录,打开terminal,输入sh pycharm.sh就能进入pycharm - 如果要用github的话记得下载git:
1. sudo apt-get install git
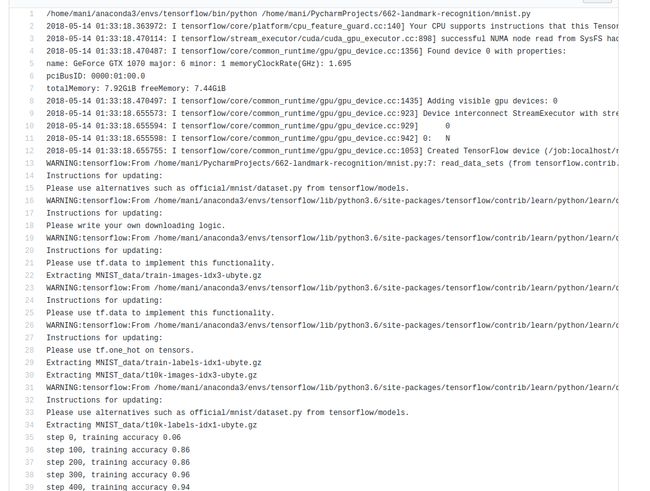
VIIII. 测试
- 最后,测试一下整个环境是否配置完成,我们运行一个minisize的训练计划吧。
- minst的20000个epoches跑了86秒,可以说速度贼快了。
import tensorflow as tf
import datetime
#Start interactive session
sess = tf.InteractiveSession()
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
width = 28 # width of the image in pixels
height = 28 # height of the image in pixels
flat = width * height # number of pixels in one image
class_output = 10 # number of possible classifications for the problem
x = tf.placeholder(tf.float32, shape=[None, flat])
y_ = tf.placeholder(tf.float32, shape=[None, class_output])
x_image = tf.reshape(x, [-1,28,28,1])
W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev=0.1))
b_conv1 = tf.Variable(tf.constant(0.1, shape=[32])) # need 32 biases for 32 outputs
convolve1= tf.nn.conv2d(x_image, W_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1
h_conv1 = tf.nn.relu(convolve1)
conv1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #max_pool_2x2
W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1))
b_conv2 = tf.Variable(tf.constant(0.1, shape=[64])) #need 64 biases for 64 outputs
convolve2= tf.nn.conv2d(conv1, W_conv2, strides=[1, 1, 1, 1], padding='SAME')+ b_conv2
h_conv2 = tf.nn.relu(convolve2)
conv2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #max_pool_2x2
layer2_matrix = tf.reshape(conv2, [-1, 7*7*64])
W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024])) # need 1024 biases for 1024 outputs
fcl=tf.matmul(layer2_matrix, W_fc1) + b_fc1
h_fc1 = tf.nn.relu(fcl)
keep_prob = tf.placeholder(tf.float32)
layer_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1)) #1024 neurons
b_fc2 = tf.Variable(tf.constant(0.1, shape=[10])) # 10 possibilities for digits [0,1,2,3,4,5,6,7,8,9]
fc=tf.matmul(layer_drop, W_fc2) + b_fc2
y_CNN= tf.nn.softmax(fc)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_CNN), reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_CNN,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.global_variables_initializer())
starttime = datetime.datetime.now()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
endtime = datetime.datetime.now()
print('Time use:',(endtime - starttime).seconds, 's')