ASCII,Unicode,utf-8等字符编码学习笔记
学习自阮一峰的网络日志,地址http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
1. ASCII码
这个主要是对英语字符与二进制的关系做的标准,一共规定了128个字符的编码,比如空格是32,二进制是00100000,大写字母A是65,二进制01000001,所以总共占据一个字节后面7位,最前面的1为统一为0.
2. Unicode
Unicode编码是为了适应世界上的各个编码方式,因为同一个二进制数字由于不同的编码方式会被解释成不同的符号。Unicode将世界上所有的符号都纳入其中,每一个符号都给予了独一无二的编码,就像它的名字一样,unique code。
Unicode是一个很大的集合,现在规模可以容纳100多万个符号,每个符号的编码都不一样。
\uxxxx这种格式是Unicode写法,表示一个字符,其中xxxx表示一个16进制数字,范围为0~65535,Unicode十六进制数只能包含数字0-9,大写字母和小写字母a-f。
另外Unicode的大小端问题:一般都是小端
但是Unicode只规定了符号的二进制代码,并没有规定二进制代码该如何存储。比如给定一个二进制代码,计算机如何才能知道三个字节表示一个符号还是分别表示三个符号呢。并且对于单纯的英文字母,一个字节就够了,但是如果Unicode规定每个符号使用四个字节的话,岂不是造成极大的浪费。
3. utf-8
因此出现了utf-8这种Unicode的实现方式,注意,utf-8是Unicode的实现方式之一,其他实现方式还有utf-16,utf-32。
utf-8是一种变长的编码方式,使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
它的规则有两条:
单字节符号,字节的第一位设为0,后面7位为这个符号的Unicode码,所以对于英文,utf-8和ASCII码是相同的。
对于n字节符号,第一个字节的前n为都为1,第n+1位设为0,后面字节的前两位设为10,剩下没有提及的二进制位,全部为这个符号的unicode码。
比如汉字“严”,Unicode码是4E25(100111000100101),使用三个字节存储,因此它的utf-8码,应该是11100100 10111000 10100101,转换成16进制就是E4B8A5
4. 大端和小端
大端小端是相对于Unicode码而言的。有Unicode little endian格式和Unicode big endian格式。
同样对于汉字“严”,Unicode码是4E25,如果按照4E存储在前,25存储在后,就是Big endian方式,如果25在前,4E在后就是little endian方式。
本质上是,大端模式:数据的高位存在低地址,低位存在高地址,比如4E25,4E就存放在了分配的内存低地址上。小端模式是数据的高位存放在高地址,低位存在低地址,比如254E,25为低位,刚好存在了内存的低地址上。
对于一个文件,在最前面加入一个表示编码顺序的字符,这个字符叫做零宽度非换行空格,FEFF表示,如果文件头两个字节是FEFF就是大端方式,如果是FFFE的话就是小端方式。
5. 在Python程序中处理编码问题
在百度贴吧网络爬虫中(地址:https://github.com/Microndgt/PythonLearning/tree/master/baiduTieba),获取到的文本是utf-8编码的,如下图所示
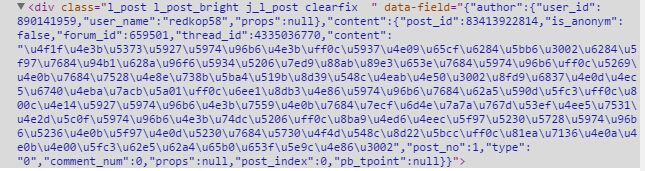
通过下面代码获取到网页的源代码:
equest=urllib2.Request(url)
#发送该request请求
response=urllib2.urlopen(request)
return response.read()
此时的数据也都是utf-8编码的,接下来通过一系列的正则表达式匹配后,找到帖子的标题title,当然title也是utf-8编码的。
这时候需要将匹配到的帖子内容存入文件,想将title作为文件名,此时就会出现问题,文件名会乱码,但是文件内容并不会乱码。
因为获取的字符都是经过utf-8编码的,但是如果直接将其作为文件名,系统的编码模式并不是utf-8因此文件名会乱码,不过如果直接作为utf-8输入文件,则系统用记事本打开就不会乱码,因为记事本使用了utf-8编码,所以在这里先将获取的数据进行解码才能正常显示
代码如下:
filename=title.decode('utf-8')+'.txt'
self.file=open(filename,'a')
headers='该帖子标题是:'+title+'\n该帖子共有'+pageNum+'页\n'
self.file.write(headers)
倒数第三四行就是直接写入文件的数据,由于在程序开头已经指定了该程序的编码是utf-8,所以这里的文本数据写入并不会造成乱码。
#coding=utf-8
匹配到的网页数据当然直接写入文件即可,也不会乱码。