摘要:
二叉查找树(Binary Search Tree)是一种用于快速查找、插入和删除数据的二叉树结构,虽然二叉查找树的平衡性无法保持时会存在退化为链表,时间复杂度增高的情况,但在某些方面二叉查找树还是保持一定的优势。
二叉树进化——二叉查找树
二叉查找树与二叉树在「二叉」两个字上讲述了其血缘关系,两者在外形上并没有本质的区别,但是二叉查找树对具体数据的存储位置进行了处理,形成了自己的规则。我们都知道,一个二叉树节点会拥有最多两个子节点,以左子节点为基础形成的树是「左子树」,以右子节点为基础形成的树是「右子树」,二叉查找树规定了当前节点的左子树存储比当前节点小的数值,右子树存储比当前节点大的数值,于是一组数据被当前节点分成了两部分。
[图片上传失败...(image-617f90-1569162236932)]
二叉查找树的基本操作
有二叉树基础知识的情况下二叉查找树的理解起来比较简单,不过因为其对数据存储的特别规则,它的基本操作会出现一些变化。
查找
二叉查找树的查找操作是指查找具体某个值的节点,因为二叉查找树的数据存储比较规律,我们完全可以按照这个规律查找相应数据。当需要查找具体某个值的节点时从树的根节点开始查找,如果目标数值比当前节点的数值小,那该节点肯定存储在当前节点的左子树,相反就是存储在当前节点的右子树,如果当前节点数值与目标数值相等,那么恭喜你已经找到需要的节点。
[图片上传失败...(image-a3bbd0-1569162236932)]
代码实现
public Node search(int num) {
Node curr = root;
while (curr != null) {
if (num < curr.value) {
curr = curr.left;
} else if (num > curr.value) {
curr = curr.right;
} else {
break;
}
}
return curr;
}
插入
二叉查找树的插入比较有特点,插入的节点不会插足某两个父子关系的节点之间,而是会按照二叉查找树数据的存储规则找到一个空地(也就是对应位置上无节点),然后住下来,也就是说插入的节点必然会成为叶子节点。
[图片上传失败...(image-77c619-1569162236932)]
代码实现
public void insert(int num) {
if (root == null) {
root = new Node(num);
return;
}
Node curr = root;
while (curr != null) {
if (num < curr.value) {
if (curr.left == null) {
curr.left = new Node(num);
break;
}
curr = curr.left;
} else {
if (curr.right == null) {
curr.right = new Node(num);
break;
}
curr = curr.right;
}
}
}
删除
单纯删除节点比较简单,但二叉查找树存储数据有自己的规则,在删除节点的同时需要保持规则不被破坏,事情会变得复杂,再加上被删除的节点会存在不同的情况,所以删除操作比插入和查找操作较为复杂。被删除的节点会存在是叶子节点,有一个子节点和有两个子节点这三种情况,接下来分别描述一下不同情况下的节点需要如何删除。
叶子节点
删除叶子节点比较简单,只需要将被删除节点的父节点对应的子节点置为空即可。例如被删除节点是其父节点的左子节点,那就将父节点的左子节点置为空值。
[图片上传失败...(image-2f0c23-1569162236932)]
有一个子节点
如果被删除节点有一个子节点,在删除节点后需要将其父节点的对应子节点替换为被删除节点的子节点。例如被删除节点是其父节点的左子节点,被删除节点有一个右子节点,删除该节点时只需将其父节点的左子节点置为被删除节点的右子节点。因为无论是被删除节点的左子节点还是右子节点,都是被删除节点在其父节点上的对应子树中的节点。
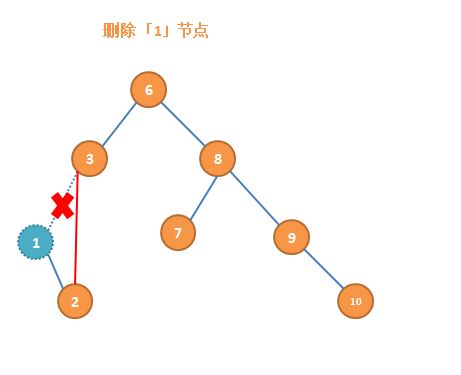
有两个子节点
如果被删除节点有两个子节点时,当该节点被删除而又不破坏二叉查找树的数据存储规则,只能寻找一个能够用来替换此位置的节点,而此节点需要满足比左子树所有的节点值大,而比右子树中的所有节点值都小。比被删除节点左子树所有节点值都大的节点肯定存储在其右子树中,而比右子树中所有值都小的节点便是右子树的最小值节点,所以在删除一个有两个子节点的节点时,需要将其右子树中的最小值节点替换此节点,右子树中最小值节点被用来替换被删除节点,那最小值节点应该从原来的位置上被删除,最小值节点要不就是叶子节点,要不就只有右子树,所以可以适用于前两条删除规则。
[图片上传失败...(image-4e481a-1569162236932)]
代码实现
public void delete(int num) {
Node curr = root;
Node pNode = null;
while (curr != null) {
if (num < curr.value) {
pNode = curr;
curr = curr.left;
} else if (num > curr.value) {
pNode = curr;
curr = curr.right;
} else {
break;
}
}
if (curr == null) {
return;
}
if (curr.isLeaf()) {
deleteNode(curr, pNode, null);
} else if (curr.left != null && curr.right != null) {
Node minNode = findMinFromNode(curr.right);
delete(minNode.value);
minNode.left = curr.left;
minNode.right = curr.right;
deleteNode(curr, pNode, minNode);
} else if (curr.left != null) {
deleteNode(curr, pNode, curr.left);
} else {
deleteNode(curr, pNode, curr.right);
}
}
private void deleteNode(Node curr, Node pNode, Node replaceNode) {
if (pNode == null) {
root = replaceNode;
} else if (pNode.left == curr) {
pNode.left = replaceNode;
} else {
pNode.right = replaceNode;
}
}
private Node findMinFromNode(Node node) {
Node curr = node;
while (curr != null && curr.left != null) {
curr = curr.left;
}
return curr;
}
排序
一般的数据结构都是讲述查找、插入和删除操作即可,为什么二叉查找树需要把排序单独拿出来作为基本操作说明?因为二叉查找树在排序上比较特别,虽然根据二叉查找树规则存储的数据节点看起来并无顺序,但通过中序遍历就可以获得顺序的数据,所以从某种意义上来讲二叉查找树的数据是顺序存储的。
public String sortedPrint() {
List nodes = new ArrayList<>();
sortedNodes(root, nodes);
StringBuffer print = new StringBuffer();
for (int i = 0; ; i++) {
print.append(nodes.get(i).value);
if (i > nodes.size() - 2) {
break;
}
print.append(",");
}
return print.toString();
}
private void sortedNodes(Node node, List sortedNodes) {
if (node == null) {
return;
}
sortedNodes(node.left, sortedNodes);
sortedNodes.add(node);
sortedNodes(node.right, sortedNodes);
}
如果节点值相同
前面我们分析的二叉查找树都是以每个节点值不重复为基础的,但现实生产中重复值的出现往往无法避免,如果遇到重复值时需要如何处理?在二叉查找树中,如果插入的节点值与树中的某个节点值相等,插入的节点值会当作大于值的节点处理,插入到相同值节点的右子树中。
既然插入已经定下重复值节点的规则,那查找也按照此规则进行即可,查找到目标值节点时并不停止,而是继续查找,直到叶子节点终止,这样就可以把所有满足目标值的节点都查找到。删除操作建立在查找操作基础上,查找操作已经把所有的目标节点获得,接下来按照上文所说删除规则将所有节点删除即可。
时间复杂度分析
二叉查找树与链表有个很相似的地方,插入和删除操作都是基于查找操作的,而单纯来看插入和删除操作时间复杂度都是常量级 ,所以这三个操作的时间复杂度只需要分析查找的时间复杂度即可。
因为树有多种情况,先来看极度不平衡的情况,如果树中所有的节点都只有左子节点,那树就退化为链表,时间复杂度是 ;看完了极度不平衡的情况我们来分析理想情况下树的时间复杂度,所谓树的理想情况就是完全二叉树或者满二叉树。查找操作的时间消耗与递归深度是正比关系,而此操作中的递归深度最大时与树的高度一致,所以查找操作的时间消耗与树高度成正比关系,时间复杂度的分析转换为了对树高度的计算,那一棵树的高度是多少?
理想情况下的树我们可以按照完全二叉树进行计算,完全二叉树除最后一层外其他层属于满节点情况,假设该树总共有 n 个节点,能够构成树的高度为 k,因为高度等于层数减一,所以树的层数总共有 k + 1 层。由于是完全二叉树,除最后一层外都是保持满节点状态,从第一层至倒数第二层的节点个数依次为 ,根据等比数列公式求和,第一至 k 层总共有 个节点,完全二叉树最后一层的节点在 至 个之间,所以 ,转换计算后可得 ,二叉查找树的时间复杂度为 。
这种情况是在理想,也就是二叉查找树能够保持平衡的情况下计算得到的时间复杂度,但实际情况中如此理想的平衡状态需要加入干预才能保持,那种解决了平衡问题的二叉查找树就能够使时间复杂度稳定在
散列表 VS 二叉查找树
散列表也有查找、插入和删除操作,并且时间复杂度是 ,如此高效的情况下为什么还需要二叉查找树?
- 散列函数,散列冲突等带来的问题
虽然散列的时间复杂度是 ,但散列函数的计算,散列冲突的开放寻址,达到装载因子阀值时的扩容、缩容进行的数据搬运,这些操作的耗时加起来不一定比 小,而且这些问题在设计散列表的时候就是需要考虑的问题,而二叉查找树只需要考虑解决平衡的问题即可,换句话说二叉查找树比散列表需要考虑更少的问题,而且平衡问题的解决在业界是有比较成熟的方案的。
- 空间的浪费
由于散列表存在装载因子以控制散列冲突的恶化,这表示散列表中永远会保持有一部分存储空间是空闲状态,这导致了散列表的存储空间浪费问题。
- 无序的散列表
散列表对数据的散列计算使其拥有了快速查找和存储数据的能力,但也牺牲了数据的有序性,而二叉查找树的中序遍历便可以保证数据的有序性。
总结
二叉查找树是基于二叉树的数据存储方式,利用较大值存储右子树,较小值存储左子树的方式提高效率,查找、插入和删除在理想情况下时间复杂度为 ,使用中序遍历可以有序输出数据,但其也存在无法保证平衡性情况下退化为链表的可能。
文章中如有问题欢迎留言指正
本章节代码已经上传GitHub,可点击跳转查看代码详情。
数据结构与算法之美笔记系列将会做为我对王争老师此专栏的学习笔记,如想了解更多王争老师专栏的详情请到极客时间自行搜索。