正则表达式,是用来匹配文件里的文本内容的字符串;文件通配符,是用来匹配文件名称的。
正则表达式REGEXP:由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符),不表示字符字面意义,而表示控制或通配的功能。
程序支持:grep,sed,awk,vim, less,nginx,varnish等
正则表达式可以分两类: 1、基本正则表达式:BRE 2、扩展正则表达式:ERE
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块【PCRE模块】
PCRE(Perl Compatible Regular Expressions)
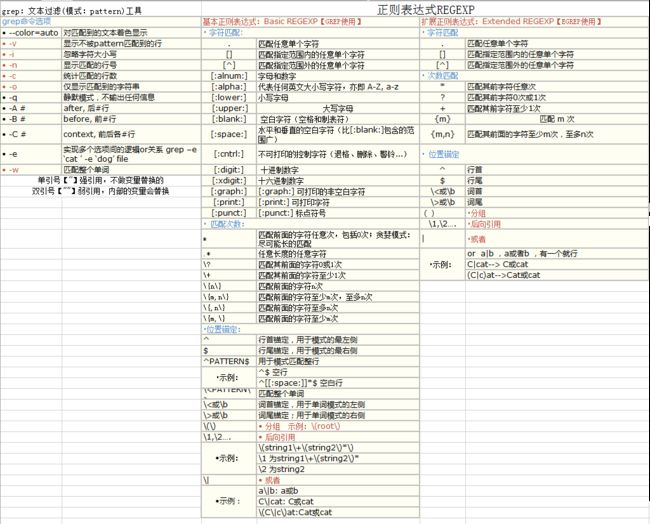
元字符分类:字符匹配、匹配次数、位置锚定、分组【见图】
帮助:man 7 regex
---------------------------------------------------------------------------------------
字符匹配实例:
echo abbc | grep a..c #匹配a..c
ls |grep -w "..." #匹配
ls |grep -w ".\.." # \.转义,转换为字符的本身的含义。
grep "r..t" /etc/passwd #
[root@centos7 app]# echo axcdef |grep "a[xyz]c" #取括号内任意一个字符匹配
[root@centos7 app]# echo abcdef |grep "a[^xyz]c" #排除括号内的字符
次数匹配实例:
echo axxxb |grep "ax*b"
ls | grep ".*\.txt"
echo abccdd | grep "a[a-z]*c" #
echo abccdd | grep "a[a-z]\?c" #
实验:#文件内容# cat google.txt
--------------------------------------
goooooooooooooogle
gogle
goooooooooooooooooooooooogle
ggle
goooooooOOOOOOoooole
----------------------------------------以下是匹配以上内容--------------------
grep "go\?gle" google.txt #匹配前面的o字符0次或1次
grep "go\+gle" google.txt #匹配前面的o字符至少1次及1次以上
echo "1abx" | grep "[a-z.]\+" #在中括号内.不需要转义
grep "go\{14\}gle" google.txt #精确匹配前面的o字符14次
grep "go\{2,\}\gle" google.txt #显示匹配前面的o字符至少2次
grep "go\{10,20\}\gle" google.txt #匹配前面的o字符至少10次,至多20次
grep "go\{,10\}\gle" google.txt #显示匹配o字符至多10次
位置锚定实例:
[root@centos7 app]# grep "^root" passwd
[root@centos7 app]# grep "bash$" passwd
[root@centos7 app]# grep -v "^#" /etc/fstab | grep -v ^$
[root@centos7 app]# grep -v "^[[:space:]]*$" f1 #过滤空行
[root@centos7 app]# grep "\" passwd #匹配右侧
[root@centos7 app]# grep "\" passwd #匹配整个单词
[root@centos7 app]# grep "\ 分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理 后向引用:\1,\2,\3........... 或者:\| 实例: [root@centos7 app]# echo wangwangwang | grep "\(wang\)\{3\}" [root@centos7 app]# grep "^\(.*\):.*/\1$" passwd #开头"^\(.*\): 中间.* 结尾\1$" [root@centos7 app]# grep "^a\|^b.*" passwd [root@centos7 app]# grep "^\(a\|b\).*" passwd #开头^ 中间分组\(a\|b\) 结尾 .* [root@centos7 app]# echo bxy | grep "\(a\|b\)xy" #\(a\|b\)xy为分组,表示axy或bxy 综合实例: [root@centos7 app]# grep -o " [0-9]\+" /etc/redhat-release |grep -o "[0-9]\+" #获取Linux版本号 [root@centos7 app]# cat passwd |grep "^\(\\).*\([0-9]\+\):\2.*\1$"