原文: 源码分析——客户端负载Netflix Ribbon
date: 2019-04-23 11:23:22
[TOC]
前言
Ribbon是由Netflix OSS开源的负载均衡组件
Spring Cloud将其整合作为客户端侧的(client-side)负载均衡组件, 以类库的形式集成于消费者客户端内
你在Spring Cloud整合Eureka, Feign, Zuul的组件中都可以见到它的影子
关于负载的作用与分类模式可以参考: 服务发现——需求与模式
在Netflix的场景中, Ribbon与Eureka都是作用在中间层的服务, 在终端接入侧的Edge Service负载仍然由亚马逊ELB服务提供
AWS 弹性负载均衡服务是边界服务的负载均衡解决方案,边界服务是向终端用户访问 Web 而开放的。
Eureka 填补了中间层负载均衡的空缺。
虽然,理论上可以将中间层服务直接挂在 AWS 弹性负载均衡器后面,但这样会将它们直接开放给外部世界,从而失去了 AWS 安全组的所有好处。
—— 摘自Netflix
目的
阅读源码的目为了解决以下几个疑问
- Ribbon获取到服务列表后是如何负载? 如何路由到目标服务的?
Ribbon中的负载均衡策略有哪些? —— 网上很多说明
- Ribbon是怎么获取/更新服务列表的?
- Ribbon的工作流程
- Spring RestTemplate是如何具备LB能力的, 它与Ribbon有什么联系
说明
版本:
Netflix Ribbon的源码依然是Servlet应用, 为了调试方便我还是在Spring Cloud的集成工程中, 源码仅作为参照方便查找
所以准确讲, 并不是单独分析, 而是Spring Cloud Netflix Ribbon
- Spring Cloud:
Finchley.SR2 - 对应Netflix Ribbon:
v2.2.5
$ git checkout -b v2.2.5 v2.2.5
名词:
- NIWS: Netflix Internal Web Service Framework
核心组件

the beans that Spring Cloud Netflix provides by default for Ribbon:
| Bean Type | Bean Name | Class Name (default) |
|---|---|---|
IClientConfig |
ribbonClientConfig |
DefaultClientConfigImpl |
IRule |
ribbonRule |
ZoneAvoidanceRule |
IPing |
ribbonPing |
DummyPing |
ServerList |
ribbonServerList |
ConfigurationBasedServerList |
ServerListFilter |
ribbonServerListFilter |
ZonePreferenceServerListFilter |
ILoadBalancer |
ribbonLoadBalancer |
ZoneAwareLoadBalancer |
ServerListUpdater |
ribbonServerListUpdater |
PollingServerListUpdater |
以上几个组件在源码分析过程会提到
Ribbon核心源码
调试代码
为了在方便调试源码, 我准备一个很简单的代码
@Autowired
private LoadBalancerClient loadBalancerClient;
public String getHello() {
RestTemplate restTemplate = new RestTemplate();
ServiceInstance serviceInstance = loadBalancerClient.choose("HELLO-SERVICE");
String url = "http://" + serviceInstance.getHost() + ":" + serviceInstance.getPort();
return restTemplate.getForObject(url, String.class);
}
路由 & 负载
LoadBalancerClient
RibbonLoadBalancerClient作为Ribbon负载逻辑的重要实现类, 看它之前, 先来看看它的接口声明
- 继承结构

-
接口定义
public interface LoadBalancerClient extends ServiceInstanceChooser {T execute(String serviceId, LoadBalancerRequest request) throws IOException; T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest request) throws IOException; URI reconstructURI(ServiceInstance instance, URI original); } public interface ServiceInstanceChooser { ServiceInstance choose(String serviceId); }
解释:
LoadBalancerClient
execute(): 两个重载方法根据服务实例(serviceInstance)执行请求-
reconstructURI(): 重构URI例如
http://cloudlink-user/priUser/getByIds重构为http://SC-201707142304:8802/priUser/getByIds
ServiceInstanceChooser
-
choose(String serviceId): 即依据LoadBalancer选择并返回服务ID对应的服务实例
源码中有比较详细的注释
显而易见RibbonLoadBalancerClient#choose是应该重点分析的方法
它调用了getServer()方法, 经过几个函数重载, 最终调用了ILoadBalancer中的实现
默认的实现其实是com.netflix.loadbalancer.ZoneAwareLoadBalancer#chooseServer
—— 参考配置类:
RibbonClientConfiguration#ribbonLoadBalancer
它是BaseLoadBalancer的子类, 因为我的环境只有一个可用区zone, 所以不会走区域相关的负载逻辑, 直接调用父类super.chooseServer(key), 即BaseLoadBalancer#chooseServer
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
return rule.choose(key); // look me !
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
IRule
接着上面的, 略过非重点代码, 看rule.choose(key)
其中的rule就是Ribbon中负载均衡策略的核心接口IRule , 对应前面核心组件中提到的Rule—负载均衡策略
接口定义如下:
public interface IRule{
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}
除了choose(), 接口ILoadBalancer中定义了负载均衡器中的操作方法
public interface ILoadBalancer {
public void addServers(List newServers);
public Server chooseServer(Object key);
public void markServerDown(Server server);
@Deprecated
public List getServerList(boolean availableOnly);
public List getReachableServers();
public List getAllServers();
}
IRule的抽象子类AbstractLoadBalancerRule中完成了ILoadBalancer的setter&getter
回到chooseServer()中, 作为BaseLoadBalancer类的成员变量, 默认值定义如下:
private final static IRule DEFAULT_RULE = new RoundRobinRule();
protected IRule rule = DEFAULT_RULE;
也就是默认的策略为轮询(RoundRobin)
看看其实现: com.netflix.loadbalancer.RoundRobinRule#choose(ILoadBalancer, Object), 代码省略...
可以看到在该方法中调用了ILoadBalancer#getAllServers获取到服务列表, 通过一个线程安全的计数算法从中取出一个活着的Server返回
-
继承结构
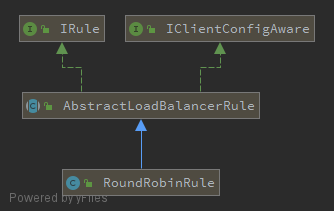 RoundRobinRule继承结构
RoundRobinRule继承结构
从源码中可以看到IRule的实现有很多很多, 对应多种负载均衡策略的种类
网上有针对每种策略的解释, 不说了
至此, 已经分析了Ribbon从多个服务中依据某种负载策略选择一个进行调用
回答了开头问题1: Ribbon获取到服务列表后是如何负载? 如何路由到目标服务的?
获取 & 更新服务
下面来分析问题2: Ribbon是怎么获取/更新服务列表的?
在consumer客户端进行第一次调用provider服务时, 能看到这样一行日志:
INFO c.n.l.DynamicServerListLoadBalancer : DynamicServerListLoadBalancer for client cloudlink-user initialized: DynamicServerListLoadBalancer:{
NFLoadBalancer:name=cloudlink-user,current list of Servers=[SC-201707142304:8801, SC-201707142304:8802],
...
}
日志中打印了服务提供者的信息
在源码中查看, 来自于com.netflix.loadbalancer.DynamicServerListLoadBalancer#restOfInit, 调用栈如下:
org.springframework.cloud.netflix.ribbon.RibbonClientConfiguration#ribbonLoadBalancer
↓
com.netflix.loadbalancer.ZoneAwareLoadBalancer#ZoneAwareLoadBalancer
↓
com.netflix.loadbalancer.DynamicServerListLoadBalancer#DynamicServerListLoadBalancer
↓
com.netflix.loadbalancer.DynamicServerListLoadBalancer#restOfInit
最后在restOfInit()中调用了updateListOfServers(), 从字面意思看, 它与获取服务实例有关
-
com.netflix.loadbalancer.DynamicServerListLoadBalancer#updateListOfServers@VisibleForTesting public void updateListOfServers() { Listservers = new ArrayList (); if (serverListImpl != null) { servers = serverListImpl.getUpdatedListOfServers(); // look me ! LOGGER.debug("List of Servers for {} obtained from Discovery client: {}", getIdentifier(), servers); if (filter != null) { servers = filter.getFilteredListOfServers(servers); LOGGER.debug("Filtered List of Servers for {} obtained from Discovery client: {}", getIdentifier(), servers); } } updateAllServerList(servers); }
从这段代码能够推断出两点:
- 获取到的服务集合信息
servers来自于ServerList的实现类 - ServerList接口中声明了获取服务列表的方法以及更新服务列表(30秒)的方法 —— 下面
其实从上面那行debug日志已经能够看出服务列表信息来自于服务发现客户端
我们只需要进入ServerList的实现类证明即可
ServerList
这里看到了Ribbon中的另一个核心组件: ServerList 即服务列表, 用于获取地址列表
在与Spring Cloud Eureka集成的服务中, 它是从注册中心拉取的并能够动态更新的服务列表清单
当然, 在捕鱼Eureka集成的情况下可以配制成静态的地址列表
public interface ServerList {
public List getInitialListOfServers();
/**
* Return updated list of servers. This is called say every 30 secs
* (configurable) by the Loadbalancer's Ping cycle
*
*/
public List getUpdatedListOfServers();
}
找到其实现: com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerList
可以看到以上两个方法的实现都调用了同一个方法obtainServersViaDiscovery()
代码很长, 简化一下大致如下:
List serverList = new ArrayList();
EurekaClient eurekaClient = eurekaClientProvider.get();
List instanceInfo = eurekaClient.getInstancesByVipAddress(vipAddress, isSecure, targetRegion);
serverList.add(new DiscoveryEnabledServer(instanceInfo););
还能看到在调用getUpdatedListOfServers()得到servers后, 并没有立即返回
而是又去执行了filter.getFilteredListOfServers(servers);过滤后返回
至此, 已经能够证明Ribbon获取服务提供者的信息来自于Eureka Server
ServerListFilter
Ribbon中另一个组件: ServerListFilter, 负责服务列表过滤
仅当使用动态ServerList时使用, 用于在原始的服务列表中使用一定策略过虑掉一部分地址
public interface ServerListFilter {
public List getFilteredListOfServers(List servers);
}
默认的过滤器为ZonePreferenceServerListFilter, 会过滤出同区域的服务实例, 也就是区域优先
从ServerListFilter的实现类可以找到, Netflix Ribbon中还提供了其它的过滤规则, 不说了
ServerListUpdater
在DynamicServerListLoadBalancer中可以看到ServerListUpdater的定义
protected final ServerListUpdater.UpdateAction updateAction =
new ServerListUpdater.UpdateAction() {
@Override
public void doUpdate() {
updateListOfServers();
}
};
protected volatile ServerListUpdater serverListUpdater;
它定义了服务列表ServerList的动态更新, 相当于一个服务更新器
- Implement 1(default): PollingServerListUpdater
- Implement 2: EurekaNotificationServerListUpdater
默认的动态更新策略为PollingServerListUpdater, 会执行一个定时任务, 源码中定义了默认执行周期为30s
IPing
接口定义中只有一个方法, 检测服务是否活着
public interface IPing {
public boolean isAlive(Server server);
}
在Ribbon中的默认实现为DummyPing, 也就是假Ping, 一直返回True
在与Eureka集成使用中, 默认实现为NIWSDiscoveryPing, 会根据服务实例的状态判断该实例是否活着:
// ...
InstanceStatus status = instanceInfo.getStatus();
if (status!=null){
isAlive = status.equals(InstanceStatus.UP);
}
return isAlive;
也是以定时任务周期执行, 源码可参考: com.netflix.loadbalancer.BaseLoadBalancer.PingTask
RestTemplate & LB
介绍
在Spring Cloud中的服务间通信场景, 除了可以使用声明式的REST客户端Feign, 也可以使用从Spring 3.0引入的RestTemplate
RestTemplate中封装了简单易用的API, 其实现默认是封装JDK原生的HTTP客户端URLConnection
如果你想替换实现为HttpClient, OkHttpClient, 加入对应的依赖和显示的配置即可, Spring Cloud已对其做好了自动配置
参考:
org.springframework.cloud.commons.httpclient.HttpClientConfiguration
例如替换为OkHttp3Client
-
pom依赖
com.squareup.okhttp3 okhttp 3.9.1 -
显示配置
@Bean @LoadBalanced public RestTemplate restTemplate() { RestTemplate restTemplate = new RestTemplate(); restTemplate.setRequestFactory(new OkHttp3ClientHttpRequestFactory()); return restTemplate; }
那么问题来了, 服务间的调用和正常HttpClient远程调用还是有区别的
RestTemplate是如何具备从多个服务中挑选一个进行路由的能力? 它和Ribbon有什么关系?
我们知道, 有了@LoadBalanced注释, RestTemplate才能通过逻辑服务名的方式进行调用, 否则会是UnknowHostException
所以猜想RestTemplate在某一步会被赋予客户端负载的能力
源码分析
在LoadBalanced同路径下, 可以看到如下两个类:
- LoadBalancerAutoConfiguration
- LoadBalancerInterceptor
关注如下代码:
public class LoadBalancerAutoConfiguration {
@LoadBalanced
@Autowired(required = false)
private List restTemplates = Collections.emptyList();
@Bean
public SmartInitializingSingleton loadBalancedRestTemplateInitializerDeprecated(
final ObjectProvider> restTemplateCustomizers) {
return () -> restTemplateCustomizers.ifAvailable(customizers -> {
for (RestTemplate restTemplate : LoadBalancerAutoConfiguration.this.restTemplates) {
for (RestTemplateCustomizer customizer : customizers) {
customizer.customize(restTemplate); // look me !
}
}
});
}
//...
static class LoadBalancerInterceptorConfig {
//...
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(final LoadBalancerInterceptor loadBalancerInterceptor) {
return restTemplate -> {
List list = new ArrayList<>(restTemplate.getInterceptors());
list.add(loadBalancerInterceptor); // look me !
restTemplate.setInterceptors(list);
};
}
}
}
其中最关键的就是restTemplate.setInterceptors(list)了, 为restTemplate添加了一个拦截器, 在发起HTTP请求时进行拦截
而拦截后要实现的功能肯定就是完成客户端负载, 进入该拦截器:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {
private LoadBalancerClient loadBalancer;
//...
@Override
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return this.loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution));
}
}
可以看到intercept方法内传入了serviceName, request, 最终调用了LoadBalancerClient#execute()
-
其中host取到的是URL中填写的服务名
e.g.
http://cloudlink-user/priUser/getByIds中服务名为cloudlink-user 服务名serviceName取的是host
那接下来就是根据serviceName, 根据负载找到一个服务实例进行路由, 又回到上面的 路由&负载 过程啦
我们使用中都要使用@Bean对其初始化, 确保在启动时就初始化, 如果new一个, 用一段代码来简化手动模拟, 就是这个样子
@Autowired
private LoadBalancerClient loadBalancerClient;
public List method() {
RestTemplate restTemplate = new RestTemplate();
List interceptors = restTemplate.getInterceptors();
interceptors.add(new LoadBalancerInterceptor(loadBalancerClient));
restTemplate.setInterceptors(interceptors);
return restTemplate.postForObject("http://cloudlink-user/priUser/getByIds", userIds, List.class);
}
总结
源码没有很深入, 仅仅为了了解Ribbon工作流程和其中一些细节
整个流程还是比较清晰, 按照顺序大致分为:
- 获取服务列表信息
- 执行定时任务动态更新/检查/剔除服务
- 对获取到的服务列表进行过滤
- 按照负载均衡策略在多个服务中选择一个服务进行调用
从中也能看出, 在服务实例发生变化时, Consumer端并不能立刻感知到, 而是有一定的延迟, 可能会继续调用而报错
与Eureka相同, 再次看出CAP中保证了AP而适当牺牲C, 所以无论是服务网关路由到我们的服务, 还是服务消费者调用提供者.
作为Eureka Client调用侧, 尽可能的加入一定重试. 通过配置可以实现这一点